Which version?
This Tutorial was written with iText 7.0.x in mind, however, if you go to the linked Examples you will find them for the latest available version of iText. If you are looking for a specific version, you can always download these examples from our GitHub repo (Java/.NET).
In this chapter, we'll do some more document manipulation, but there will be a subtle difference in approach. In the examples of the previous chapter, we created one PdfDocument instance that linked a PdfReader to a PdfWriter. We manipulated a single document.
In this chapter, we'll always create at least two PdfDocument instances: one or more for the source document(s), and one for the destination document.
Scaling, tiling, and N-upping
Let's start with some examples that scale and tile a document.
Scaling PDF pages
Suppose that we have a PDF file with a single page, measuring 16.54 by 11.69 in. See Figure 6.1.
Now we want to create a PDF file with three pages. In page one, the original page is scaled down to 11.69 x 8.26 in as shown in Figure 6.2. On page 2, the original page size is preserved. On page 3, the original page is scaled up to 23.39 x 16.53 in as shown in Figure 6.3.
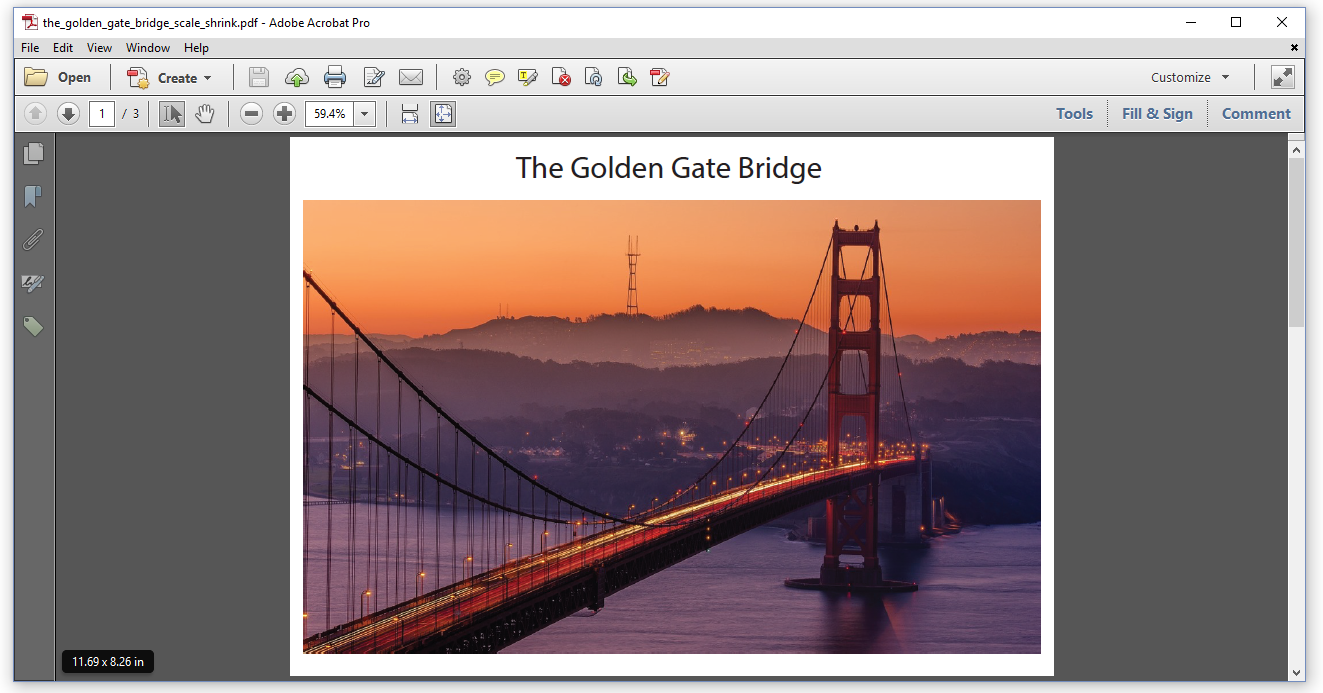
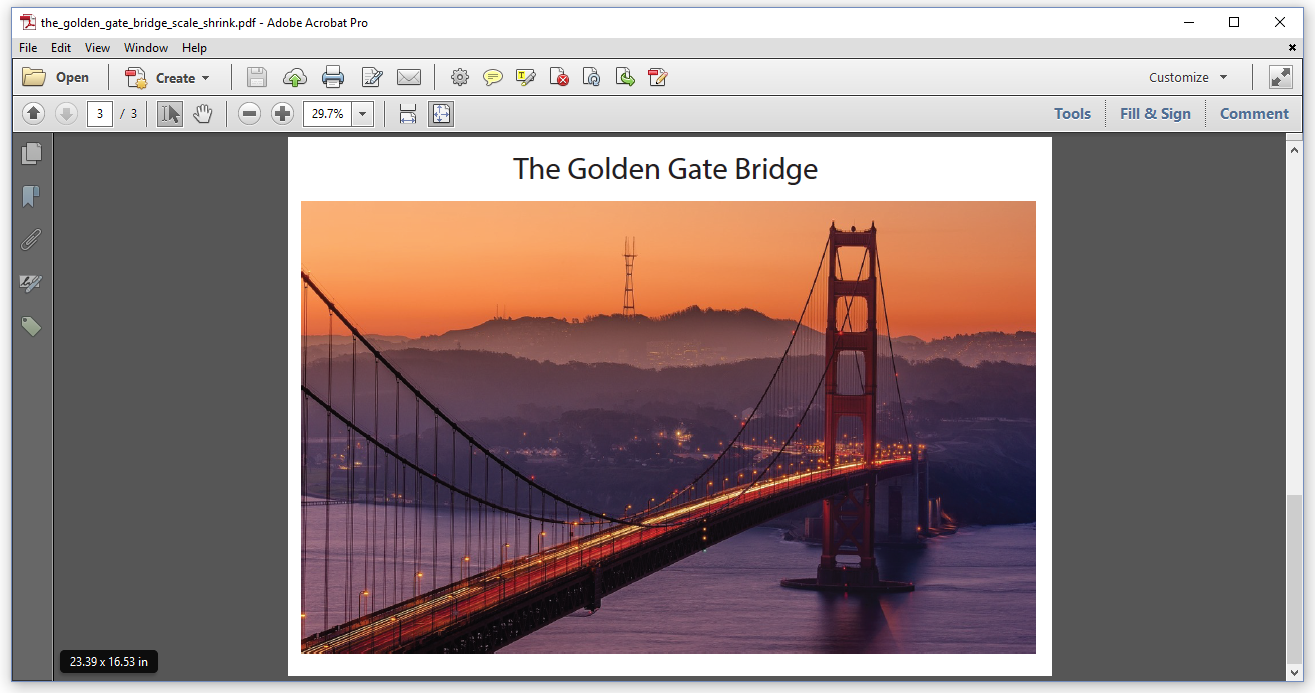
The TheGoldenGateBridge_Scale_Shrink example shows how it's done.
//Initialize PDF document
PdfDocument pdf = new PdfDocument(new PdfWriter(dest));
PdfDocument origPdf = new PdfDocument(new PdfReader(src));
//Original page size
PdfPage origPage = origPdf.GetPage(1);
Rectangle orig = origPage.GetPageSizeWithRotation();
//Add A4 page
PdfPage page = pdf.AddNewPage(PageSize.A4.Rotate());
//Shrink original page content using transformation matrix
PdfCanvas canvas = new PdfCanvas(page);
AffineTransform transformationMatrix = AffineTransform.GetScaleInstance(page.GetPageSize().GetWidth() / orig
.GetWidth(), page.GetPageSize().GetHeight() / orig.GetHeight());
