In this chapter, we'll convert a simple HTML file to a PDF document in many different ways. The content of the HTML file will consist of a "Test" header, a "Hello World" paragraph, and an image representing the iText logo.
Structure of the examples
All the examples throughout this book will have a similar structure.
INPUT:
For the input, we'll provide HTML syntax. In this tutorial, we'll use an HTML String, a path to an HTML file, or – in chapter 4 – a path to an XML file along with the path to an XSLT file to convert the XML to HTML.
In the first example, C01E01_HelloWorld.java, the HTML is provided as a String:
public String HTML = "<h1>Test</h1><p>Hello World</p>";
In other examples, such as C01E03_HelloWorld.java, we'll use two constants:
-
a
BASEURIconstant for the path to the parent folder where to find the source HTML and resources such as images and CSS, and -
a
SRCconstant with the path to that source HTML file.
For instance:
public static String BASEURI = "src/main/resources/html/";
public static String SRC = String.format("%shello.html", BASEURI);
public static String BASEURI = "src/main/resources/html/";
public static String SRC = String.Format("{0}hello.html", BASEURI);
OUTPUT:
We'll use a similar structure for the output:
-
a
TARGETconstant for the path to the folder to which we'll write the resulting PDF, and -
a
DESTconstant with the path to that PDF.
For instance:
public static String TARGET = "target/results/ch01/";
public static String DEST = String.format("%stest-03.pdf", TARGET);
public static String TARGET = "target/results/ch01/";
public static String DEST = String.Format("{0}test-03.pdf", TARGET);
MAIN METHOD:
The main method of all the examples in this book won't differ much from the method of our first example:
public static void main(String[] args) throws IOException {
LicenseKey.loadLicenseFile(
System.getenv("ITEXT7_LICENSEKEY") + "/itextkey-html2pdf_typography.xml");
File file = new File(TARGET);
file.mkdirs();
new C01E01_HelloWorld().createPdf(HTML, DEST);
}
static void Main(string[] args)
{
LicenseKey.LoadLicenseFile(
Environment.GetEnvironmentVariable("ITEXT-7_LICENSEKEY") + "\\itextkey-html2pdf_typography.xml"
);
Directory.CreateDirectory(BASEURI);
new C01E01_HelloWorld().createPdf(HTML, DEST);
}
First we load the iText license file. This is an XML file containing a license key for using iText. You might not need this license key if you are using iText and pdfHTML in the context of an AGPL project. However, you will need the pdfCalligraph add-on for the internationalization examples in chapter 6, and the pdfCalligraph add-on isn't available under the AGPL; it's a closed source add-on only.
The license key we are using in the examples of this book is similar to the key you will get if you purchase a commercial license to use iText 7, pdfHTML, and pdfCalligraph in a closed source context. Note that as of iText 7.2 our license key files now use the JSON format rather than XML. For more clarification you can refer to the license key and license key library installation guide.
Then we create the target directory in case it doesn't exist yet, followed by the createPdf()/CreatePdf() method. We can implement this methods in many different ways.
Converting HTML to PDF
The implementation of the createPdf()/CreatePdf() method of the C01E01_HelloWorld.java example is very simple. Its body consists of a single line:
public void createPdf(String html, String dest) throws IOException {
HtmlConverter.convertToPdf(html, new FileOutputStream(dest));
}
public void createPdf(string html, string dest)
{
HtmlConverter.ConvertToPdf(html, new FileStream(dest, FileMode.Create));
}
The HtmlConverter object has a selection of different static convertToPdf()/ConvertToPdf() methods that take different parameters depending on the use case. In the first example, the first parameter html is a String with the following value:
public static String HTML = "<h1>Test</h1><p>Hello World</p>";
This HTML snippet is converted to the PDF document that is shown in figure 1.1.
