Roughly speaking, there are three major ways to create PDF documents using iText,
-
You can create a PDF document from scratch using iText objects such as
Paragraph(Java/.NET),Table(Java/.NET),Cell(Java/.NET),List(Java/.NET)... The advantage of this approach is that everything is programmable, hence configurable just the way you want it. The disadvantage is that you need to program everything; even small changes such as changing one color into another, require a developer to change the Java code of the application, to recompile the code, etc. -
You can fill out a pre-existing form. On one side, there is AcroForm technology, which is fast and easy, but not dynamic (all fields have fixed positions). On the other side, you have the XML Forms Architecture (XFA), which is dynamic, filling out the form is easy, but the form creation is complex, and XFA is deprecated since PDF 2.0.
-
You can convert HTML and CSS to PDF using pdfHTML. This is easy because everyone knows some HTML, and everyone knows some CSS. Why would you create a template in another (proprietary?) format? Just create the content in HTML, then convert that content to PDF with pdfHTML using CSS for the definition of the styles.
This tutorial discusses this third approach, which is ideal when you have to create documents of a certain type, for instance catalogues, invoices, etc.
Description of a use case
Assume that you are a service provider in the business of creating invoices for different customers. All of these invoices share a similar structure regardless of the customer, but every customer wants you to use different fonts, different colors, a different layout. If you use the first approach, you'll have to write Java code every time a new customer signs up. If you use the second approach, you'll discover that you soon hit the limitations of the existing forms technology in PDF. If you use pdfHTML, you can build a system that requires a minimum of programming, and that doesn't take much effort to sign up a new customer.
When a new customer signs up, you need:
-
To get the data in such a way that it can easily be used to populate your HTML,
-
To get information about fonts, colors, layout,... in the form of a CSS file,
-
To get a single-page PDF document that can serve as company stationery.
In this chapter, we'll work with an XML file, movies.xml, containing data that will be presented in different ways using different XSLT transformations.
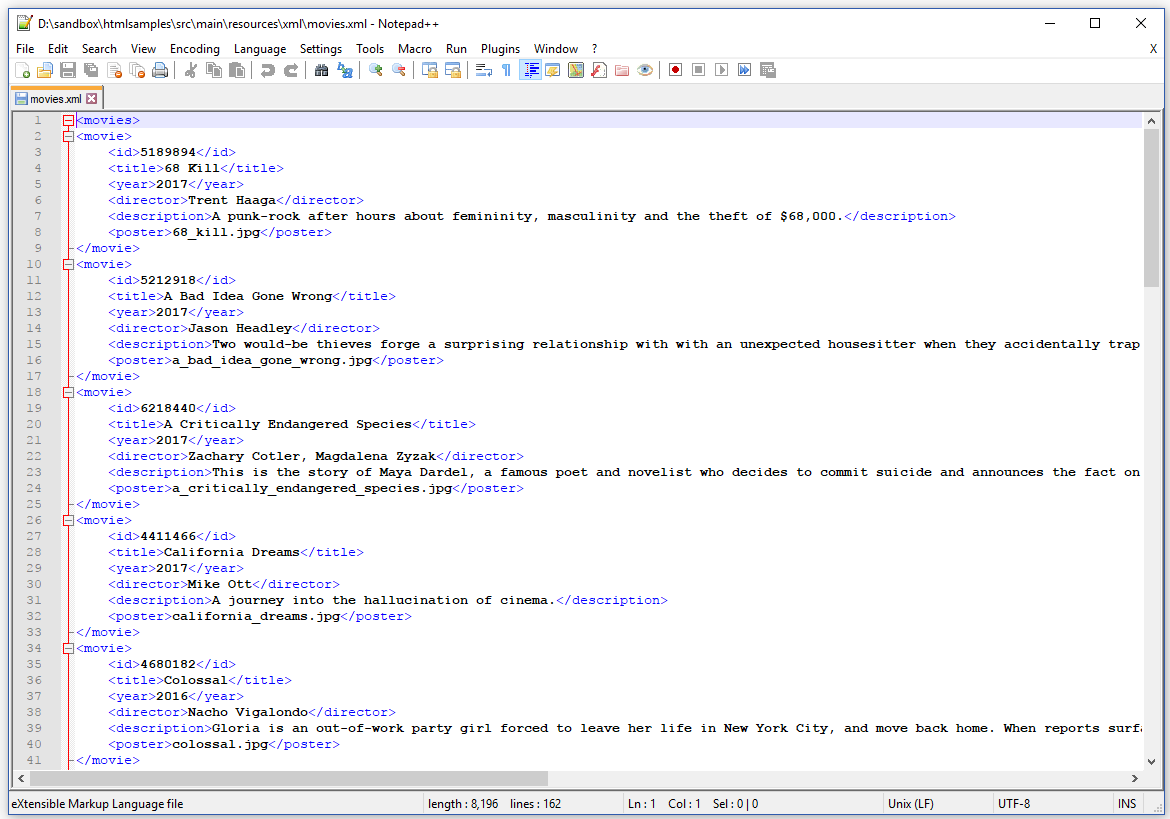
Figure 4.1 shows that the root element of this XML file is called <movies>, and that the XML file consists of a series of <movie> tags containing information about a movie, such as the IMDB id (<id>), a title (<title>), the year in which the movie was produced (<year>), the director (<director>), a description <description>, and the file name of the movie poster (<poster>).
We'll use this XML file for all the examples in this chapter, but the resulting PDFs will be quite different.
Converting XML to HTML using XSLT
In a first series of examples, we are going to use an XSL transformation that converts the XML into an HTML files consisting of one large table.
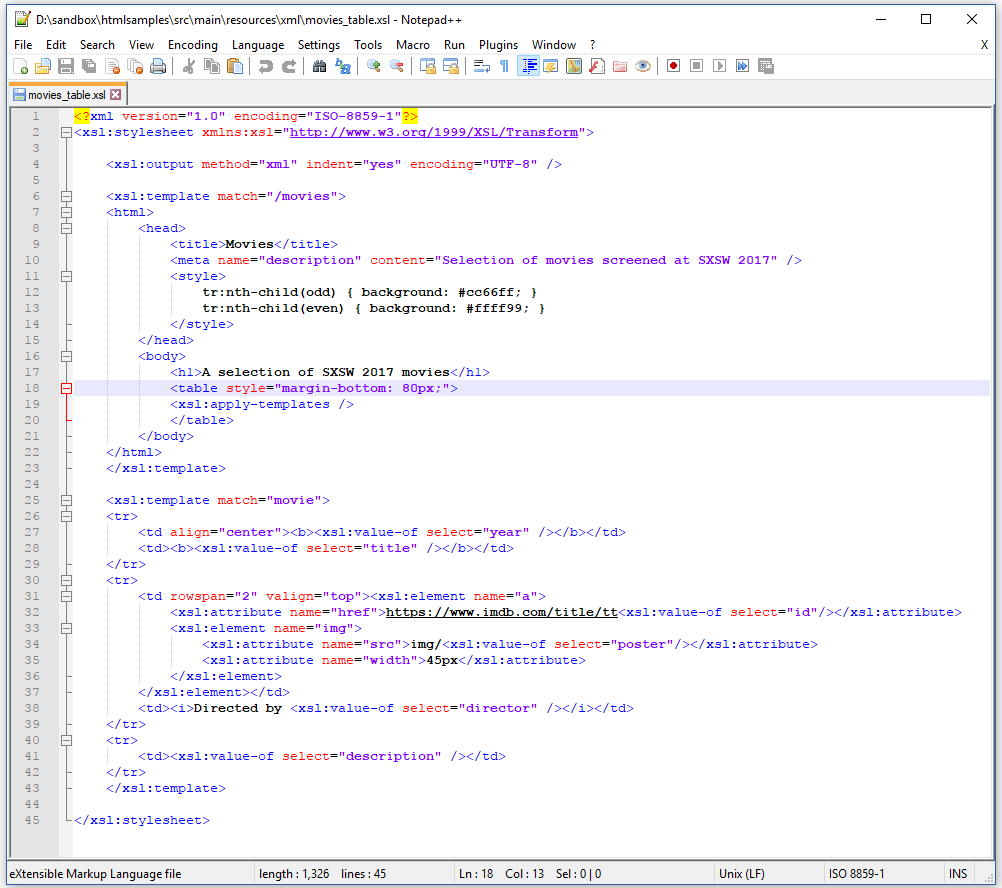
When we examine the movies_table.xsl XSLT code in figure 4.2, we recognize the structure of an HTML page that will match the <movies> root element. We define a <table> object, and we use apply-templates which will, in this case, generate two rows for every <movie> tag. These rows will be populated with the movie data.