canvas.ConcatMatrix(transformationMatrix);
PdfFormXObject pageCopy = origPage.CopyAsFormXObject(pdf);
canvas.AddXObject(pageCopy, 0, 0);
//Add page with original size
pdf.AddPage(origPage.CopyTo(pdf));
//Add A2 page
page = pdf.AddNewPage(PageSize.A2.Rotate());
//Scale original page content using transformation matrix
canvas = new PdfCanvas(page);
transformationMatrix = AffineTransform.GetScaleInstance(page.GetPageSize().GetWidth() / orig.GetWidth(), page
.GetPageSize().GetHeight() / orig.GetHeight());
canvas.ConcatMatrix(transformationMatrix);
canvas.AddXObject(pageCopy, 0, 0);
pdf.Close();
origPdf.Close();
In this code snippet, we create a PdfDocument instance that will create a new PDF document (line 2); and we create a PdfDocument instance that will read an existing PDF document (line 3). We get a PdfPage instance for the first page of the existing PDF (line 3), and we get its dimensions (line 6). We then add three pages to the new PDF document:
-
We add an A4 page using landscape orientation (line 8) and we create a
PdfCanvasobject for that page. Instead of calculating thea,b,c,d,e, andfvalue for a transformation matrix that will scale the coordinate system, we use anAffineTransforminstance using thegetScaleInstance()method (line 11-12). We apply that transformation (line 13), we create a Form XObject containing the original page (line 14) and we add that XObject to the new page (line 15). -
Adding the original page in its original dimensions is much easier. We just create a new page by copying the
origPageto the newPdfDocumentinstance, and we add it to thepdfusing theaddPage()method (line 17). -
Scaling up and shrinking is done in the exact same way. This time, we add a new A2 page using landscape orientation (line 19) and we use the exact same code we had before to scale the coordinate system (line 22-24). We reuse the
pageCopyobject and add it to thecanvas(line 25).
