Which version?
This Tutorial was written with iText 7.0.x in mind, however, if you go to the linked Examples you will find them for the latest available version of iText. If you are looking for a specific version, you can always download these examples from our GitHub repo (Java/.NET).
In chapter 1 to 4, we've created PDF documents using iText 7. In chapters 5 and 6, we've manipulated and reused existing PDF documents. All the PDFs we dealt with in those chapters were PDF documents that complied to ISO 32000, which is the core standard for PDF. ISO 32000 isn't the only ISO standard for PDF, there are many different sub-standards that were created for specific reasons. In this chapter, we'll highlight two:
-
ISO 14289 is better known as PDF/UA. UA stands for Universal Accessibility. PDFs that comply with the PDF/UA standard can be consumed by anyone, including people who are blind or visually impaired.
-
ISO 19005 is better known as PDF/A. A stands for Archiving. The goal of this standard is the long-term preservation of digital documents.
In this chapter, we'll learn more about PDF/A and PDF/UA by creating a series of PDF/A and PDF/UA files.
Creating accessible PDF documents
Before we start with a PDF/UA example, let's take a closer look at the problem we want to solve. In chapter 1, we created a document that included images. In the sentence "Quick brown fox jumps over the lazy dog", we replaced the words "fox" and "dog" by images representing a fox and a dog. When this file is read out loud, a machine doesn't know that the first image represents a fox and that the second image represents a dog, hence the file will be read as "Quick brown jumps over the lazy."
In an ordinary PDF, content is painted to a canvas. We might use high-level objects such as List and Table, but once the PDF is created, there is no structure left. A list is a sequence of lines and a text snippet in a list item doesn't know that it's part of a list. A table is just a bunch of lines and text added at absolute positions on a page. A text snippet in a table doesn't know it belongs to a cell in a specific column and a specific row.
Unless we make the PDF a tagged PDF, the document doesn't contain any semantic structure. When there's no semantic structure, the PDF isn't accessible. To be accessible, the document needs to be able to distinguish which part of a page is actual content, and which part is an artifact that isn't part of the actual content (e.g. a header, a page number). A line of text needs to know if its a title, if it's part of a paragraph, and so on. We can add all of this information to the page, by creating a structure tree and by defining content as marked content. This sounds complex, but if you use iText 7's high-level objects, it's sufficient to introduce the method setTagged(). By defining a PdfDocument as a tagged document, the structure we introduce by using objects such as List, Table, Paragraph, will be reflected in the Tagged PDF.
This is only one requirement to make a PDF accessible. The QuickBrownFox_PDFUA example will help us understand the other requirements.
PdfDocument pdf = new PdfDocument(new PdfWriter(dest, new WriterProperties().AddUAXmpMetadata()));
Document document = new Document(pdf);
//Setting some required parameters
pdf.SetTagged();
pdf.GetCatalog().SetLang(new PdfString("en-US"));
pdf.GetCatalog().SetViewerPreferences(new PdfViewerPreferences().SetDisplayDocTitle(true));
PdfDocumentInfo info = pdf.GetDocumentInfo();
info.SetTitle("iText7 PDF/UA example");
//Fonts need to be embedded
PdfFont font = PdfFontFactory.CreateFont(FONT, PdfEncodings.WINANSI, true);
Paragraph p = new Paragraph();
p.SetFont(font);
p.Add(new Text("The quick brown "));
iText.Layout.Element.Image foxImage = new Image(ImageDataFactory.Create(FOX));
//PDF/UA: Set alt text
foxImage.GetAccessibilityProperties().SetAlternateDescription("Fox");
p.Add(foxImage);
p.Add(" jumps over the lazy ");
iText.Layout.Element.Image dogImage = new iText.Layout.Element.Image(ImageDataFactory.Create(DOG));
//PDF/UA: Set alt text
dogImage.GetAccessibilityProperties().SetAlternateDescription("Dog");
p.Add(dogImage);
document.Add(p);
document.Close();
We create a PdfDocument and a Document, but this time we tell the 'PdfWriter' to automatically add XMP metadata using the 'addUAXmpMetadata()' method of 'WriterProperties'. In PDF/UA, it is mandatory to have the same metadata stored in the PDF as XML. This XML may not be compressed. Processors that don't "understand" PDF must be able to detect this XMP metadata and process it. An XMP stream is created automatically based on the entries in the Info dictionary. This Info dictionary is a PDF Object that includes such data as the title of the document. In addition to this requirement, we make sure that we comply to PDF by introducing some extra features:
-
We tell the
PdfDocumentthat we're going to create Tagged PDF (line 4), -
We add a language specifier. In our case, the document knows that the main language used in this document is American English (line 5).