We don't use any external CSS, but there is some internal CSS in which we define pseudo-classes for the rows. Every odd row (tr:nth-child(odd)) will have #cc66ff as background color; every even row (tr:nth-child(even)) will have #ffff99 as background-color.
The result, shown in figure 4.3, is quite colorful – I apologize if it hurts the eyes, but remember that this is just an example to demonstrate the functionality.
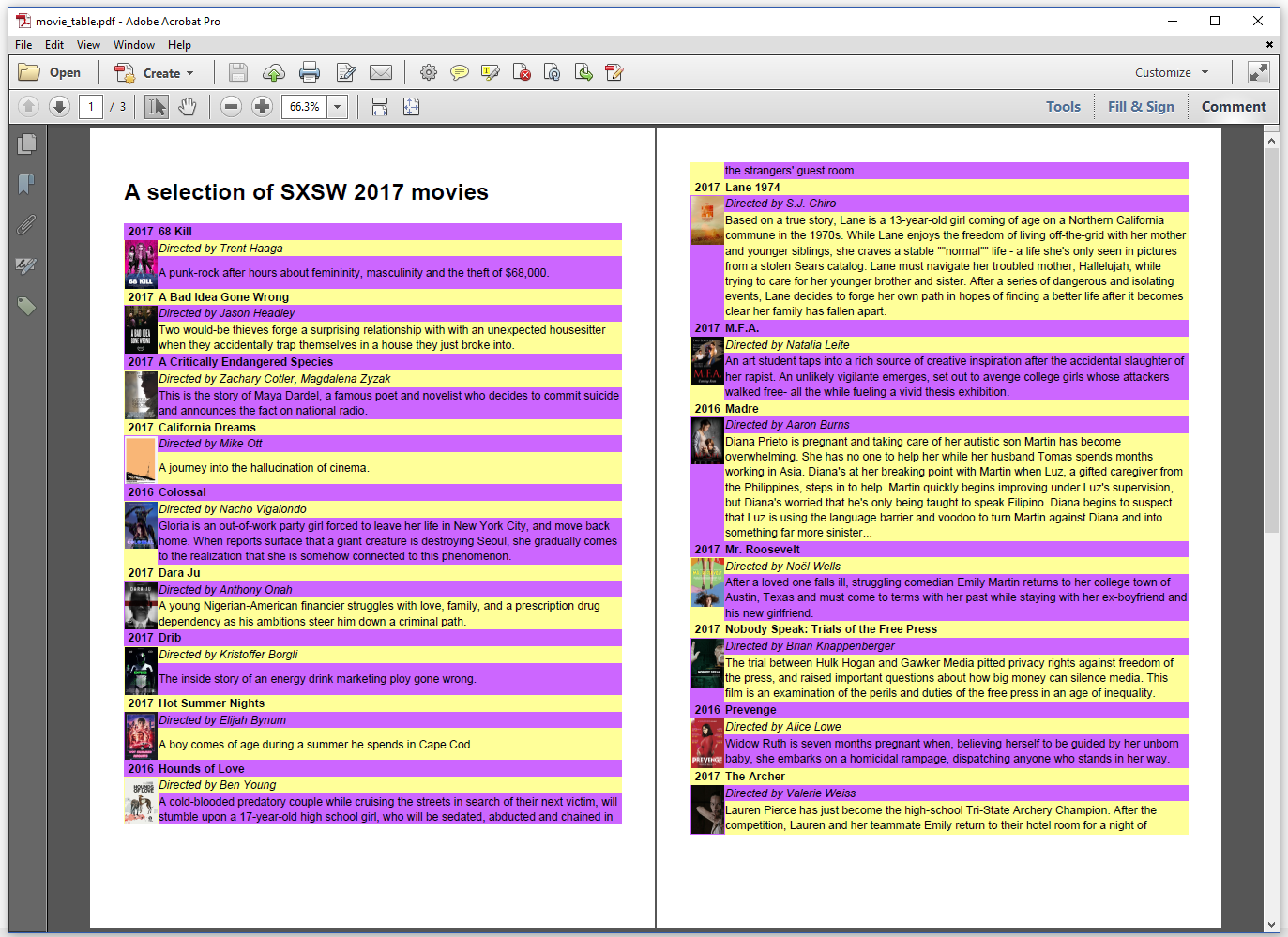
We call the createPdf() method of the C04E01 MovieTable.java like this:
app.createPdf(app.createHtml(XML, XSL), BASEURI, DEST);
We don't store the HTML on disk; the method below creates the HTML file in memory:
public byte[] createHtml(String xmlPath, String xslPath)
throws IOException, TransformerException {
ByteArrayOutputStream baos = new ByteArrayOutputStream();
Writer writer = new OutputStreamWriter(baos);
StreamSource xml = new StreamSource(new File(xmlPath));
StreamSource xsl = new StreamSource(new File(xslPath));
TransformerFactory factory = TransformerFactory.newInstance();
Transformer transformer = factory.newTransformer(xsl);
transformer.transform(xml, new StreamResult(writer));
writer.flush();
writer.close();
return baos.toByteArray();
}
public byte[] CreateHtml()
{
MemoryStream ms = new MemoryStream();
StreamWriter writer = new StreamWriter(ms);
XslCompiledTransform transformer = new XslCompiledTransform();
XmlReader xslReader = XmlReader.Create(BASEURI + ".xsl");
XmlReader xmlReader = XmlReader.Create(BASEURI + ".xml");
transformer.Load(xslReader);
transformer.Transform(xmlReader, null, writer);
xmlReader.Close();
xslReader.Close();
ms.Close();
writer.Close();
return ms.ToArray();
}
We pass the HTML bytes:
public void createPdf(byte[] html, String baseUri, String dest) throws IOException {
ConverterProperties properties = new ConverterProperties();
properties.setBaseUri(baseUri);
HtmlConverter.convertToPdf(
new ByteArrayInputStream(html), new FileOutputStream(dest), properties);
}
public void CreatePdf()
{
ConverterProperties properties = new ConverterProperties();
properties.SetBaseUri(BASEURI);
HtmlConverter.ConvertToPdf(new MemoryStream(CreateHtml()), new FileStream(DEST, FileMode.Create),
properties);
}
We use ConverterProperties (Java/.NET) so that the links to the images can be resolved.
We'll reuse the createHtml()/CreateHtmlBytes() method in all the other examples of this chapter. For instance in the next example where we'll introduce company stationery as a background image.
