This question was originally posted on Stack Overflow on January 6, 2015 by kyzh101
There are two answers to this question. Answer #2 is generally better than answer #1, but I'm giving both options because there may be specific cases where answer #1 is preferred.
Test data: in both answers, we are going to reuse HTML files we have used in previous examples:
-
sxsw.html, and
We put the paths to these files in an array:
public static final String[] SRC = {
String.format("%sinvitation.html", BASEURI),
String.format("%ssxsw.html", BASEURI),
String.format("%smovies.html", BASEURI)
};
We're going to use the pdfHTML add-on to parse these three files and we want a single PDF file as a result.
Answer #1: in the C07E01_CombineHtml (Java/.NET) example, we convert each HTML to a separate PDF file in memory. We merge these files to a single PDF using PdfMerger.
public void createPdf(String baseUri, String[] src, String dest) throws IOException {
ConverterProperties properties = new ConverterProperties();
properties.setBaseUri(baseUri);
PdfWriter writer = new PdfWriter(dest);
PdfDocument pdf = new PdfDocument(writer);
PdfMerger merger = new PdfMerger(pdf);
for (String html : src) {
ByteArrayOutputStream baos = new ByteArrayOutputStream();
PdfDocument temp = new PdfDocument(new PdfWriter(baos));
HtmlConverter.convertToPdf(new FileInputStream(html), temp, properties);
temp = new PdfDocument(
new PdfReader(new ByteArrayInputStream(baos.toByteArray())));
merger.merge(temp, 1, temp.getNumberOfPages());
temp.close();
}
pdf.close();
}
In this example, we introduce the PdfMerger class. This class can merge different PDF files on a page per page basis into a master PdfDocument, in this case pdf. If you have three single-page PDF document, PdfMerger can merge them into a single PDF with three pages, taking the pages as they are, regardless of the amount of content they contain. A page that is half full in the original PDF will be half full in the merged PDF.
We loop over the paths to the different HTML documents. We convert them to a PDF in memory using a ByteArrayOutputStream. We read the bytes of this ByteArrayOutputStream into a PdfReader instance, and we used this PdfReader to create a temporary PdfDocument. We merge this temporary PdfDocument into the PdfMerger instance. Once we have created and merged all PDF files, we close the master PdfDocument.
The result is, in this case, a PDF document consisting of 9 pages: 1 page with the content of invitation.html, 2 pages with the content of sxsw.html, and 6 pages with the content of movies.html
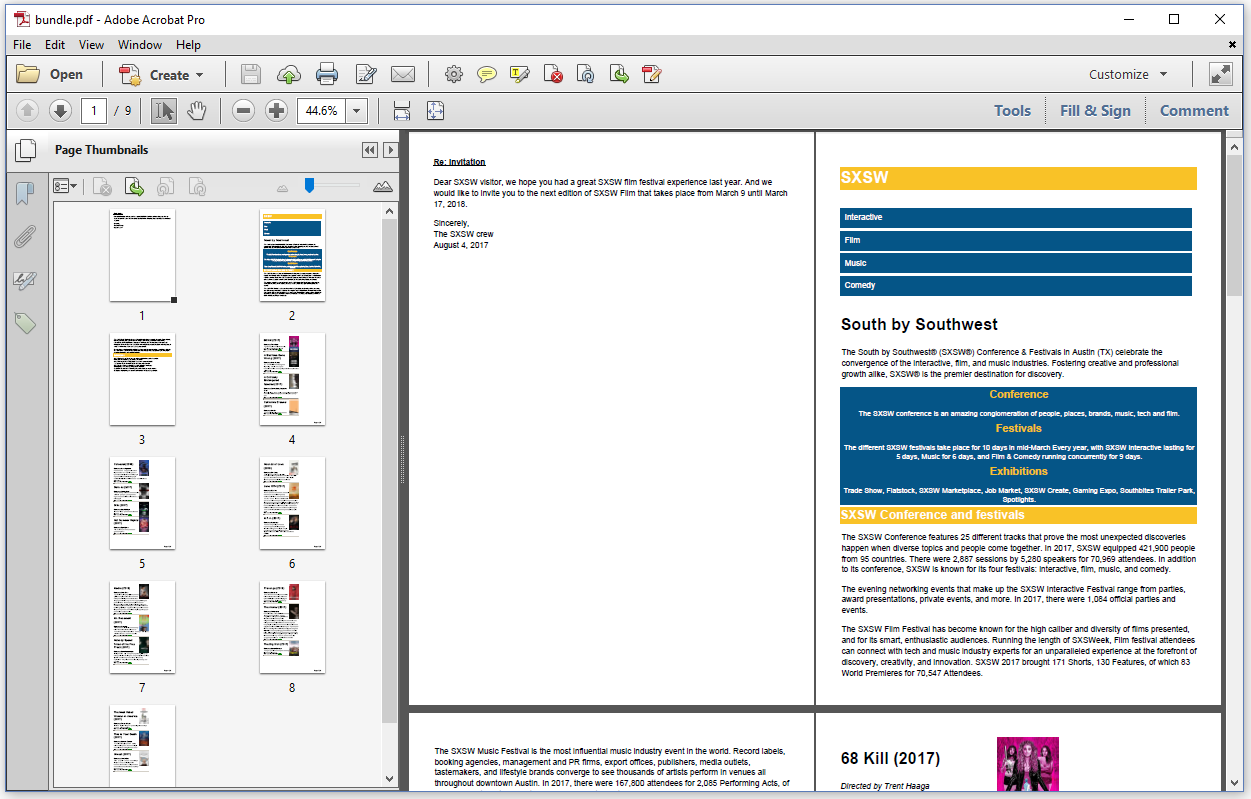
If you want to avoid having too much white space, as is the case on page 1 of our example, you need to take a look at the second answer to this question.
