First, you need to create a parsing template to be able to define or modify the parsing rules.
This document contains some terminology that may not be clear if you are approaching iText pdf2Data for the first time. If this is the case, we recommend starting with Basic concepts of data extraction.
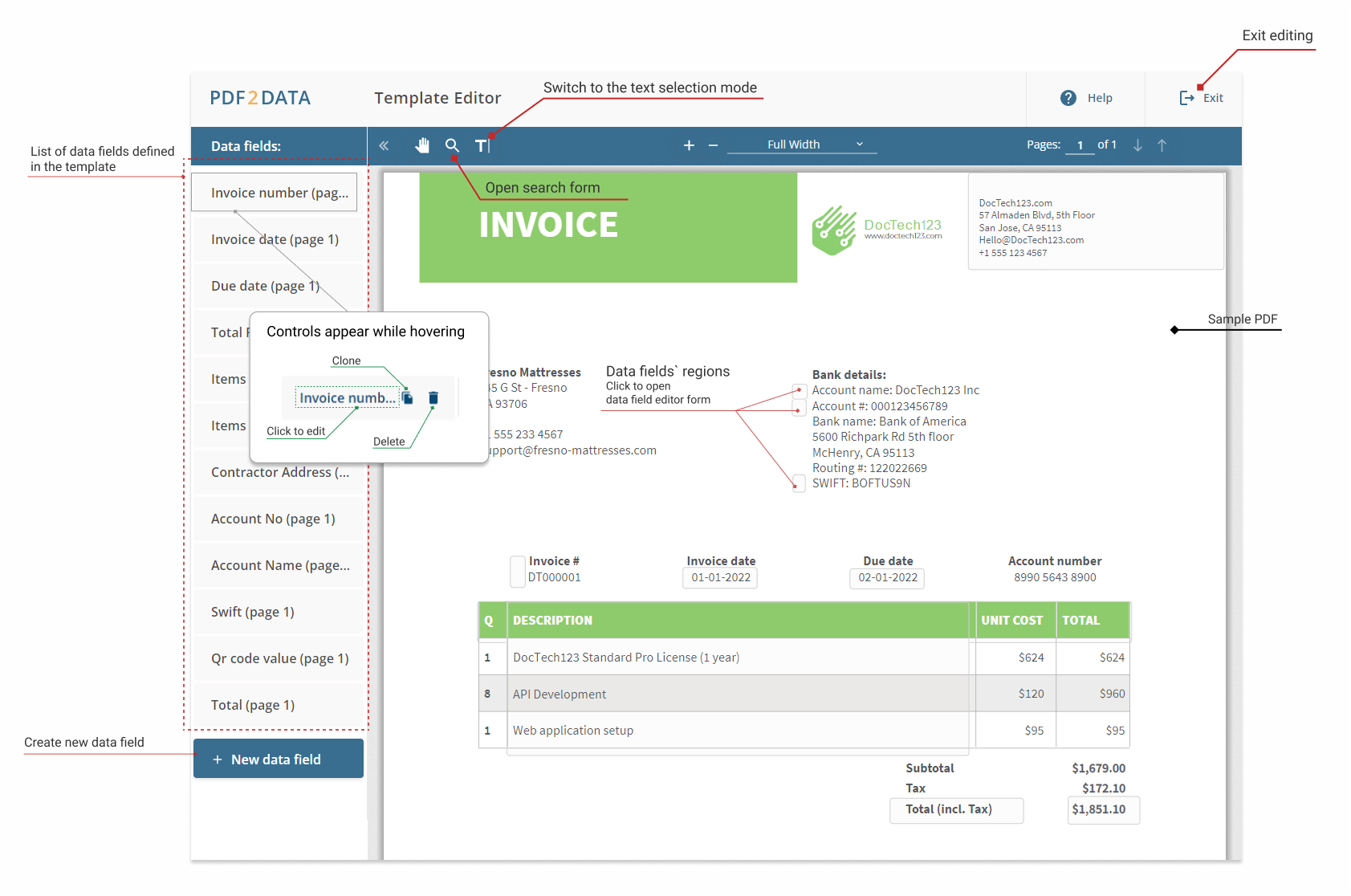
Data fields editor.
Consists of two areas:
-
The left column, which contains the list of data fields defined in the template
-
PDF viewer, which as well as displaying the sample PDF, it also displays the regions of all the template's data fields.
By clicking on either the data field's name in the left column or its region in the viewer, you can open the data field form.