Adding a background and a custom header or footer
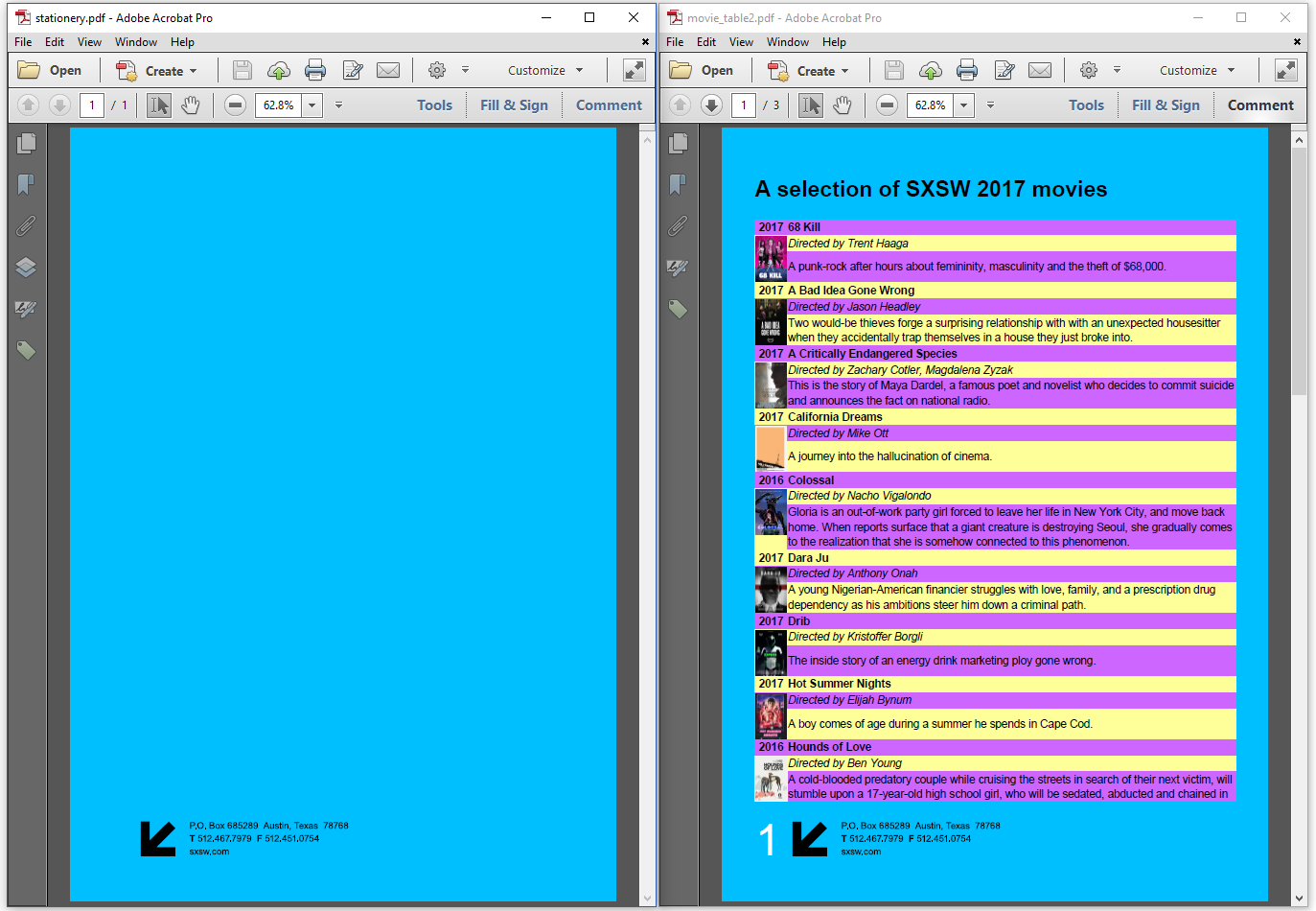
Suppose that we have a single-page PDF document that can be used as company stationery – see the PDF on the left in figure 4.4. Suppose that we want to add this single page in the background of the PDF we are creating from HTML –see the PDF on the right. Suppose that we also want to add page numbers in a way that is not supported by the @page at-rule. See for instance the large, white number 1 on the first page of the resulting PDF.
Chapter 7 of the iText Core: Building Blocks tutorial explains how you can meet these requirements. You can achieve this by using an event handler.
In the C04E02 MovieTable2.java example, we create an IEventHandler (Java/.NET) implementation, named Background:
class Background implements IEventHandler {
PdfXObject stationery;
public Background(PdfDocument pdf, String src) throws IOException {
PdfDocument template = new PdfDocument(new PdfReader(src));
PdfPage page = template.getPage(1);
stationery = page.copyAsFormXObject(pdf);
template.close();
}
@Override
public void handleEvent(Event event) {
PdfDocumentEvent docEvent = (PdfDocumentEvent) event;
PdfDocument pdf = docEvent.getDocument();
PdfPage page = docEvent.getPage();
PdfCanvas pdfCanvas = new PdfCanvas(
page.newContentStreamBefore(), page.getResources(), pdf);
pdfCanvas.addXObject(stationery, 0, 0);
Rectangle rect = new Rectangle(36, 32, 36, 64);
Canvas canvas = new Canvas(pdfCanvas, pdf, rect);
canvas.add(
new Paragraph(String.valueOf(pdf.getNumberOfPages()))
.setFontSize(48).setFontColor(Color.WHITE));
canvas.close();
}
}
class BackGround : IEventHandler
{
private PdfXObject stationery;
public BackGround(PdfDocument pdf, string src)
{
PdfDocument template = new PdfDocument(new PdfReader(src));
PdfPage page = template.GetPage(1);
stationery = page.CopyAsFormXObject(pdf);
template.Close();
}
public void HandleEvent(Event @event)
{
PdfDocumentEvent docEvent = (PdfDocumentEvent) @event;
PdfDocument pdf = docEvent.GetDocument();
PdfPage page = docEvent.GetPage();
PdfCanvas pdfCanvas = new PdfCanvas(page.NewContentStreamBefore(), page.GetResources(), pdf);
pdfCanvas.AddXObject(stationery, 0, 0);
Rectangle rect = new Rectangle(36, 32, 36, 64);
Canvas canvas = new Canvas(pdfCanvas, pdf, rect);
canvas.Add(new Paragraph(pdf.GetNumberOfPages().ToString())
.SetFontSize(48).SetFontColor(ColorConstants.WHITE));
canvas.Close();
}
}
We can create an instance of the Background class using the following parameters (line 4):
-
a
PdfDocument(Java/.NET) instance of the document we are creating,pdf, and -
the path to the source of the single-page PDF,
src.
In this constructor, we read the single-page PDF into another PdfDocument (Java/.NET) instance, named template. We get the first page of this template, and we copy this page to the pdf instance as a Form XObject. This Form XObject is stored as a member-variable, stationery. Finally, we close the template.
When an event is triggered, that event is handled by the handleEvent() / HandleEvent() method, which we override. We get a PdfCanvas (Java/.NET) object for the current page in the current PDF document. We want to get access to a canvas that will be drawn before anything else is drawn on the page. That's what newContentStreamBefore()/NewContentStreamBefore(). We add the stationery Form XObject to the page at coordinates [ x=0, y=0 ] . The addXObject() method adds the single page we imported in the constructor to the current page as its background.
To add the page number, we first define a location, and we create a high-level Canvas (Java/.NET) object using the low-level PdfCanvas (Java/.NET) instance. To this canvas, we add the current number of pages as a Paragraph (Java/.NET) with 48pt as font size and white as text color.