Let's introduce an image, and use the following String:
public static String HTML =
"<h1>Test</h1><p>Hello World</p><img src=\"img/logo.png\">";
This HTML snippet contains a relative link to the image file logo.png in a subdirectory named img. It's impossible for iText to guess where to look for this subdirectory, hence we'll configure the base URI for the conversion process.
This is done using the ConverterProperties (Java/.NET) object, as shown in the createPdf()/CreatePdf() method of the C01E02_HelloWorld.java example.
public void createPdf(String baseUri, String html, String dest) throws IOException {
ConverterProperties properties = new ConverterProperties();
properties.setBaseUri(baseUri);
HtmlConverter.convertToPdf(html, new FileOutputStream(dest), properties);
}
public void createPdf(string baseUri, string html, string dest)
{
ConverterProperties properties = new ConverterProperties();
properties.SetBaseUri(baseUri);
HtmlConverter.ConvertToPdf(html, new FileStream(dest, FileMode.Create), properties);
}
We create a ConverterProperties (Java/.NET) object, and we set the base URI to the parent directory of the img directory where iText can find the logo.png file.
Figure 1.2 shows the result.

In most of the examples that follow, we won't use HTML stored in a String. Instead, we are going to convert an HTML file on disk into a file on disk.
For the rest of the examples in this chapter, we'll use the file named hello.html shown in figure 1.3.
There are different ways to convert this file to a PDF document.
In the C01E03_HelloWorld.java example, we use File / FileInfo objects:
public void createPdf(String baseUri, String src, String dest) throws IOException {
HtmlConverter.convertToPdf(new File(src), new File(dest));
}
public void createPdf(string src, string dest)
{
HtmlConverter.ConvertToPdf(new FileInfo(src), new FileInfo(dest));
}
The first parameter of the convertToPdf()/ConvertToPdf() method refers to the source HTML file, the second parameter to the destination PDF file. In this case, we don't need to set any converter properties. By default, iText will use the parent directory of this file as the base URI.
This doesn't work for the C01E04_HelloWorld.java example where we use FileInputStream/FileStream and FileOutputStream/FileStream objects instead of File/FileInfo objects:
public void createPdf(String baseUri, String src, String dest) throws IOException {
ConverterProperties properties = new ConverterProperties();
properties.setBaseUri(baseUri);
HtmlConverter.convertToPdf(
new FileInputStream(src), new FileOutputStream(dest), properties);
}
public void createPdf(string baseUri, string src, string dest)
{
ConverterProperties properties = new ConverterProperties();
properties.SetBaseUri(baseUri);
HtmlConverter.ConvertToPdf(new FileStream(src, FileMode.Open), new FileStream(dest, FileMode.Create));
}
You can't retrieve a parent here, hence we need to pass a base URI to the converter using a ConverterProperties (Java/.NET) instance. The resulting PDFs of this third and fourth example look identical to the resulting PDF of the second example shown in figure 1.2. So does the resulting PDF of the fifth example, C01E05_HelloWorld.java:
public void createPdf(String baseUri, String src, String dest) throws IOException {
ConverterProperties properties = new ConverterProperties();
properties.setBaseUri(baseUri);
PdfWriter writer = new PdfWriter(dest,
new WriterProperties().setFullCompressionMode(true));
HtmlConverter.convertToPdf(new FileInputStream(src), writer, properties);
}
public void createPdf(string baseUri, string src, string dest)
{
ConverterProperties properties = new ConverterProperties();
properties.SetBaseUri(baseUri);
PdfWriter writer = new PdfWriter(dest,
new WriterProperties().SetFullCompressionMode(true));
HtmlConverter.ConvertToPdf(new FileStream(src, FileMode.Open), writer, properties);
}
In this case, we use a PdfWriter (Java/.NET) instance instead of a FileOutputStream/FileStream. Using a PdfWriter (Java/.NET) can be useful if you want to set certain writer properties.
For more information on writer properties, please read Chapter 7 of the iText Core: Building Blocks tutorial, entitled "Handling events; setting viewer preferences and printer properties."
