This document contains some terminology that may not be clear if you are approaching iText pdf2Data for the first time. If this is the case, we recommend starting with Basic concepts of data extraction - pdf2Data Documentation.
This guide aims to describe the UI of the Editor if you are interested in how to create your own template, please see Tutorial: Extracting data from PDF invoices.
To be able to work with your template, first of all, you need to create one in the application.
Since an extraction template is effectively a sample PDF with parsing rules added on top of it, you should start with uploading a PDF through the web form.
-
If you're created a template from scratch - begin here with part 1.
-
I've you're coming back to a partially-completed template - you can skip to part 2.
-
If you are testing a completed template - you can go to part 3.
You can also use a existing parsing template. In this case, the pdf2Data editor copies all the existing data fields.
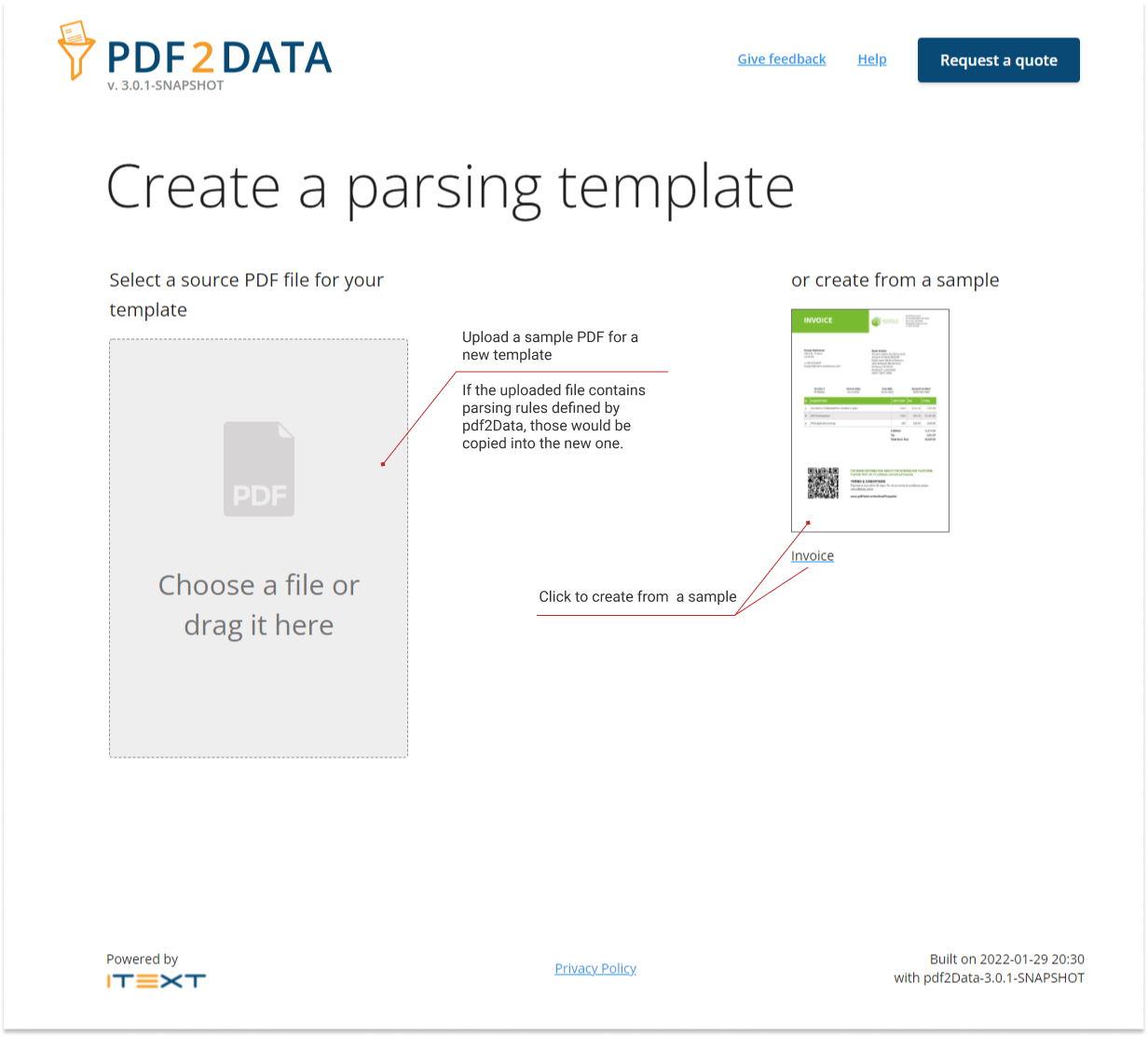
Create a parsing template screen
When the template is uploaded, iText pdf2Data parses it and generates the Template overview.