When will this event be triggered? That's defined in the createPdf() method:
public void createPdf(byte[] html, String baseUri, String stationery, String dest)
throws IOException {
ConverterProperties properties = new ConverterProperties();
properties.setBaseUri(baseUri);
PdfWriter writer = new PdfWriter(dest);
PdfDocument pdf = new PdfDocument(writer);
IEventHandler handler = new Background(pdf, stationery);
pdf.addEventHandler(PdfDocumentEvent.START_PAGE, handler);
HtmlConverter.convertToPdf(new ByteArrayInputStream(html), pdf, properties);
}
public void CreatePdf(byte[] html, string baseUri, string stationery, string dest)
{
ConverterProperties properties = new ConverterProperties();
PdfWriter writer = new PdfWriter(dest);
PdfDocument pdf = new PdfDocument(writer);
properties.SetBaseUri(baseUri);
IEventHandler handler = new BackGround(pdf, stationery);
pdf.AddEventHandler(PdfDocumentEvent.START_PAGE, handler);
HtmlConverter.ConvertToPdf(new MemoryStream(html), pdf, properties);
}
We create an instance of the Background class, named handler. We add this instance to the PdfDocument (Java/.NET) using the addEventHandler()/AddEventHandler() method. With the PdfDocumentEvent.START_PAGE (Java/.NET) parameter, we indicate that the handleEvent() / HandleEvent() method needs to be invoked every time a page starts. In this case, the method will be called three times, because the content is distributed over three pages.
If we'd look at the HTML file in a browser, we'd see one long page. When we render the same content to a PDF with page size A4, we have three pages. But what if we want to put all the content on one PDF page?
For example: some companies run a cron job that takes a snapshot of specific web pages every hour, every day, every month. It's not their intention to print this page; these companies just want an archive that allows them to know which content was online on a specific day at a specific hour.
How could they make sure that the PDF always consists of a single page of which the size is adapted to the size of the content?
Converting an HTML page to a single-page PDF
Figure 4.5 shows the same content we used for the previous examples on one long page measuring 8.26 x 26.29in.
We chose the width of the document ourselves - it's the width of an A4 page. But how do we determine the length of the page?
We can't determine the length in advance, because we only know the total height after all the content has been rendered. In the C04E03 MovieTable3.java example, we create a PDF with an initial page size of 595 x 14400 user units.
The height of 14,400 user units isn't chosen arbitrarily; it's an implementation limit of Adobe Acrobat and Adobe Reader. You can create a PDF with a page size greater than 14,400 user units in width or height, but Adobe Reader won't be able to render it. You'll only see a blank page.
We'll use the convertToDocument() / ConvertToDocument() method to create a Document (Java/.NET) instance. We'll use a trick to get the end position after rendering the content. We'll then change the page size so that it's reduced to the size of the content.
The createPdf()/CreatePdf() method shows us how this is done.
public void createPdf(byte[] html, String baseUri, String dest)
throws IOException {
ConverterProperties properties = new ConverterProperties();
properties.setBaseUri(baseUri);
PdfWriter writer = new PdfWriter(dest);
PdfDocument pdf = new PdfDocument(writer);
pdf.setDefaultPageSize(new PageSize(595, 14400));
Document document = HtmlConverter.convertToDocument(
new ByteArrayInputStream(html), pdf, properties);
EndPosition endPosition = new EndPosition();
LineSeparator separator = new LineSeparator(endPosition);
document.add(separator);
document.getRenderer().close();
PdfPage page = pdf.getPage(1);
float y = endPosition.getY() - 36;
page.setMediaBox(new Rectangle(0, y, 595, 14400 - y));
document.close();
}
public void CreatePdf(byte[] html, string baseUri, string dest)
{
ConverterProperties properties = new ConverterProperties();
PdfWriter writer = new PdfWriter(dest);
PdfDocument pdf = new PdfDocument(writer);
properties.SetBaseUri(baseUri);
pdf.SetDefaultPageSize(new PageSize(595, 14400));
Document document = HtmlConverter.ConvertToDocument(new MemoryStream(html), pdf, properties);
EndPosition endPosition = new EndPosition();
LineSeparator separator = new LineSeparator(endPosition);
document.Add(separator);
document.GetRenderer().Close();
PdfPage page = pdf.GetPage(1);
float y = endPosition.GetY() - 36;
page.SetMediaBox(new Rectangle(0, y, 595, 14400 - y));
document.Close();
}
We set the extraordinary page size, and we convert the HTML to a Document (Java/.NET) instance, we create an instance of the EndPosition class. We'll pass this instance to a LineSeparator (Java/.NET), and we'll add this separator to the Document (Java/.NET). This will cause all the content to be rendered, including the line separator.
We then get the page object of the first page, assuming that this is the only page in the document. This will be true as long as the required space is lower than 14,400.
Finally, we get the Y-value of the end position, and we use this y value to change the page size of the first page. After changing this page size, we close the document.
What happened here? We added a LineSeparator (Java/.NET), but when we look at the resulting PDF, we don't see any line. That's because we created an ILineDrawer (Java/.NET) implementation that doesn't draw anything. Instead, we use the ILineDrawer (Java/.NET) to get the Y-coordinate of the end of the content.
Let's take a look at the EndPosition class to see how this works:
class EndPosition implements ILineDrawer {
protected float y;
public float getY() {
return y;
}
@Override
public void draw(PdfCanvas pdfCanvas, Rectangle rect) {
this.y = rect.getY();
}
@Override
public Color getColor() {
return null;
}
@Override
public float getLineWidth() {
return 0;
}
@Override
public void setColor(Color color) {
}
@Override
public void setLineWidth(float lineWidth) {
}
}
class EndPosition : ILineDrawer
{
protected float y;
public void Draw(PdfCanvas canvas, Rectangle rect)
{
this.y = rect.GetY();
}
public float GetY()
{
return y;
}
public float GetLineWidth()
{
return 0;
}
public Color GetColor()
{
return null;
}
public void SetColor(Color color)
{
}
public void SetLineWidth(float lineWidth)
{
}
}
We override all the methods of the ILineDrawer (Java/.NET) interface, but only one method is important to us: the draw() / Draw() method. This method gives us a Rectangle (Java/.NET) instance that marks the current position of the cursor in the PDF at the moment the LineSeparator (Java/.NET) is to be rendered. We don't draw anything at this position. Instead, we retrieve the Y-coordinate, which we store in a member-variable. After the LineSeparator (Java/.NET) has been "rendered", we can retrieve this Y-position using the getY()/GetY() method.
In the next example, we'll use a different XSLT file to create a different view on the data. We'll also introduce bookmarks.
Adding bookmarks to a report
Figure 4.6 shows a PDF with the same content we had before, but organized in a slightly different way because we now used the movies_overview.xsl file to transform the XML to HTML.