-
We change the viewer preferences so that the title of the document is always displayed in the top bar of the PDF viewer (line 6-7). Obviously, this implies that we add a title to the metadata of the document (line 8-9).
-
All fonts need to be embedded (line 12). There are some other requirements relating to fonts, but it would lead us too far right now to discuss these in detail.
-
All the content needs to be tagged. When an image is encountered, we need to provide a description of that image using alt text (line 16 and line 21).
We have now created a PDF/UA document. When we look at the resulting page in Figure 7.1, we don't see much difference, but if we open the Tags panel, we see that the document has a specific structure.
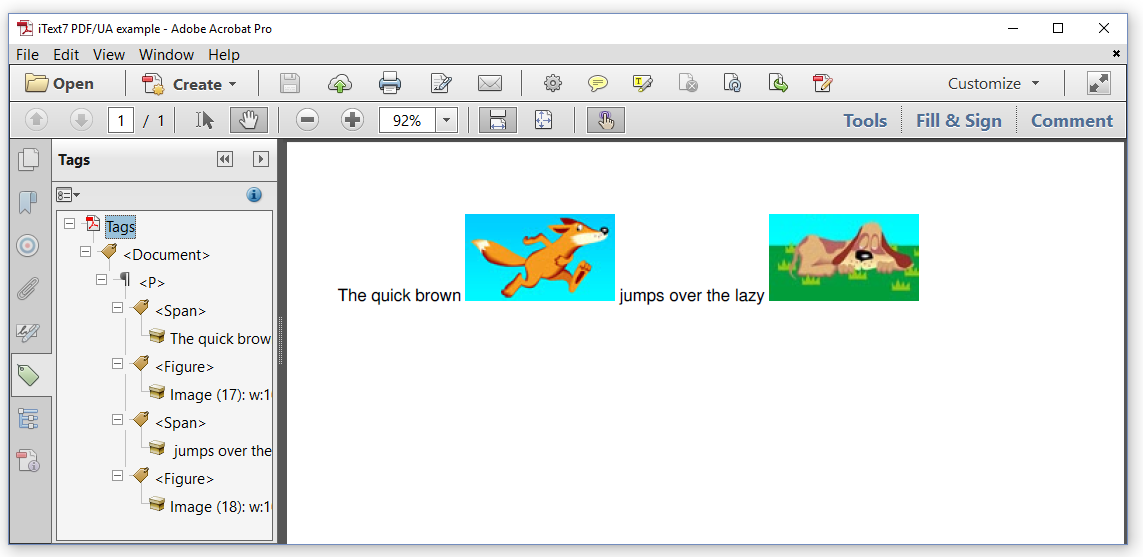
We see that the <Document> consists of a <P>aragraph that is composed of four parts, two <Span>s and two <Figures>s. We'll create a more complex PDF/UA document later in this chapter, but let's take a look at what makes PDF/A special first.
Creating PDFs for long-term preservation, part 1
Part 1 of ISO 19005 was released in 2005. It was defined as a subset of version 1.4 of Adobe's PDF specification (which, at that time, wasn't an ISO standard yet). ISO 19005-1 introduced a series of obligations and restrictions:
-
The document needs to be self-contained: all fonts need to be embedded; external movie, sound or other binary files are not allowed.
-
The document needs to contain metadata in the eXtensible Metadata Platform (XMP) format: ISO 16684 (XMP) describes how to embed XML metadata into a binary file, so that software that doesn't know how to interpret the binary data format can still extract the file's metadata.
-
Functionality that isn't future-proof isn't allowed: the PDF can't contain any JavaScript and may not be encrypted.
ISO 19005-1:2005 (PDF/A-1) defined two conformance levels:
-
Level B ("basic"): ensures that the visual appearance of a document will be preserved for the long term.
-
Level A ("accessible"): ensures that the visual appearance of a document will be preserved for the long term, but also introduces structural and semantic properties. The PDF needs to be a Tagged PDF.
The QuickBrownFox_PDFA_1b example shows how we can create a "Quick brown fox" PDF that complies to PDF/A-1b.