This report contains a sample PDF preview and a list of all the existing data fields, with extracted values if there are any.
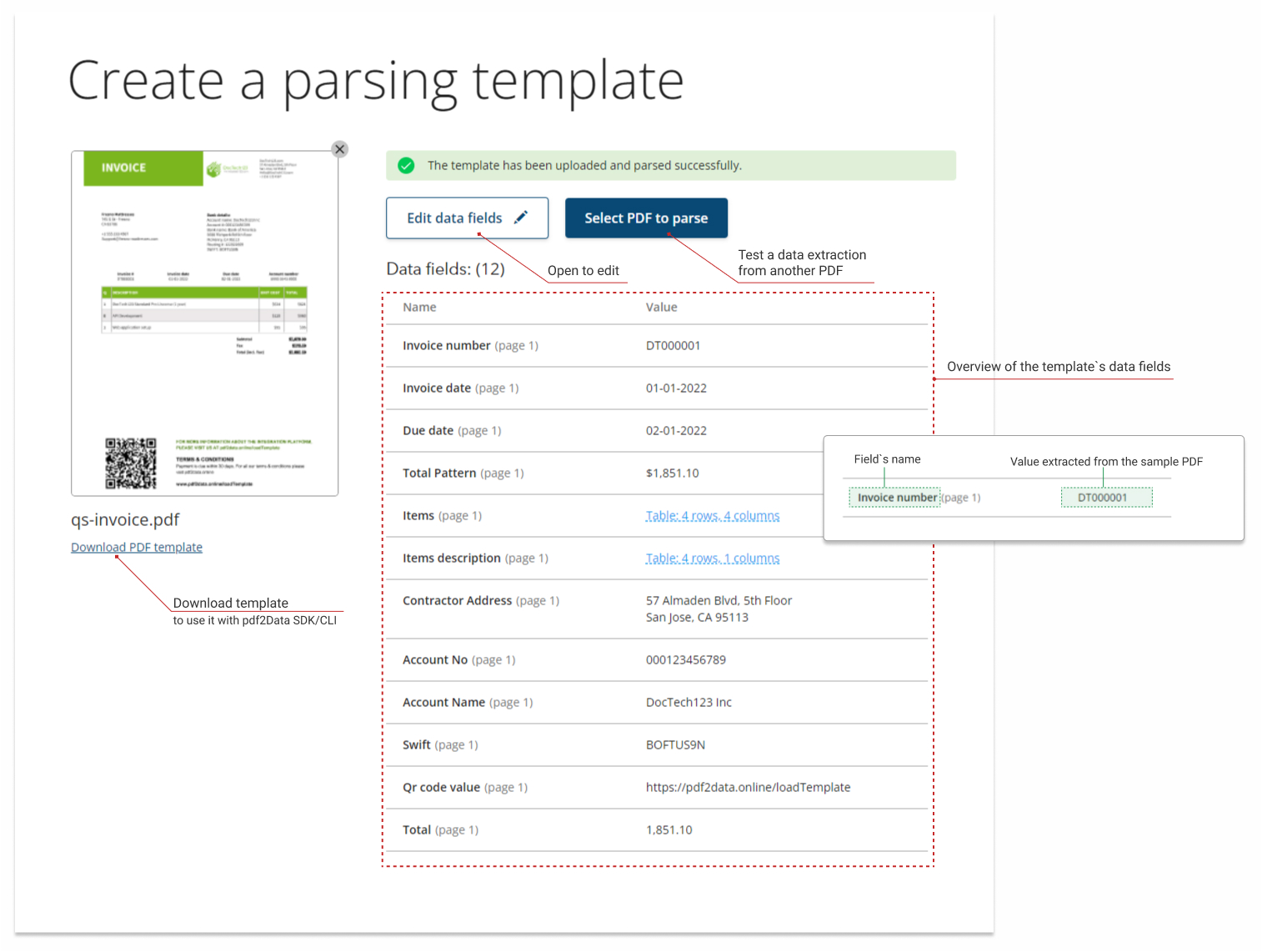
Template overview
From this screen, you can go to the data field editor to add/edit parsing rules, or skip this step and go directly to test your template with individual files.