We close the pdf to finalize the new document (line 30) and we close the origPdf to release the resources of the original document.
We can use the same functionality to tile a PDF page.
Tiling PDF pages
Tiling a PDF page means that you distribute the content of one page over different pages. For instance: if you have a PDF with a single page of size A3, you can create a PDF with four pages of a different size –or even the same size–, each showing one quarter of the original A3 page. This is what we've done in Figure 6.4.
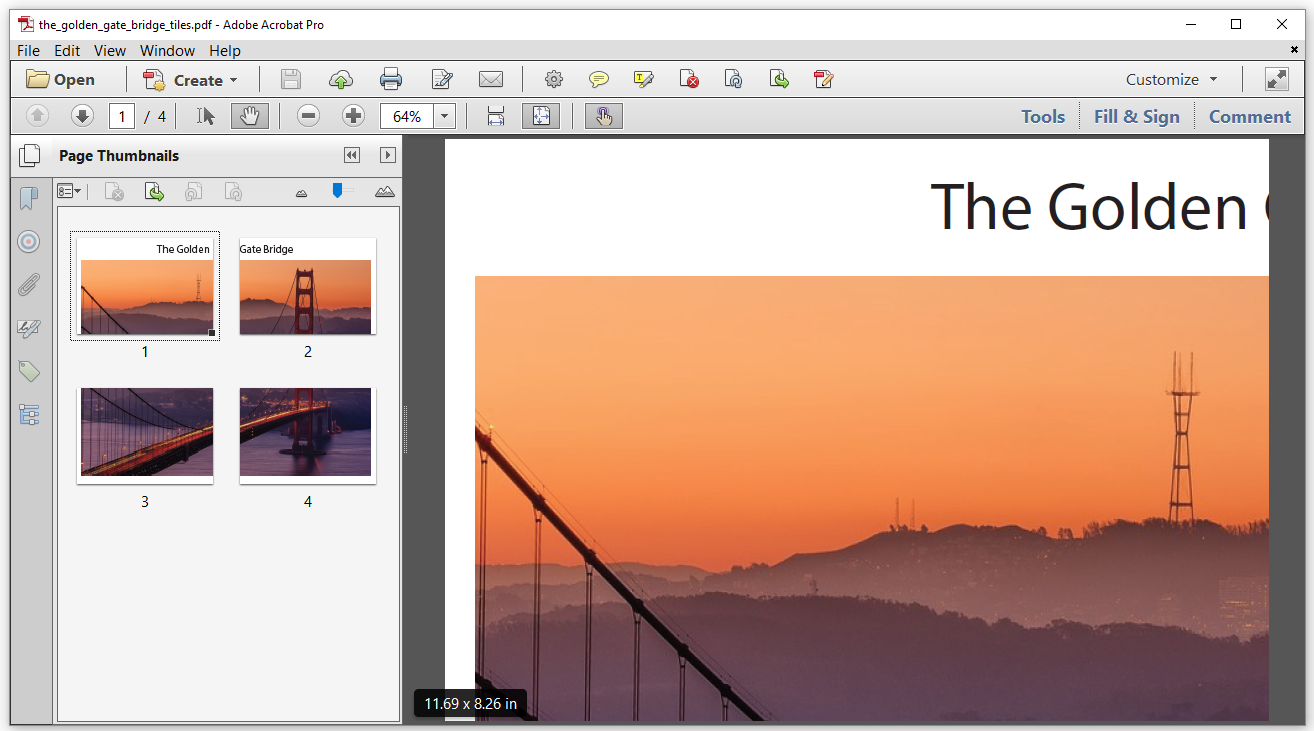
Let's take a look at the TheGoldenGateBridge_Tiles example.