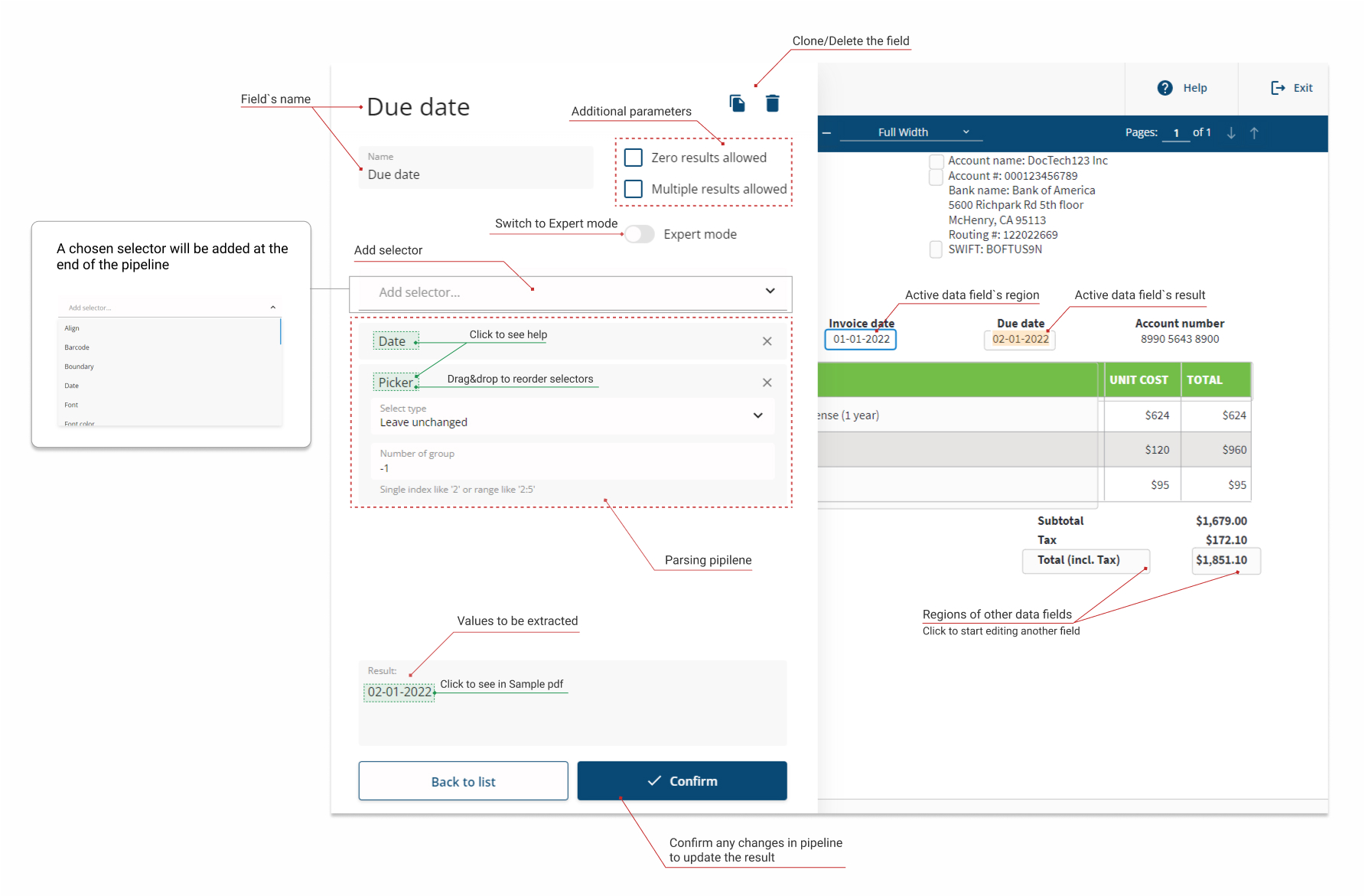
Edit data field form
In this form, you can:
-
Change the field name.
-
Define how the field should extract values from PDF, by modifying the parsing pipeline.
-
Adding a new selector to the end of the pipeline.
-
Changing the parsing order
-
Configuring particular selectors
-
-
Define whether this field is optional ("Zero results allowed" option) or may extract multiple values ("Multiple results allowed").
-
Change data field's region.
After any changes, please click on the "Confirm" button to update the extracted result.
To stop editing and get back to the template overview, click the exit button at the top-right of the window.
Now you can go to Part 3: Test extraction template for individual files