//Initialize PDFA document with output intent
PdfADocument pdf = new PdfADocument(new PdfWriter(dest), PdfAConformanceLevel.PDF_A_1B, new PdfOutputIntent
("Custom", "", "https://www.color.org", "sRGB IEC61966-2.1", new FileStream(INTENT, FileMode.Open, FileAccess.Read
)));
Document document = new Document(pdf);
//Fonts need to be embedded
PdfFont font = PdfFontFactory.CreateFont(FONT, PdfEncodings.WINANSI, true);
Paragraph p = new Paragraph();
p.SetFont(font);
p.Add(new Text("The quick brown "));
iText.Layout.Element.Image foxImage = new Image(ImageDataFactory.Create(FOX));
p.Add(foxImage);
p.Add(" jumps over the lazy ");
iText.Layout.Element.Image dogImage = new iText.Layout.Element.Image(ImageDataFactory.Create(DOG));
p.Add(dogImage);
document.Add(p);
document.Close();
The first thing that jumps to the eye, is that we are no longer using a PdfDocument instance. Instead, we create a PdfADocument instance. The PdfADocument constructor needs a PdfWriter as its first parameter, but also a conformance level (in this case PdfAConformanceLevel.PDF_A_1B) and a PdfOutputIntent. This output intent tells the document how to interpret the colors that will be used in the document. In line 9, we make sure that the font we're using is embedded.
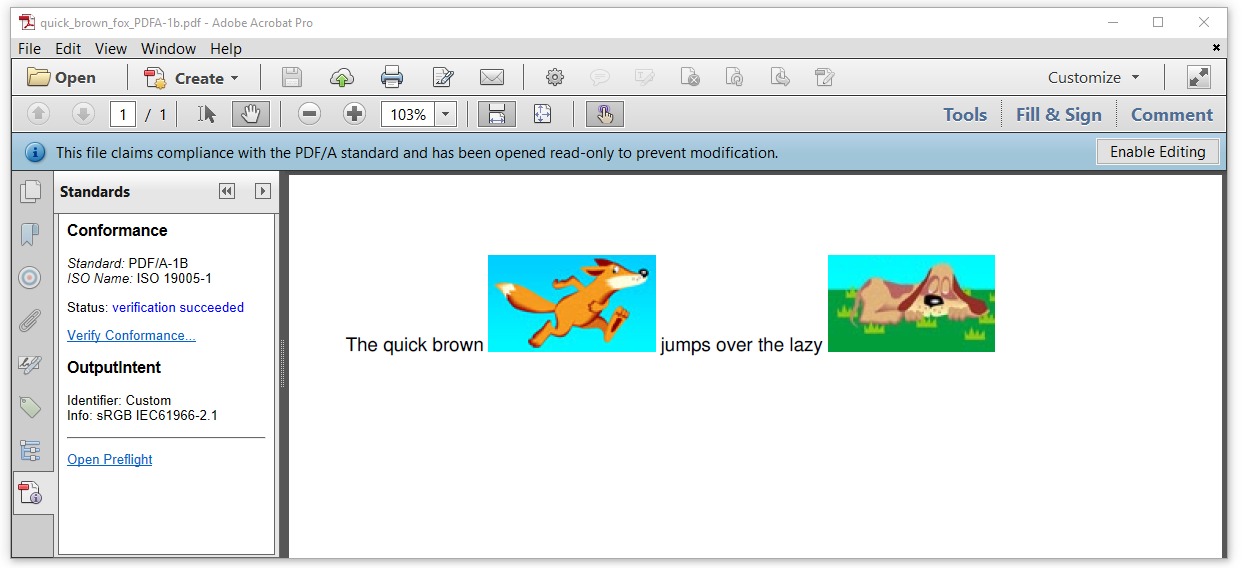
Looking at the PDF shown in Figure 7.2, we see a blue ribbon with the text "This file claims compliance with the PDF/A standard and has been opened read-only to prevent modification." Allow me to explain two things about this sentence:
-
This doesn't mean that the PDF is, in effect, compliant with the PDF/A standard. It only claims it is. To be sure, you need to open the Standards panel in Adobe Acrobat. When you click on the "Verify Conformance" link, Acrobat will verify if the document is what it claims to be. In this case, we read "Status: verification succeeded"; we have successfully created a document complying with PDF/A-1B.
-
The document has been opened read-only, not because you are not allowed to modify it (PDF/A is not a way to protect a PDF against modification), but Adobe Acrobat presents it as read-only because any modification might change the PDF into a PDF that is no longer compliant to the PDF/A standard. It's not trivial to update a PDF/A without breaking its PDF/A status.