//Initialize PDF document
PdfDocument pdf = new PdfDocument(new PdfWriter(dest));
PdfDocument sourcePdf = new PdfDocument(new PdfReader(src));
//Original page
PdfPage origPage = sourcePdf.GetPage(1);
PdfFormXObject pageCopy = origPage.CopyAsFormXObject(pdf);
//Original page size
Rectangle orig = origPage.GetPageSize();
//Tile size
Rectangle tileSize = PageSize.A4.Rotate();
// Transformation matrix
AffineTransform transformationMatrix = AffineTransform.GetScaleInstance(tileSize.GetWidth() / orig.GetWidth
() * 2f, tileSize.GetHeight() / orig.GetHeight() * 2f);
//The first tile
PdfPage page = pdf.AddNewPage(PageSize.A4.Rotate());
PdfCanvas canvas = new PdfCanvas(page);
canvas.ConcatMatrix(transformationMatrix);
canvas.AddXObject(pageCopy, 0, -orig.GetHeight() / 2f);
//The second tile
page = pdf.AddNewPage(PageSize.A4.Rotate());
canvas = new PdfCanvas(page);
canvas.ConcatMatrix(transformationMatrix);
canvas.AddXObject(pageCopy, -orig.GetWidth() / 2f, -orig.GetHeight() / 2f);
//The third tile
page = pdf.AddNewPage(PageSize.A4.Rotate());
canvas = new PdfCanvas(page);
canvas.ConcatMatrix(transformationMatrix);
canvas.AddXObject(pageCopy, 0, 0);
//The fourth tile
page = pdf.AddNewPage(PageSize.A4.Rotate());
canvas = new PdfCanvas(page);
canvas.ConcatMatrix(transformationMatrix);
canvas.AddXObject(pageCopy, -orig.GetWidth() / 2f, 0);
pdf.Close();