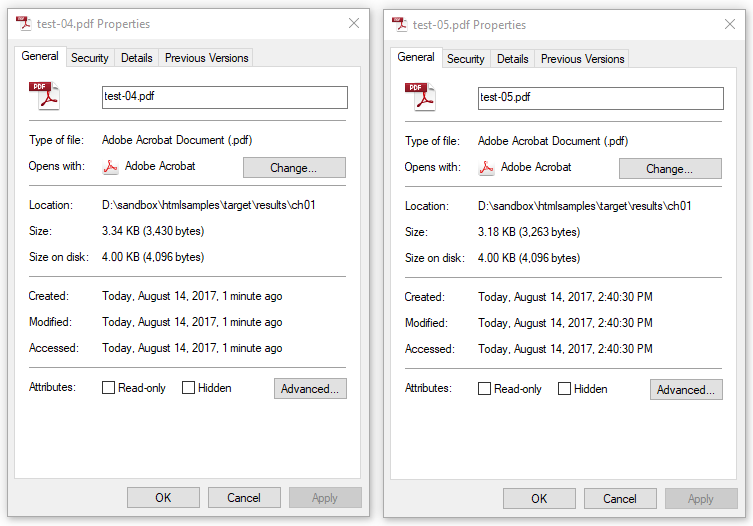
In this example, we create the PDF in full compression mode. To the human eye, the resulting PDF looks identical, but when you compare the file size of the PDF generated in example 4 with the file size of the PDF generated in this example, you see that full compression won us a handful of bytes.
Figure 1.4 shows 3,430 bytes when using compression as was done in PDF 1.0 to PDF 1.4; whereas the file only counts 3,263 bytes when using compression as introduced in PDF 1.5. That difference might seem small, but the more objects your PDF has, the more sense it makes to use full compression.
In the C01E06_HelloWorld.java example, we've replaced the PdfWriter (Java/.NET) parameter with a PdfDocument (Java/.NET) parameter.
public void createPdf(String baseUri, String src, String dest) throws IOException {
ConverterProperties properties = new ConverterProperties();
properties.setBaseUri(baseUri);
PdfWriter writer = new PdfWriter(dest);
PdfDocument pdf = new PdfDocument(writer);
pdf.setTagged();
HtmlConverter.convertToPdf(new FileInputStream(src), pdf, properties);
}
public void createPdf(string baseUri, string src, string dest)
{
ConverterProperties properties = new ConverterProperties();
properties.SetBaseUri(baseUri);
PdfWriter writer = new PdfWriter(dest);
PdfDocument pdf = new PdfDocument(writer);
pdf.SetTagged();
HtmlConverter.ConvertToPdf(new FileStream(src, FileMode.Open), pdf, properties);
}
Using a PdfDocument (Java/.NET) instance makes sense if you want to configure a feature at the PdfDocument (Java/.NET) level. In this case, we introduce the line pdf.setTagged()/pdf.SetTagged(), which instructs iText to create a Tagged PDF.
Figure 1.5 shows the resulting PDF with the Tags panel opened.