Let's adapt our example, and create a PDF/A-1 level A document with the QuickBrownFox_PDFA_1a example.
//Initialize PDFA document with output intent
PdfADocument pdf = new PdfADocument(new PdfWriter(dest), PdfAConformanceLevel.PDF_A_1A, new PdfOutputIntent
("Custom", "", "https://www.color.org", "sRGB IEC61966-2.1", new FileStream(INTENT, FileMode.Open, FileAccess.Read
)));
Document document = new Document(pdf);
//Setting some required parameters
pdf.SetTagged();
//Fonts need to be embedded
PdfFont font = PdfFontFactory.CreateFont(FONT, PdfEncodings.WINANSI, true);
Paragraph p = new Paragraph();
p.SetFont(font);
p.Add(new Text("The quick brown "));
iText.Layout.Element.Image foxImage = new Image(ImageDataFactory.Create(FOX));
//Set alt text
foxImage.GetAccessibilityProperties().SetAlternateDescription("Fox");
p.Add(foxImage);
p.Add(" jumps over the lazy ");
iText.Layout.Element.Image dogImage = new iText.Layout.Element.Image(ImageDataFactory.Create(DOG));
//Set alt text
dogImage.GetAccessibilityProperties().SetAlternateDescription("Dog");
p.Add(dogImage);
document.Add(p);
document.Close();
We've changed PdfAConformanceLevel.PDF_A_1B into PdfAConformanceLevel.PDF_A_1A in line 3. We've made the PdfADocument a Tagged PDF (line 7) and we've added some alt text for the images. Figure 7.3 is somewhat confusing.
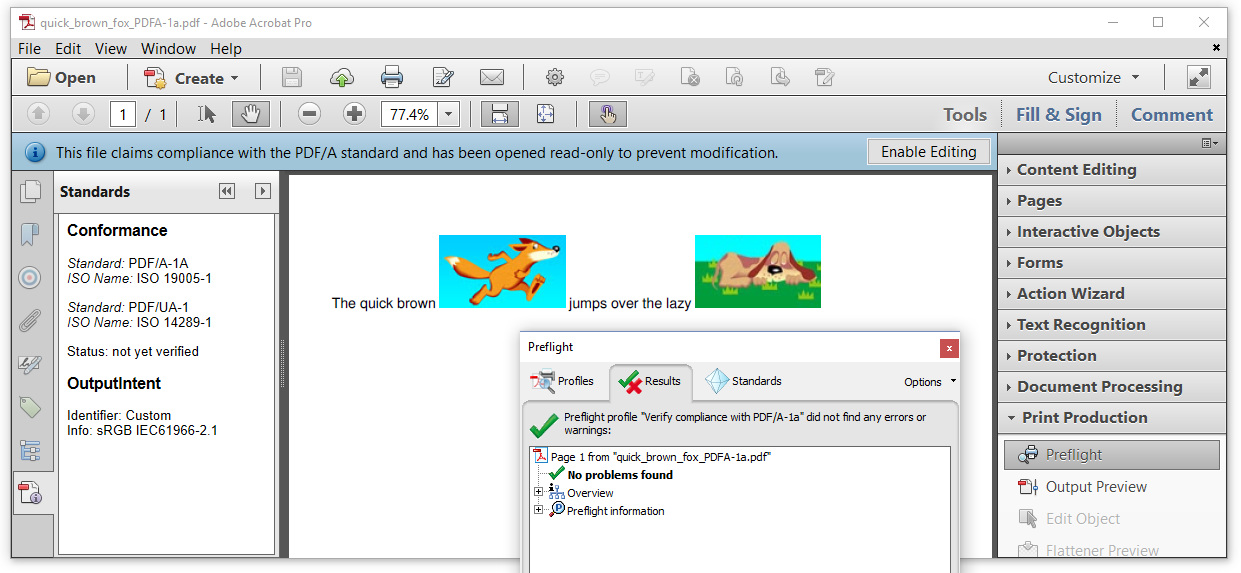
When we look at the Standards panel, we see that the document thinks it conforms to PDF/A-1A and to PDF/UA-1. We don't have a "Verify Conformance" link, so we have to use Preflight. Preflight informs us that there were "No problems found" when executing the "Verify compliance with PDF/A-1a" profile. We can't verify the PDF/UA compliance because PDF/UA involves some requirements that can't be verified by a machine. For instance: a machine wouldn't notice if we switched the description of the image of the fox with the description of the image of the dog. That would make the document inaccessible as the document would spread false information to people depending on screen-readers. In any case, we know that our document doesn't comply to the PDF/UA standard because we omitted a number of essential elements (such as the language).