sourcePdf.Close();
We've seen lines 1-8 before; we already used them in the previous example. In line 10, we define a tile size, and we create a transformationMatrix to scale the coordinate system depending on the original size and the tile size. Then we add the tiles, one by one: line 15-18, line 20-23, line 25-28, and line 30-33 are identical, except for one detail: the offset used in the addXObject() method.
Let's use the PDF with the Golden Gate Bridge for one more example. Let's do the opposite of tiling: let's N-up a PDF.
N-upping a PDF
Figure 6.5 shows what we mean by N-upping. In the next example, we're going to put N pages on one single page.
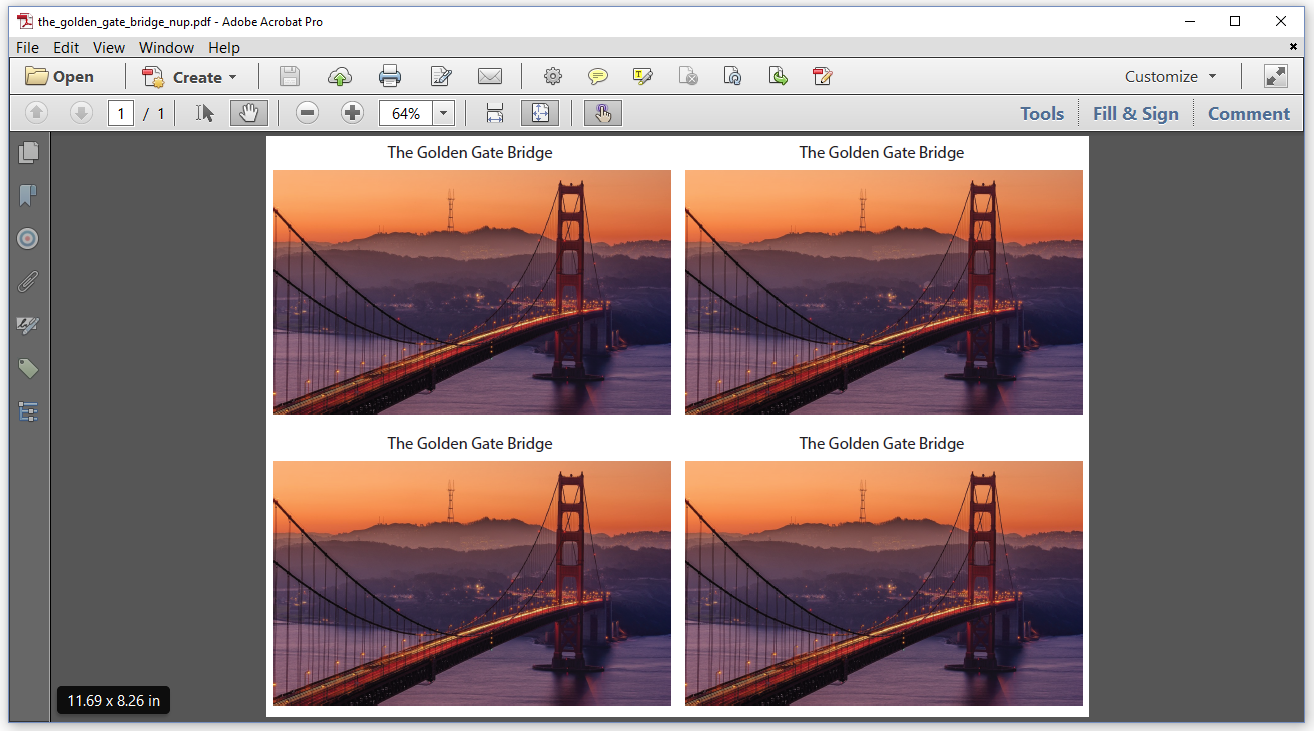
In the TheGoldenGateBridge_N_up example, N is equal to 4. We will put 4 pages on one single page.
//Initialize PDF document
PdfDocument pdf = new PdfDocument(new PdfWriter(dest));
PdfDocument sourcePdf = new PdfDocument(new PdfReader(SRC));
//Original page
PdfPage origPage = sourcePdf.GetPage(1);
//Original page size
Rectangle orig = origPage.GetPageSize();
PdfFormXObject pageCopy = origPage.CopyAsFormXObject(pdf);
//N-up page
PageSize nUpPageSize = PageSize.A4.Rotate();
PdfPage page = pdf.AddNewPage(nUpPageSize);
PdfCanvas canvas = new PdfCanvas(page);
//Scale page
AffineTransform transformationMatrix = AffineTransform.GetScaleInstance(nUpPageSize.GetWidth() / orig.GetWidth