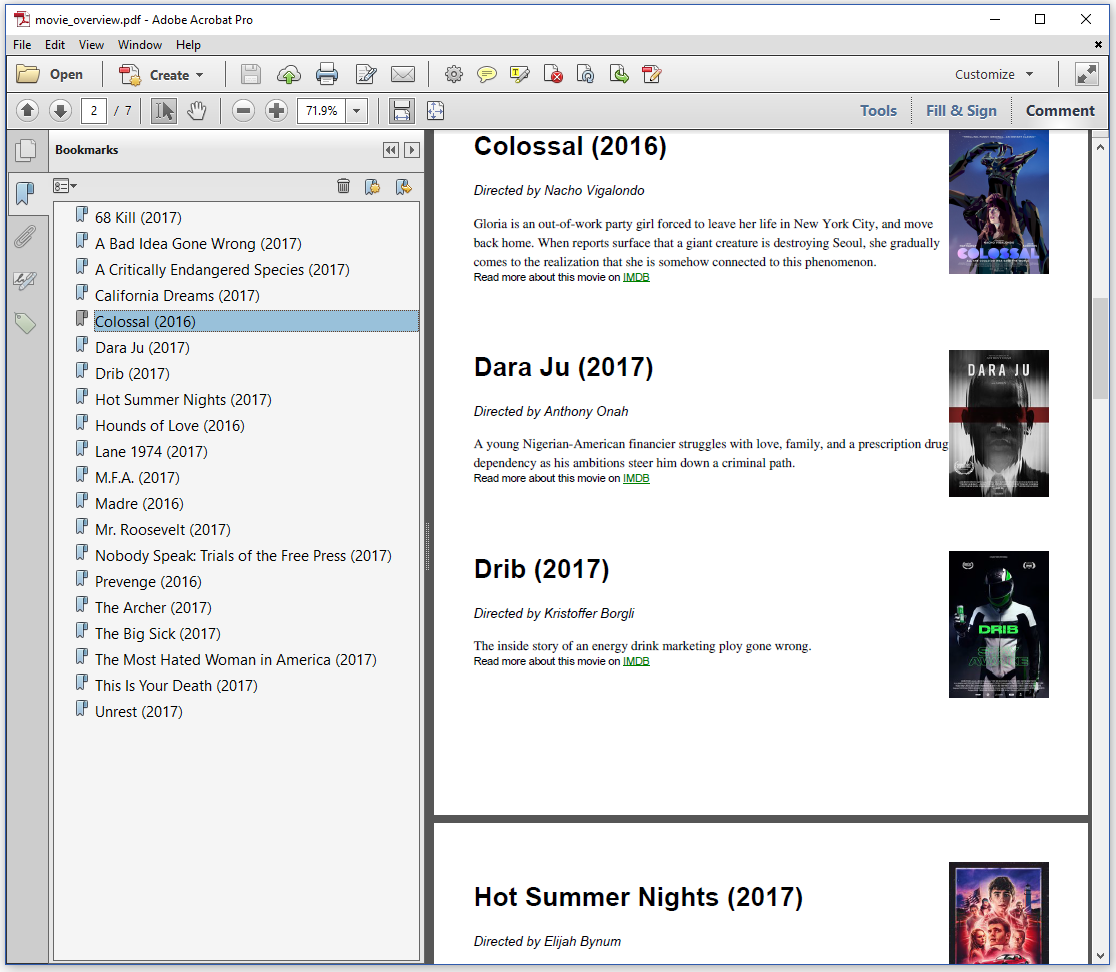
Observe that the resulting PDF document has bookmarks. When we click on the title of a movie, we jump to the location in the document where we can find more information about this movie.
The C04E04_MovieOverview.java example shows why these bookmarks were added.
public void createPdf(byte[] html, String baseUri, String dest) throws IOException {
ConverterProperties properties = new ConverterProperties();
properties.setBaseUri(baseUri);
OutlineHandler outlineHandler = OutlineHandler.createStandardHandler();
properties.setOutlineHandler(outlineHandler);
HtmlConverter.convertToPdf(
new ByteArrayInputStream(html), new FileOutputStream(dest), properties);
}
public void CreatePdf(byte[] html, string baseUri, string dest)
{
ConverterProperties properties = new ConverterProperties();
PdfWriter writer = new PdfWriter(dest);
PdfDocument pdf = new PdfDocument(writer);
OutlineHandler outlineHandler = OutlineHandler.CreateStandardHandler();
properties.SetOutlineHandler(outlineHandler);
properties.SetBaseUri(baseUri);
HtmlConverter.ConvertToPdf(new MemoryStream(html), new FileStream(dest, FileMode.Create), properties);
}
Creating bookmarks - or outlines as they are called in the PDF standard - is done by creating an OutlineHandler (Java/.NET), and passing this outline handler to the ConverterProperties (Java/.NET).
In this example, we used the createStandardHandler() / CreateStandardHandler() method to create a standard handler. In practice, this means that pdfHTML will look for <h1> , <h2> , <h3> , <h4> , <h5> , and <h6> . The bookmarks will be created based on the hierarchy of those tags in the HTML file. In the movie overview we created, we only have <h1> tags. That explains why the book marks are only one level deep.
We can also create a custom OutlineHandler (Java/.NET).
In figure 4.7, we see a second level of bookmarks consisting of the names of the directors of each movie.
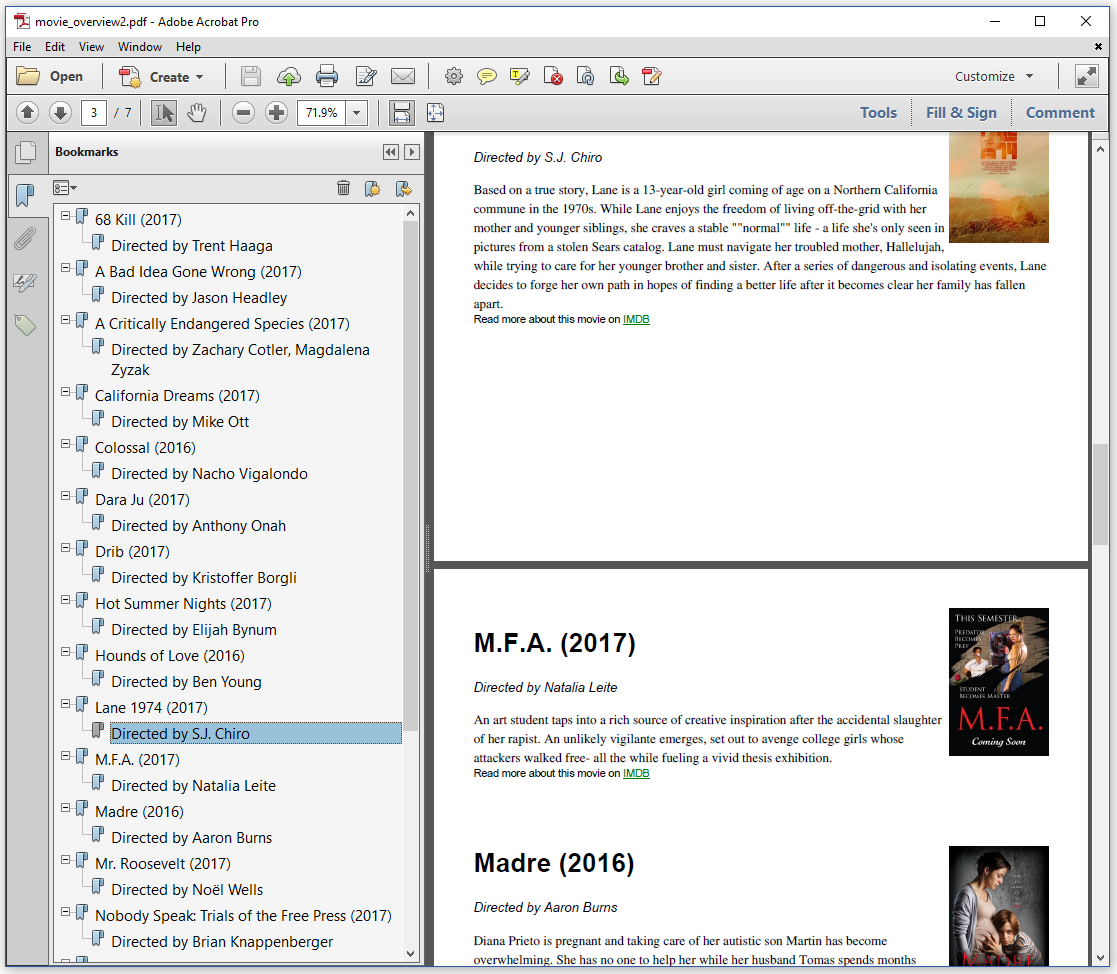
The directors of each movie were added to the overview using <p> tags, whereas the rest of the info was added using <div> tags. Knowing this, we can create a custom OutlineHandler (Java/.NET) that looks for <h1> and <p> tags when creating the outlines. This is done in the C04E05 MovieOverview2.java example.