From the start, it was determined that approved parts of ISO 19005 could never become invalid. New, subsequent parts would only define new, useful features. That's what happened when part 2 and part 3 were created.
Creating PDFs for long-term preservation, part 2 and 3
ISO 19005-2:2011 (PDF/A-2) was introduced to have a PDF/A standard that was based on the ISO standard (ISO 32000-1) instead of on Adobe's PDF specification. PDF/A-2 also adds a handful of features that were introduced in PDF 1.5, 1.6 and 1.7:
-
Useful additions include: support for JPEG2000, Collections, object-level XMP, and optional content.
-
Useful improvements include: better support for transparency, comment types and annotations, and digital signatures.
PDF/A-2 also defines an extra level besides Level A and Level B:
-
Level U ("Unicode"): ensures that the visual appearance of a document will be preserved for the long term, and that all text is stored in UNICODE.
ISO 19005-3:2012 (PDF/A-3) was an almost identical copy of PDF/A-2. There was only one difference with PDF/A-2: in PDF/A-3, attachments don't need to be PDF/A. You can attach any file to a PDF/A-3, for instance: an XLS file containing calculations of which the results are used in the document, the original Word document that was used to create the PDF document, and so on. The document itself needs to conform to all the obligations and restrictions of the PDF/A specification, but these obligations and restrictions do not apply to its attachments.
In the UnitedStates_PDFA_3a example, we'll create a document that complies with PDF/UA as well as with PDF/A-3A. We choose PDF/A3, because we're going to add the CSV file that was used as the source for creating the PDF.
PdfADocument pdf = new PdfADocument(new PdfWriter(dest), PdfAConformanceLevel.PDF_A_3A, new PdfOutputIntent
("Custom", "", "https://www.color.org", "sRGB IEC61966-2.1", new FileStream(INTENT, FileMode.Open, FileAccess.Read
)));
Document document = new Document(pdf, PageSize.A4.Rotate());
document.SetMargins(20, 20, 20, 20);
//Setting some required parameters
pdf.SetTagged();
pdf.GetCatalog().SetLang(new PdfString("en-US"));
pdf.GetCatalog().SetViewerPreferences(new PdfViewerPreferences().SetDisplayDocTitle(true));
PdfDocumentInfo info = pdf.GetDocumentInfo();
info.SetTitle("iText7 PDF/A-3 example");
//Add attachment
PdfDictionary parameters = new PdfDictionary();
parameters.Put(PdfName.ModDate, new PdfDate().GetPdfObject());
PdfFileSpec fileSpec = PdfFileSpec.CreateEmbeddedFileSpec(pdf, File.ReadAllBytes(System.IO.Path.Combine(DATA
)), "united_states.csv", "united_states.csv", new PdfName("text/csv"), parameters, PdfName.Data, false
);
fileSpec.Put(new PdfName("AFRelationship"), new PdfName("Data"));
pdf.AddFileAttachment("united_states.csv", fileSpec);
PdfArray array = new PdfArray();
array.Add(fileSpec.GetPdfObject().GetIndirectReference());
pdf.GetCatalog().Put(new PdfName("AF"), array);
//Embed fonts
PdfFont font = PdfFontFactory.CreateFont(FONT, true);
PdfFont bold = PdfFontFactory.CreateFont(BOLD_FONT, true);
// Create content
Table table = new Table(new float[] { 4, 1, 3, 4, 3, 3, 3, 3, 1 });
table.SetWidth(UnitValue.CreatePercentValue(100));
StreamReader sr = File.OpenText(DATA);
String line = sr.ReadLine();
Process(table, line, bold, true);
while ((line = sr.ReadLine()) != null) {
Process(table, line, font, false);
}
sr.Close();
document.Add(table);
//Close document
document.Close();
Let's examine the different parts of this example.
-
Line 1-5: We create a
PdfADocument(PdfAConformanceLevel.PDF_A_3A) and aDocument. -
Line 7: Making the PDF a Tagged PDF is a requirement for PDF/UA as well as for PDF/A-3A.
-
Line 8-11: Setting the language, the document title and the viewer preference to display the title is a requirement for PDF/UA.
-
Line 13-22: We add a file attachment using specific parameters that are required for PDF/A-3A.
-
Line 24-25: We embed the fonts which is a requirement for PDF/UA as well as for PDF/A.