() / 2f, nUpPageSize.GetHeight() / orig.GetHeight() / 2f);
canvas.ConcatMatrix(transformationMatrix);
//Add pages to N-up page
canvas.AddXObject(pageCopy, 0, orig.GetHeight());
canvas.AddXObject(pageCopy, orig.GetWidth(), orig.GetHeight());
canvas.AddXObject(pageCopy, 0, 0);
canvas.AddXObject(pageCopy, orig.GetWidth(), 0);
pdf.Close();
sourcePdf.Close();
So far, we've only reused a single page from a single PDF in this chapter. In the next series of examples, we'll assemble different PDF files into one.
Assembling documents
Let's go from San Francisco to Los Angeles, and take a look at Figure 6.6 where we'll find three documents about the Oscars.
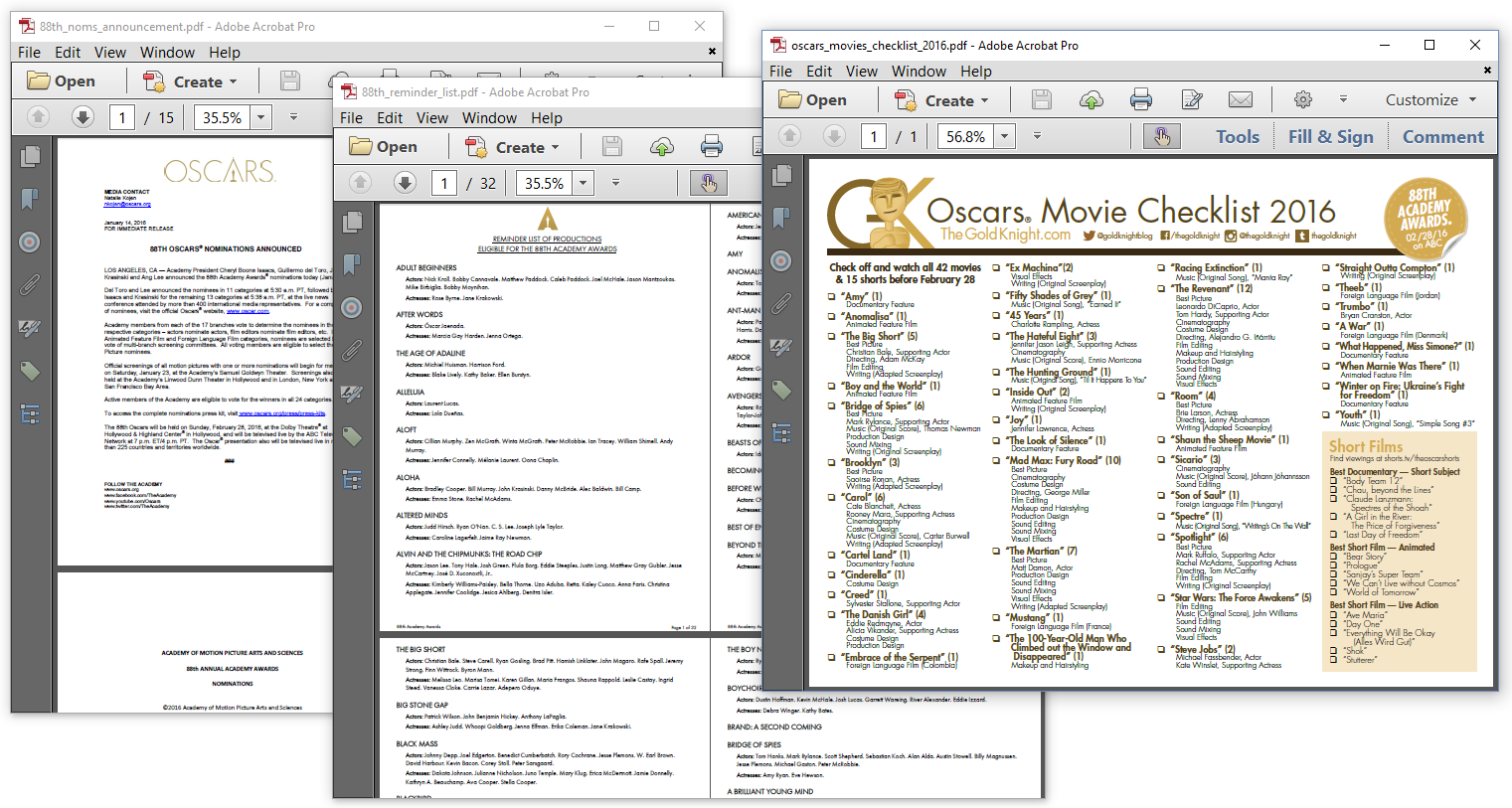
The documents are:
-
88th_reminder_list.pdf: a 32-page document, entitled "Reminder List of Productions Eligible for the 88th Academy Awards"
-
88th_noms_announcement.pdf: a 15-page document, entitled "Oscars"
-
oscars_movies_checklist_2016.pdf: a 1-page document, entitled "Oscars Movie Checklist 2016"
In the next couple of examples, we'll merge these documents.
Merging documents with PdfMerger
Figure 6.7 shows a PDF that was created by merging the first 32-page document with the second 15-page document, resulting in a 47-page document.
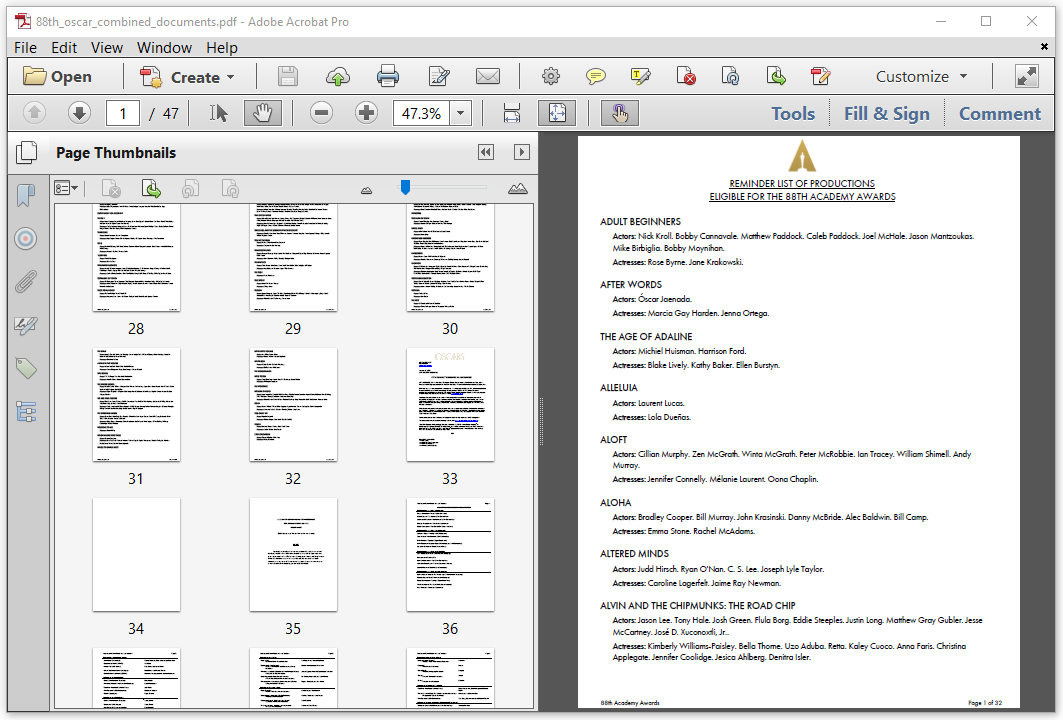
The code of the 88th_Oscar_Combine example is almost self-explaining.