public void createPdf(byte[] html, String baseUri, String dest)
throws IOException {
ConverterProperties properties = new ConverterProperties();
properties.setBaseUri(baseUri);
OutlineHandler outlineHandler = new OutlineHandler();
outlineHandler.putTagPriorityMapping("h1", 1);
outlineHandler.putTagPriorityMapping("p", 2);
properties.setOutlineHandler(outlineHandler);
HtmlConverter.convertToPdf(
new ByteArrayInputStream(html), new FileOutputStream(dest), properties);
}
public void CreatePdf(byte[] html, string baseUri, string dest)
{
ConverterProperties properties = new ConverterProperties();
OutlineHandler outlineHandler = new OutlineHandler();
outlineHandler.PutTagPriorityMapping("h1", 1);
outlineHandler.PutTagPriorityMapping("p", 2);
properties.SetBaseUri(baseUri);
properties.SetOutlineHandler(outlineHandler);
HtmlConverter.ConvertToPdf(new MemoryStream(html), new FileStream(dest, FileMode.Create), properties);
}
In this createPdf()/CreatePdf() method, we create a new OutlineHandler (Java/.NET), and we add tag priorities for the <h1>-tag (priority 1) and the <p>-tag (priority 2). Should we have <h2>, <h3>, or any other tag in our HTML, then those tags would be ignored when creating the outline tree.
In the next set of examples, we are going to create some invoices. In many countries, the law requires companies to archive invoices for a certain number of years. There is a subset of PDF called PDF/A where the A stands for Archiving. PDF/A is the format you need for the long-term preservation of documents. When creating invoices, it's considered best practices to create then in the PDF/A format.
Creating PDF/A documents with pdfHTML
Figure 4.8 shows a PDF invoice in the PDF/A-2B format. It was created from the same XML we used for the previous examples in this chapter, but with a different XSLT file, movies_invoice.xsl.
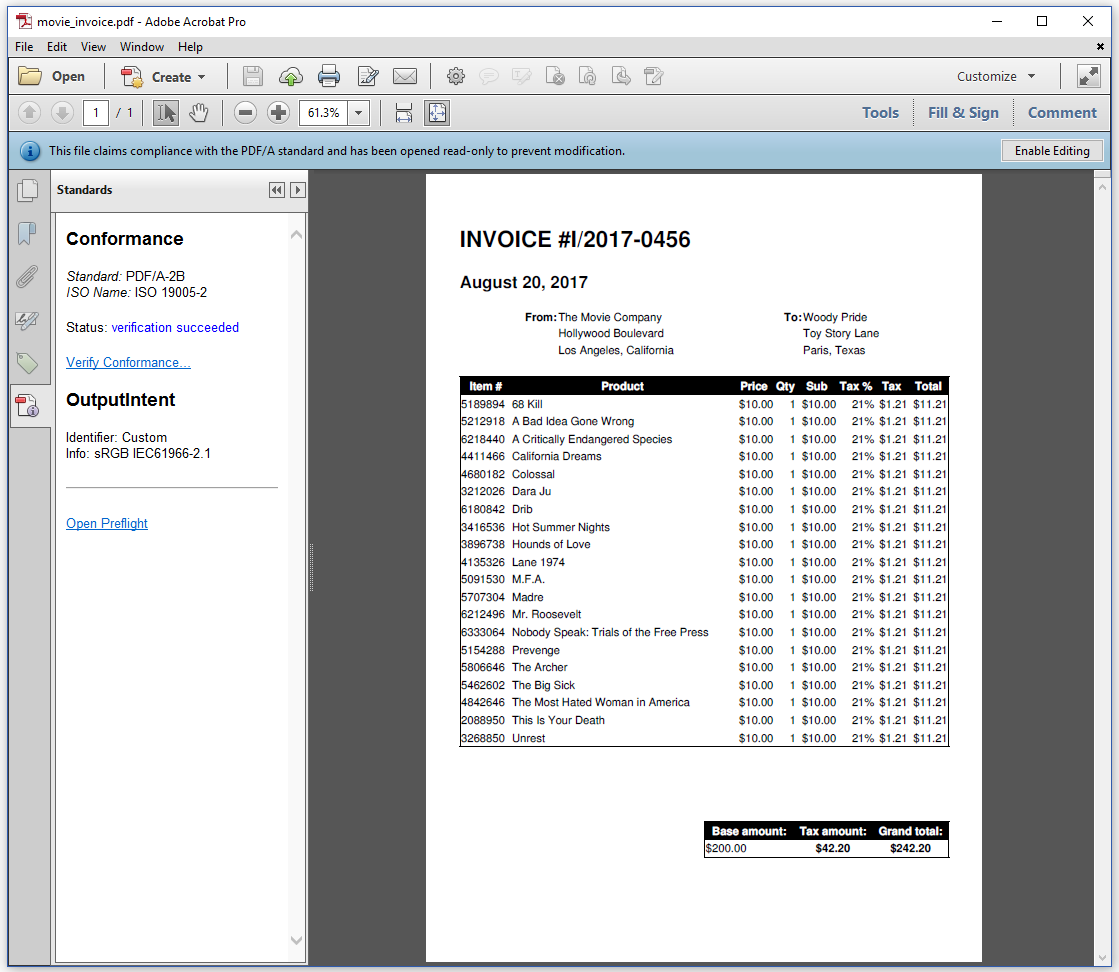
PDF/A is also known as the ISO 19005 standard. It's a subset of ISO 32000 defining a set of obligations and restrictions. For instance:
-
There is the obligation for the file to contain metadata in the eXtensible Metadata Platform (XMP) format described in ISO 16684,
-
You need to add the correct color profile to the file, so that there are no ambiguities about colors,
-
The document must be self-contained: all fonts need to be embedded, no external movie, sound or other binary files are allowed, and so on.
-
JavaScript is not allowed, nor is encryption.
There are currently three parts of this standard. Approved parts will never become invalid. New parts are created to define new, useful features.
-
PDF/A-1 dates from 2005. It's based on PDF 1.4, and it defines two levels: B is the "basic" level that ensures the preservation of the visual appearance; A is the "Accessible" level which adds the requirement for the PDF to be tagged on top of the requirements for Level B.
-
PDF/A-2 dates from 2011. It's based on ISO 32000-1, and it adds some features to PDF/A-1 that were introduced in PDF 1.5, 1.6, and 1.7, such as support for JPEG2000, collections, object-level XMP, and optional content. There's also improved support for transparency, comment types and annotations, and digital signatures. It defines three levels: the "basic" level B; the "accessible" level A; and the "unicode" level U. Level U is similar to Level B, but with the extra requirement that all text needs to be stored in Unicode.
-
PDF/A-3 dates from 2012. It's identical to PDF/A-2 with one major difference: in PDF/A-2 all attachments need to be PDF documents that compliant with the PDF/A-1 or PDF/A-2 standard; in PDF/A-3, all kinds of attachments are allowed (regular PDF files, XML, docx, xslx,...).
Aside from the different layout we used to create a document that looks like an invoice, we had to make an important change to the HTML that relates to PDF/A. In the movies_invoice.xsl XSLT file, we define a font in the -tag: .
As we'll see in chapter 6, FreeSans is a font that is shipped with pdfHTML and that is always embedded, as opposed to the default font Helvetica - which is the font that was used in the previous examples. Embedding all fonts is one of the requirements of PDF/A.