-
Line 27-36: We've seen this code before in the UnitedStates example in chapter 1 (including the
process()method). -
Line 38: We close the document.
Figure 7.4 demonstrates how using the Table class with Cell objects added as header cells, and Cell objects added as normal cells, resulted in a structure tree that makes the PDF document accessible.
When we open the Attachments panel as shown in Figure 7.5, we see our original united_states.csv file that we can easily extract from the PDF.
The examples in this chapter taught us that PDF/UA or PDF/A documents involve extra requirements when compared to ordinary PDFs. "Can we use iText to convert an existing PDF to a PDF/UA or PDF/A document" is a question that is posted frequently on mailing-lists or user forums. I hope that this chapter explains that iText can't do this automatically.
-
If you have a document that has a picture of a fox and a dog, iText can't add any missing alt text for those images, because iText can't see that fox nor that dog. iText only sees pixels, it can't interpret the image.
-
If you are using a font that isn't embedded, iText doesn't know what that font looks like. If you don't provide the corresponding font program, iText can never embed that font.
These are only two examples of many that explain why converting an ordinary PDF to PDF/A or PDF/UA isn't trivial. It's very easy to change the PDF so that it shows a blue bar saying that the document complies to PDF/A, but that doesn't many that claim is true.
We also need to pay attention when we merge existing PDF/A documents.
Merging PDF/A documents
When merging PDF/A documents, it's very important that every single document that you are adding to PdfMerger is already a PDF/A document. You can't mix PDF/A documents and ordinary PDF documents into one single PDF and hope the result will be a PDF/A document. The same is true for mixing a PDF/A level A document with a PDF/A level B document. One has a structure tree, the other hasn't; you can't expect the resulting PDF to be a PDF/A level A document.
Figure 7.6 shows how we merged the two PDF/A level A documents we created in the previous sections.
When we look at the structure of the tags, we see that the <P>aragraph is now followed by a <Table>. The MergePDFADocuments example shows how it's done.
//Initialize PDFA document with output intent
PdfADocument pdf = new PdfADocument(new PdfWriter(dest), PdfAConformanceLevel.PDF_A_1A, new PdfOutputIntent
("Custom", "", "https://www.color.org", "sRGB IEC61966-2.1", new FileStream(INTENT, FileMode.Open, FileAccess.Read
)));
//Setting some required parameters
pdf.SetTagged();
pdf.GetCatalog().SetLang(new PdfString("en-US"));
pdf.GetCatalog().SetViewerPreferences(new PdfViewerPreferences().SetDisplayDocTitle(true));
PdfDocumentInfo info = pdf.GetDocumentInfo();
info.SetTitle("iText7 PDF/A-1a example");
//Create PdfMerger instance
PdfMerger merger = new PdfMerger(pdf);
//Add pages from the first document
PdfDocument firstSourcePdf = new PdfDocument(new PdfReader(SRC1));
merger.Merge(firstSourcePdf, 1, firstSourcePdf.GetNumberOfPages());
//Add pages from the second pdf document
PdfDocument secondSourcePdf = new PdfDocument(new PdfReader(SRC2));
merger.Merge(secondSourcePdf, 1, secondSourcePdf.GetNumberOfPages());
//Close the documents
firstSourcePdf.Close();
secondSourcePdf.Close();
pdf.Close();
This example is assembled using parts of two examples we've already seen before:
-
Lines 1 to 10 are almost identical to the first part of the UnitedStates_PDFA_3a example we've used in the previous section, except that we now use
PdfAConformanceLevel.PDF_A_1Aand that we don't need aDocumentobject. -
Lines 12 to 22 are identical to the last part of the 88th_Oscar_Combine example of the previous chapter. Note that we use a
PdfDocumentinstance instead of aPdfADocument; thePdfADocumentwill check if the source documents comply.
There's a lot more to be said about PDF/UA and PDF/A, and even about other sub-standards. For instance: there's a German standard for invoicing called ZUGFeRD that is built on top of PDF/A-3, but let's save that for another tutorial.
Summary
In this chapter, we've discovered that there's more to PDF than meets the eye. We've learned how to introduce structure into our documents so that they are accessible for the blind and the visually impaired. We've also made sure that our PDFs were self-contained, for instance by embedding fonts, so that our documents can be archived for the long term.
We'll need several other tutorials to cover the functionality covered in this tutorial in more depth, but these seven chapters should already give you a good impression of what you can do with iText 7.