//Initialize PDF document with output intent
PdfDocument pdf = new PdfDocument(new PdfWriter(dest));
PdfMerger merger = new PdfMerger(pdf);
//Add pages from the first document
PdfDocument firstSourcePdf = new PdfDocument(new PdfReader(SRC1));
merger.Merge(firstSourcePdf, 1, firstSourcePdf.GetNumberOfPages());
//Add pages from the second pdf document
PdfDocument secondSourcePdf = new PdfDocument(new PdfReader(SRC2));
merger.Merge(secondSourcePdf, 1, secondSourcePdf.GetNumberOfPages());
firstSourcePdf.Close();
secondSourcePdf.Close();
pdf.Close();
We create a PdfDocument to create a new PDF (line 2). The PdfMerger class is new. It's a class that will make it easier for us to reuse pages from existing documents (line 3). Just like before, we create a PdfDocument for the source file (line 5, line 8); we then add all the pages using the merger instance and the 'merge()' method (line 6, line 9). Once we're done adding pages, weclose() (line 10-12).
We don't need to add all the pages if we don't want to. We can easily add only a limited selection of pages. See for instance the 88th_Oscar_CombineXofY example.
//Initialize PDF document with output intent
PdfDocument pdf = new PdfDocument(new PdfWriter(dest));
PdfMerger merger = new PdfMerger(pdf);
//Add pages from the first document
PdfDocument firstSourcePdf = new PdfDocument(new PdfReader(SRC1));
merger.Merge(firstSourcePdf, iText.IO.Util.JavaUtil.ArraysAsList(1, 5, 7, 1));
//Add pages from the second pdf document
PdfDocument secondSourcePdf = new PdfDocument(new PdfReader(SRC2));
merger.Merge(secondSourcePdf, iText.IO.Util.JavaUtil.ArraysAsList(1, 15));
firstSourcePdf.Close();
secondSourcePdf.Close();
pdf.Close()
Now the resulting document only has six pages. Pages 1, 5, 7, 1 from the first document (the first page is repeated), and pages 1 and 15 from the second document. PdfMerger is a convenience class that makes merging documents a no-brainer. In some cases however, you'll want to add pages one by one.
Adding pages to a PdfDocument
Figure 6.8 shows the result of the merging of specific pages based on a Table of Contents (TOC) that we'll create on the fly. This TOC contains link annotations that allow you to jump to a specific page if you click an entry of the TOC.