Let's take a look at the createPdf()/CreatePdf() method of the C04E06_MovieInvoice.java example to see what else is different:
public void createPdf(byte[] html, String baseUri, String dest, String intent) throws IOException {
PdfWriter writer = new PdfWriter(dest);
PdfADocument pdf = new PdfADocument(writer,
PdfAConformanceLevel.PDF_A_2B,
new PdfOutputIntent("Custom", "", "https://www.color.org",
"sRGB IEC61966-2.1", new FileInputStream(intent)));
ConverterProperties properties = new ConverterProperties();
properties.setBaseUri(baseUri);
HtmlConverter.convertToPdf(new ByteArrayInputStream(html), pdf, properties);
}
public void CreatePdf(byte[] html, string baseUri, string dest, string intent)
{
PdfWriter writer = new PdfWriter(dest);
ConverterProperties properties = new ConverterProperties();
PdfADocument pdf = new PdfADocument(writer, PdfAConformanceLevel.PDF_A_2B, new PdfOutputIntent("Custom", "",
"https://www.color.org", "sRGB IEC61966-2.1", new FileStream(intent, FileMode.Open)));
properties.SetBaseUri(baseUri);
HtmlConverter.ConvertToPdf(new MemoryStream(html), pdf, properties);
}
The only difference with the previous examples, is that we now use a PdfADocument (Java/.NET) instead of merely a PdfDocument (Java/.NET). We add the PdfAConformanceLevel (Java/.NET) -in this case PDF_A_2B (Java/.NET) for PDF/A-2B conformance- as a parameter for the constructor, and we pass the color profile using a PdfOutputIntent (Java/.NET) object.
Creating a PDF/A-2A file only requires two minor changes. See the C04E07_MovieInvoice2.java example:
public void createPdf(byte[] html, String baseUri, String dest, String intent)
throws IOException {
PdfWriter writer = new PdfWriter(dest);
PdfADocument pdf = new PdfADocument(writer,
PdfAConformanceLevel.PDF_A_2A,
new PdfOutputIntent("Custom", "", "https://www.color.org",
"sRGB IEC61966-2.1", new FileInputStream(intent)));
pdf.setTagged();
ConverterProperties properties = new ConverterProperties();
properties.setBaseUri(baseUri);
HtmlConverter.convertToPdf(new ByteArrayInputStream(html), pdf, properties);
}
public void CreatePdf(byte[] html, byte[] xml, string baseUri, string dest, string intent)
{
PdfWriter writer = new PdfWriter(dest);
ConverterProperties properties = new ConverterProperties();
PdfADocument pdf = new PdfADocument(writer, PdfAConformanceLevel.PDF_A_2A, new PdfOutputIntent("Custom", "",
"https://www.color.org", "sRGB IEC61966-2.1", new FileStream(intent, FileMode.Open)));
pdf.SetTagged();
properties.SetBaseUri(baseUri);
HtmlConverter.ConvertToPdf(new MemoryStream(html), pdf, properties);
}
We change the PdfAConformanceLevel (Java/.NET) from PDF_A_2B (Java/.NET) to PDF_A_2A (Java/.NET), and since the second A stands for "accessible" PDF, we need to make sure that we create a Tagged PDF, hence the extra line pdf.setTagged() / pdf.SetTagged(). Figure 4.9 shows that Adobe Acrobat assumes that the document is compliant with PDF/A-2A as well as with the PDF/UA-1 standard, where UA stands for Universal Accessibility.
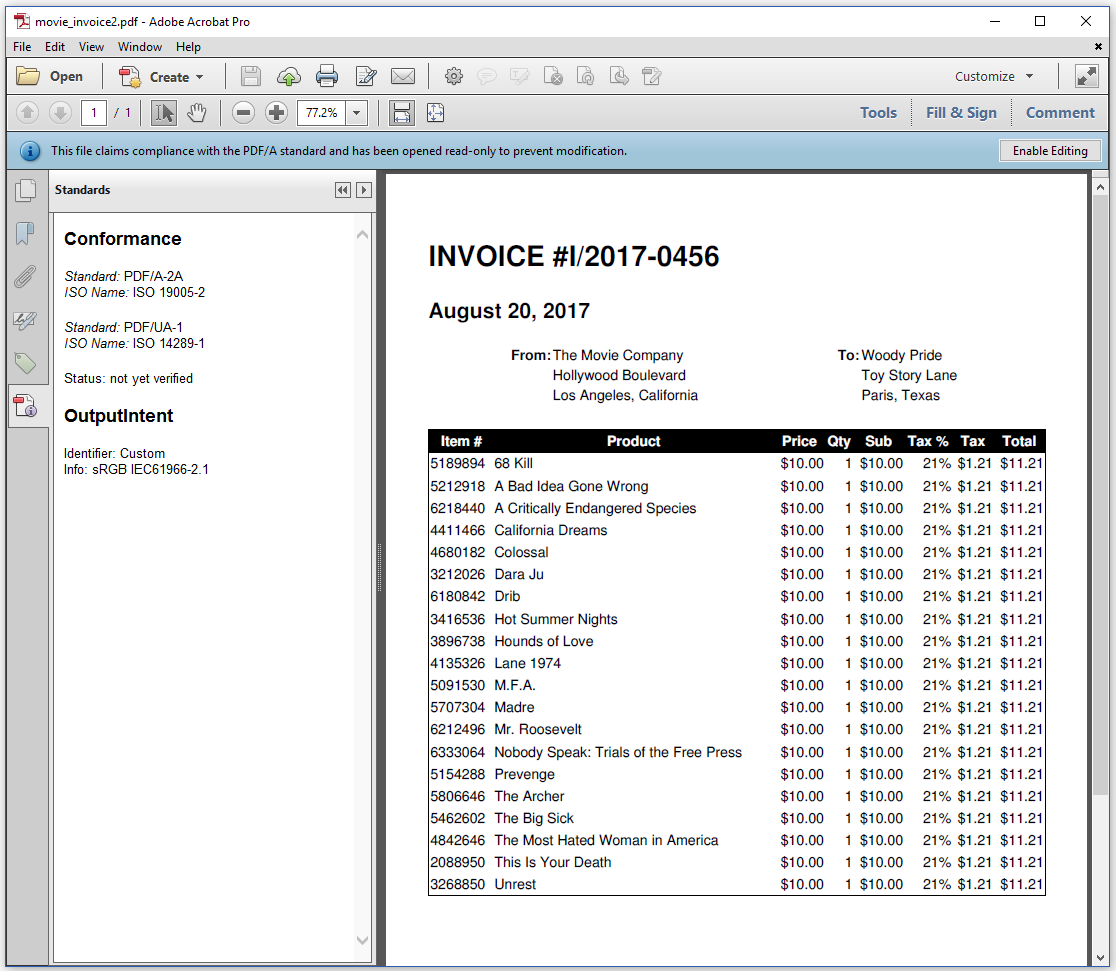
We can use Preflight to verify if this file is compliant with the PDF/A-2A standard, but it's impossible to check full compliance with the PDF/UA-1 standard. PDF/UA has a series of requirements that can only be verified by a human being. For instance: only a human being can check if the PDF was properly tagged; that is: if all the semantic information is correct.
