This document contains some terminology that may not be clear if you are approaching iText pdf2Data for the first time. If this is the case, we recommend starting with Basic concepts of data extraction.
The pdf2Data editor provides you with the ability to test the data extraction rules defined in your template, by using the template you created to parse a PDF matching that structure.
As a result, you get an XML file containing the extracted values, which follows exactly the same structure as the one that the pdf2Data SDK/CLI generates.
So you can make sure that the template fits your needs, and the output can be seamlessly used by the processes you have in place.
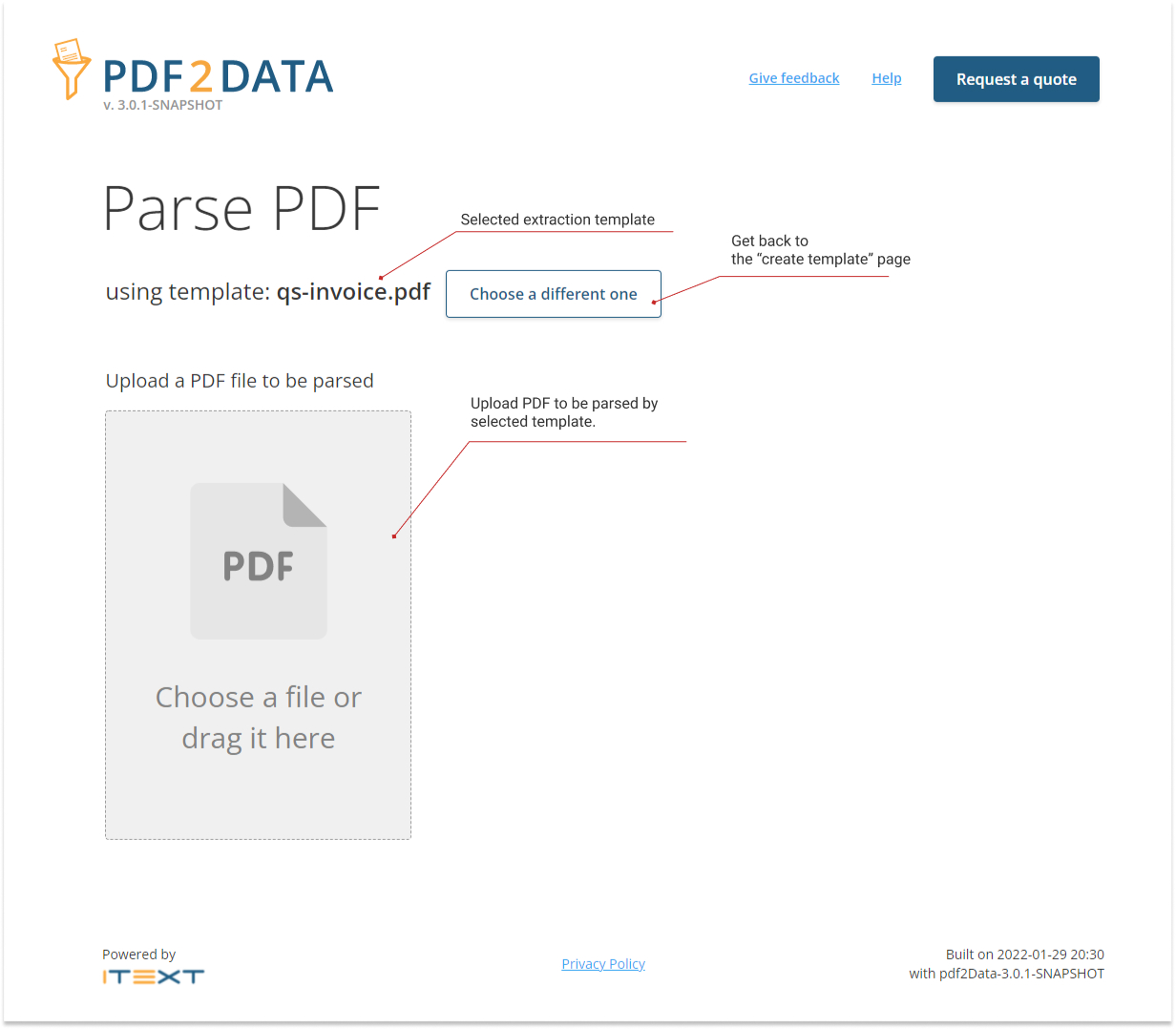
Upload a PDF to parse
On this page, you can see which template will be used for the PDF data extraction, and you can go back to the "create extraction template" page to create a different one.