Answer #2: In the C07E02_CombineHtml2 (Java/.NET) example, we parse the different HTML files to a series of iText elements. We add all of these elements to a single PDF document.
public void createPdf(String baseUri, String[] src, String dest) throws IOException {
ConverterProperties properties = new ConverterProperties();
properties.setBaseUri(baseUri);
PdfWriter writer = new PdfWriter(dest);
PdfDocument pdf = new PdfDocument(writer);
Document document = new Document(pdf);
for (String html : src) {
List elements =
HtmlConverter.convertToElements(new FileInputStream(html), properties);
for (IElement element : elements) {
document.add((IBlockElement)element);
}
}
document.close();
}
In this example, we use a technique from chapter 1, but instead of adding the elements generated from a single HTML file to a single PDF, we loop over three different HTML files, parse these files into an element list, and we add these elements to one and the same Document instance.
This results in a PDF document with only 8 pages instead of the 9 we had before.
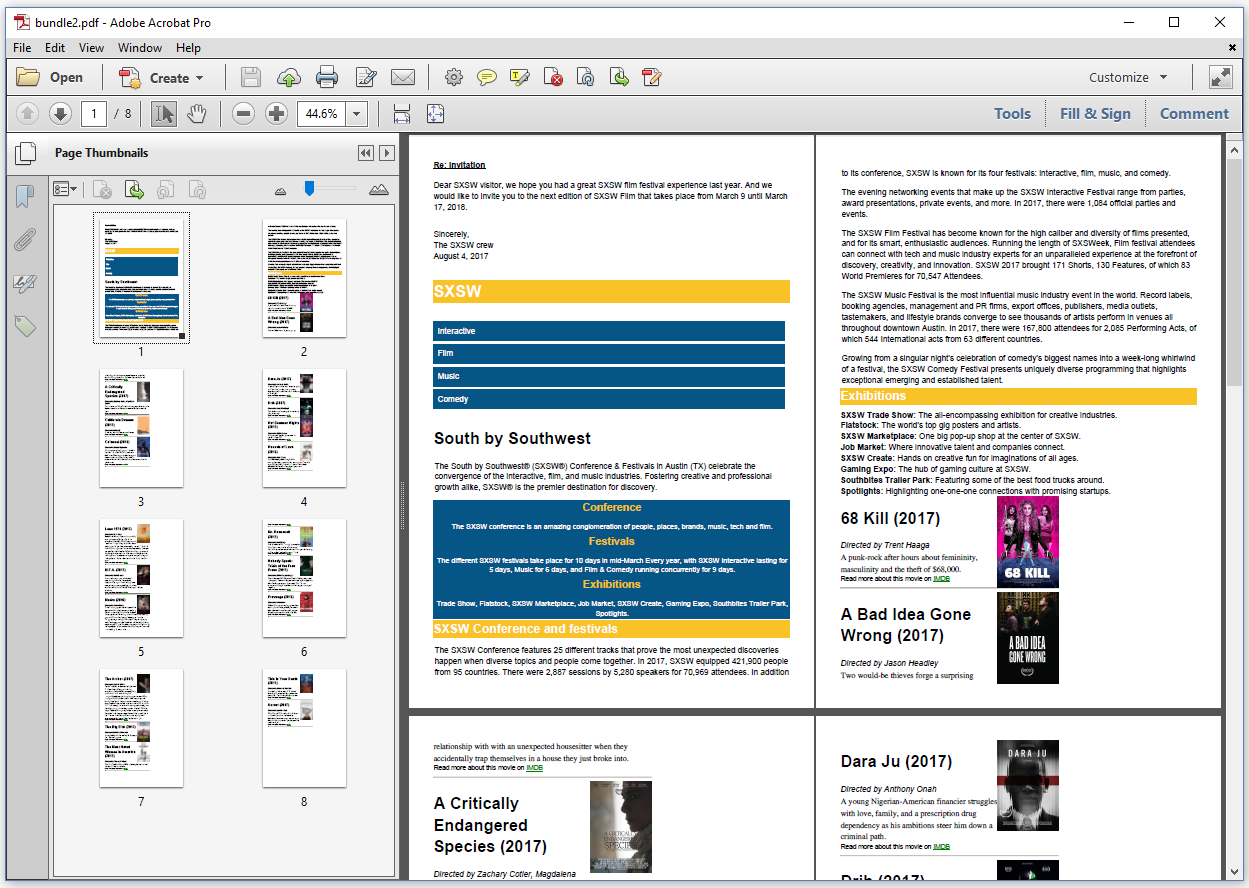
The content of invitation.html is immediately followed by the content of sxsw.html on the first page. The sxsw.html content continues on the second page, and is immediately followed by the content of movies.html.