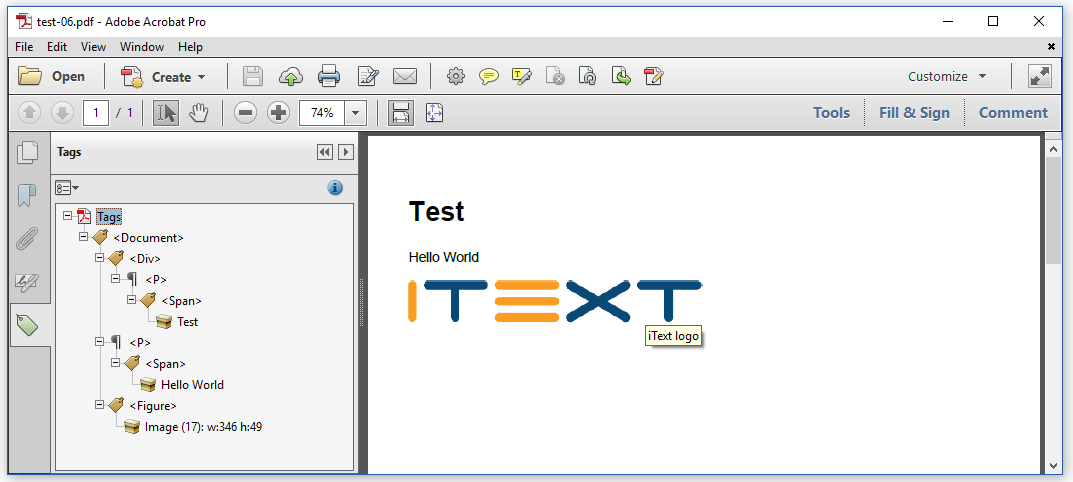
Looking at the Tags panel, you can see the structure of the content. When hovering over the image, you see the value of the alt attribute of the <img> tag as a tooltip.
We'll dive deeper into Tagged PDF and making PDFs "accessible" in chapter 3.
Converting HTML to iText objects
The convertToPdf()/ConvertToPdf() methods create a complete PDF file. Any File, FileInfo, OutputStream, PdfWriter (Java/.NET), or PdfDocument (Java/.NET) that is passed to the convertToPdf()/ConvertToPdf() method is closed once the input is parsed and converted to PDF. This might not always be what you want.
In some cases, you want to add some extra information to the Document(Java/.NET), or maybe you don't want to convert the HTML to a PDF file, but to a series of iText objects you can use for a different purpose. That's what the convertToDocument()/ConvertToDocument() and convertToElements()/ConvertToElements() methods are about.
In the C01E07_HelloWorld.java example, we convert our Hello World HTML to a Document (Java/.NET) because we want to add some extra content after we've done parsing the HTML:
public void createPdf(String baseUri, String src, String dest) throws IOException {
ConverterProperties properties = new ConverterProperties();
properties.setBaseUri(baseUri);
PdfWriter writer = new PdfWriter(dest);
PdfDocument pdf = new PdfDocument(writer);
Document document =
HtmlConverter.convertToDocument(new FileInputStream(src), pdf, properties);
document.add(new Paragraph("Goodbye!"));
document.close();
}
public void createPdf(string baseUri, string src, string dest)
{
ConverterProperties properties = new ConverterProperties();
properties.SetBaseUri(baseUri);
PdfWriter writer = new PdfWriter(dest);
PdfDocument pdf = new PdfDocument(writer);
Document document = HtmlConverter.ConvertToDocument(new FileStream(src, FileMode.Open), pdf, properties);
document.Add(new Paragraph("Goodbye!"));
document.Close();
}
The convertToDocument()/ConvertToDocument() method returns an iText Document (Java/.NET) instance. We use this Document (Java/.NET) instance to add some extra content ("Goodbye!") after the HTML has been parsed.

The upper part of the content in figure 1.6 was added by parsing HTML to PDF; the lower part – the "Goodbye!" at the end – was added using a document.add()/document.Add() instruction.
In the C01E08_HelloWorld.java example, we use the convertToElements()/ConvertToElements() method. This method creates a List of IElementobjects. The IElement interface is implemented by all the iText building blocks.
For more info about iText's building blocks, please read the iText Core: Building Blocks tutorial.