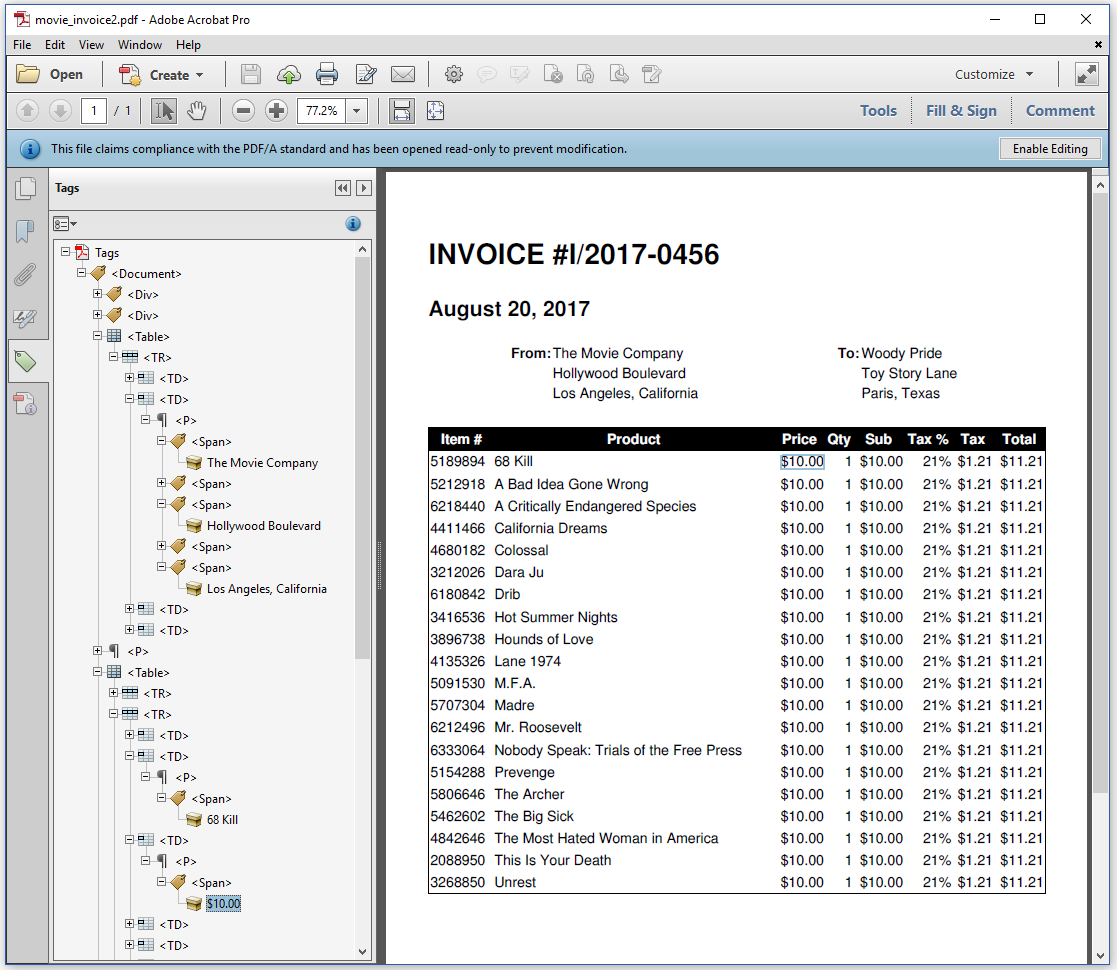
In the previous chapter, we already created some Tagged PDF files, and we briefly discussed that Tagged PDF is both important for disabled people using AT, as well as in the context of Next-Generation PDF. In figure 4.10, we see that iText added a table structure (see the <table>, <TR>, and <TD> tags). It's up to a human being to check whether or not this table structure is the correct semantic representation of the content.
If we'd add an attachment to a PDF/A-2 file, that attachment should be a PDF/A-2 document too. This requirement doesn't exist for PDF/A-3. For instance: we could add the original XML file that was used to create the HTML as extra data to the PDF document.
That's what we've done in the C04E08_MovieInvoice3.java example:
public void createPdf(
byte[] xml, byte[] html, String baseUri, String dest, String intent)
throws IOException {
PdfWriter writer = new PdfWriter(dest);
PdfADocument pdf = new PdfADocument(writer,
PdfAConformanceLevel.PDF_A_3A,
new PdfOutputIntent("Custom", "", "https://www.color.org",
"sRGB IEC61966-2.1", new FileInputStream(intent)));
pdf.setTagged();
pdf.addFileAttachment(
"Movie info", xml, "movies.xml",
PdfName.ApplicationXml, new PdfDictionary(), PdfName.Data);
ConverterProperties properties = new ConverterProperties();
properties.setBaseUri(baseUri);
HtmlConverter.convertToPdf(new ByteArrayInputStream(html), pdf, properties);
}
public void CreatePdf(byte[] html, byte[] xml, string baseUri, string dest, string intent)
{
PdfWriter writer = new PdfWriter(dest);
ConverterProperties properties = new ConverterProperties();
PdfADocument pdf = new PdfADocument(writer, PdfAConformanceLevel.PDF_A_2A, new PdfOutputIntent("Custom", "",
"https://www.color.org", "sRGB IEC61966-2.1", new FileStream(intent, FileMode.Open)));
properties.SetBaseUri(baseUri);
pdf.SetTagged();
PdfFileSpec fileSpec = PdfFileSpec.CreateEmbeddedFileSpec(pdf, xml, "movies.xml",
PdfName.ApplicationXml.ToString(), new PdfDictionary(), PdfName.Data);
pdf.AddFileAttachment("Movie info",fileSpec);
properties.SetBaseUri(baseUri);
HtmlConverter.ConvertToPdf(new MemoryStream(html), pdf, properties);
}
We changed PDF_A_2A (Java/.NET) into PDF_A_3A (Java/.NET), and we used the addFileAttachment() method to add an attachment that consists of Data that provides more info about the movies mentioned on the invoice.
We can see this attachment when we open the attachment panel in Adobe Reader; see figure 4.11.
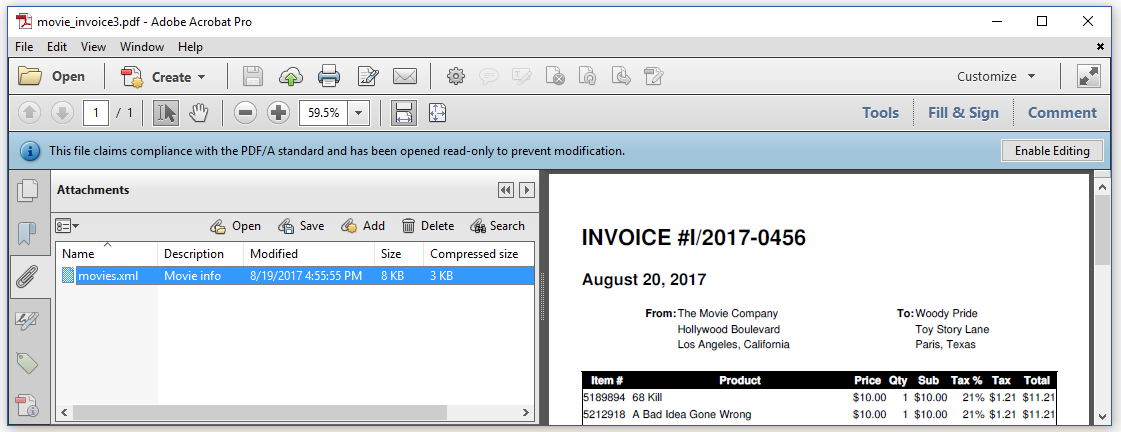
It's no coincidence that I chose the example of an invoice to demonstrate the PDF/A functionality. As a matter of fact, several countries use a PDF invoice standard, known as the ZUGFeRD standard. This standard is based on PDF/A3-B, and requires the PDF to have an attachment that complies with the Cross Industry Invoice (CII) standard.
Summary
In this chapter, we used XSLT to create HTML from XML in order to create reports and invoices. We found out how we can create bookmarks in an automated way, and we learned how to create PDF/A documents. By doing so, we covered some standard use cases that exist at the core of many different industries. In the next chapter, we'll discover how to extend pdfHTML with custom functionality such as support for custom tags and custom CSS behavior.