The PDF to be parsed needs to be uploaded to the editor via the upload form.
After a few seconds, this file will be processed and a report will be generated displaying the values which are being extracted.
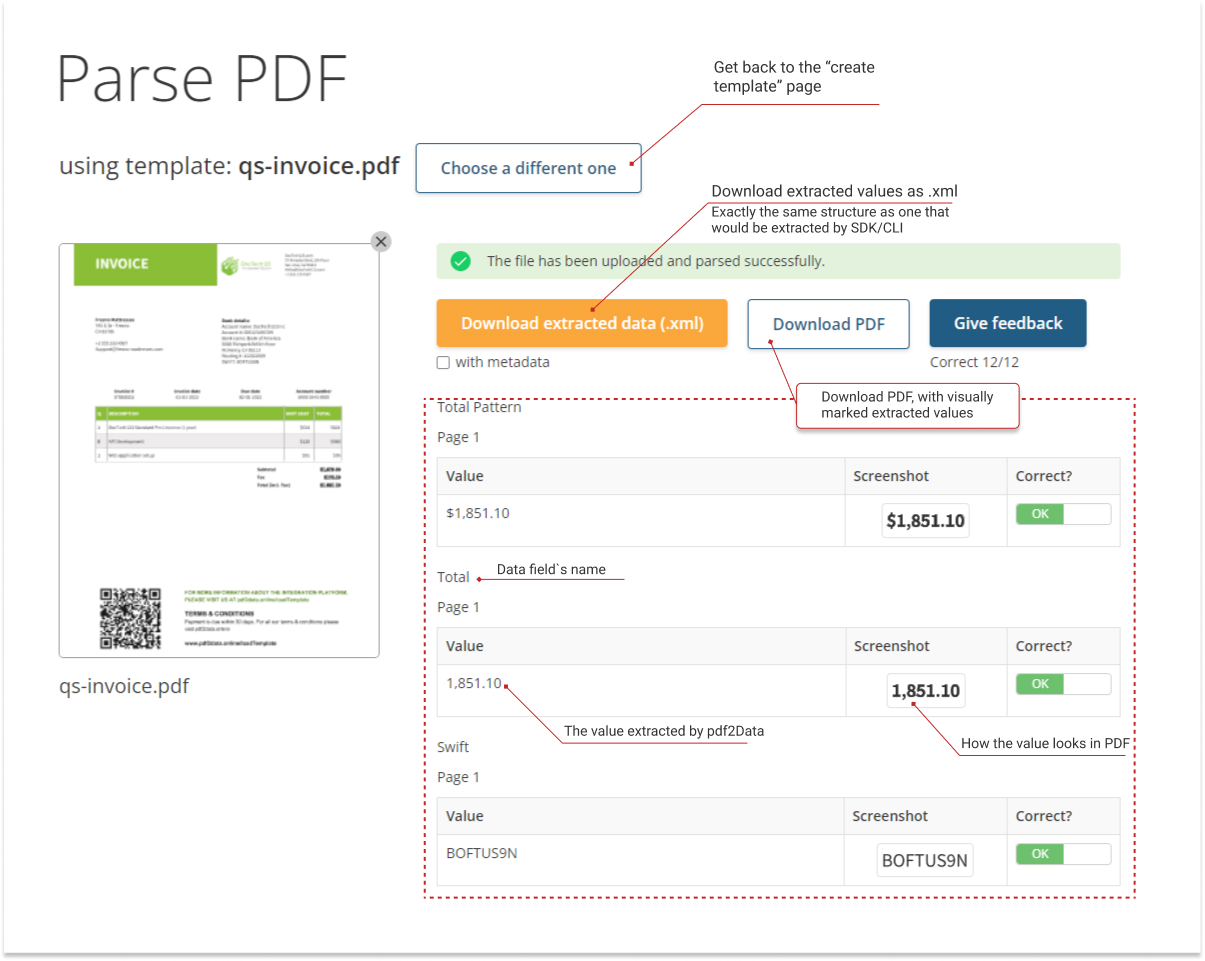
In this report, you can compare data with the value contained in the PDF file to make sure the extraction is being done correctly.
If a value is extracted incorrectly, we would appreciate your feedback. Please mark this by using the controls in the third column, and send us the feedback with the "Give feedback" button.
Extracted values can be downloaded in XML format, following the standard pdf2Data structure, or as a PDF file with an annotation layer containing the extraction results.