This last example of chapter 1 adds every top-level object of the List<IElement>/IList collection to a Document(Java/.NET), preceded by a Paragraph that shows the name of that object:
public void createPdf(String baseUri, String src, String dest) throws IOException {
ConverterProperties properties = new ConverterProperties();
properties.setBaseUri(baseUri);
List<IElement> elements =
HtmlConverter.convertToElements(new FileInputStream(src), properties);
PdfDocument pdf = new PdfDocument(new PdfWriter(dest));
Document document = new Document(pdf);
for (IElement element : elements) {
document.add(new Paragraph(element.getClass().getName()));
document.add((IBlockElement)element);
}
document.close();
}
public void createPdf(string baseUri, string src, string dest)
{
ConverterProperties properties = new ConverterProperties();
properties.SetBaseUri(baseUri);
IList elements = HtmlConverter.ConvertToElements(new FileStream(src, FileMode.Open), properties);
PdfDocument pdf = new PdfDocument(new PdfWriter(dest));
Document document = new Document(pdf);
foreach (IElement element in elements)
{
document.Add(new Paragraph(element.ToString()));
document.Add((IBlockElement) element);
}
document.Close();
}
Looking at figure 1.7, we see that the list consisted of three elements: one Div and two Paragraph (Java/.NET) objects.
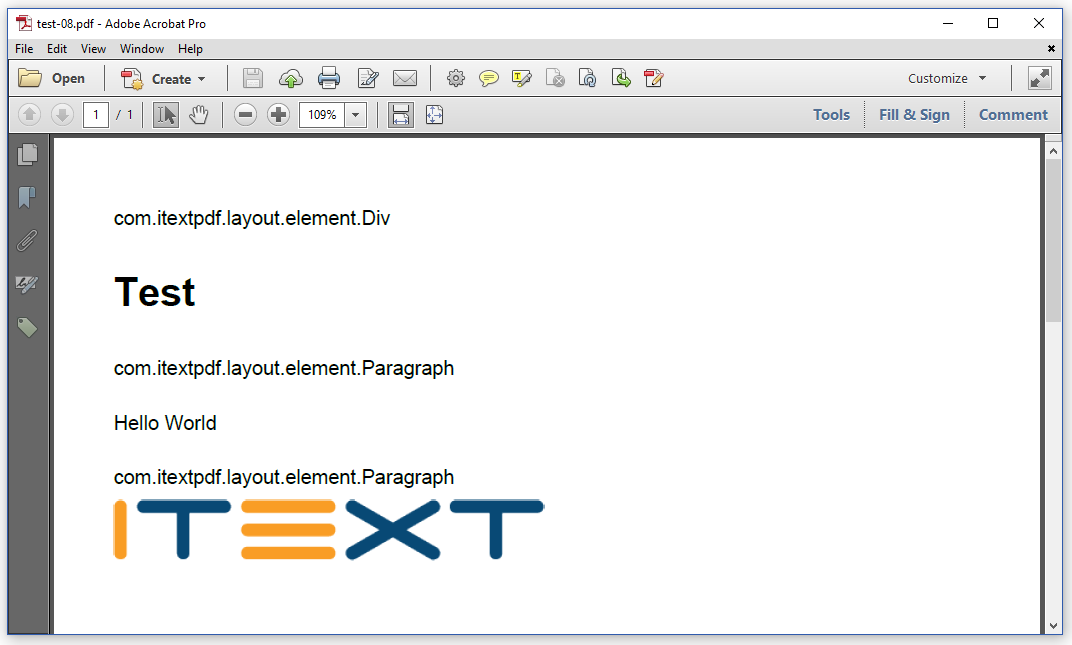
The header is treated as a Div, whereas the logo image is wrapped inside a Paragraph (Java/.NET). Don't worry about this; this is part of the inner workings of iText. It's the end result that matters.
Summary
In this chapter, we've taken one very simple HTML file, and we've converted that file to PDF using different implementations of the conversion methods convertToPdf()/ConvertToPdf(), convertToDocument()/ConvertToDocument() and convertToElements()/ConvertToElements() . When you consult the API documentation for the HtmlConverter class (Java/.NET), you'll discover some more variations on those methods. In the next chapter, we'll pick one of those methods to convert different HTML files. Each of these HTML files will use CSS in a different way.