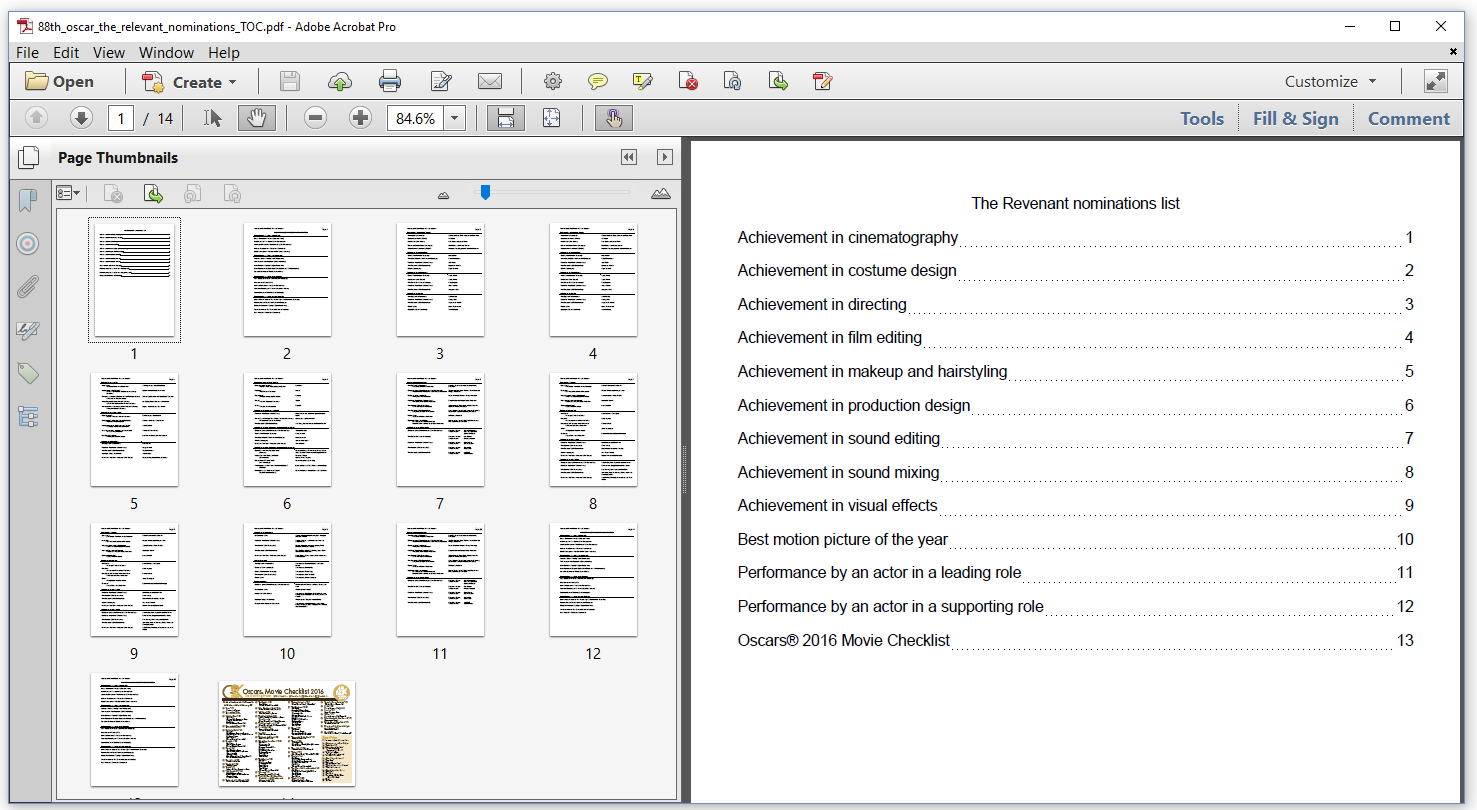
The 88th_Oscar_Combine_AddTOC example is more complex than the two previous examples. Let's examine it step by step.
Suppose that we have a TreeMap of all the categories the movie "The Revenant" was nominated for, where the key is the nomination and the value is the page number of the document where the nomination is mentioned.
public static readonly IDictionary<String, int> TheRevenantNominations = new SortedDictionary<String, int
>();
static C06E06_88th_Oscar_Combine_AddTOC() {
TheRevenantNominations["Performance by an actor in a leading role"] = 4;
TheRevenantNominations["Performance by an actor in a supporting role"] = 4;
TheRevenantNominations["Achievement in cinematography"] = 4;
TheRevenantNominations["Achievement in costume design"] = 5;
TheRevenantNominations["Achievement in directing"] = 5;
TheRevenantNominations["Achievement in film editing"] = 6;
TheRevenantNominations["Achievement in makeup and hairstyling"] = 7;
TheRevenantNominations["Best motion picture of the year"] = 8;
TheRevenantNominations["Achievement in production design"] = 8;
TheRevenantNominations["Achievement in sound editing"] = 9;
TheRevenantNominations["Achievement in sound mixing"] = 9;
TheRevenantNominations["Achievement in visual effects"] = 10;
}
The first lines of the code that creates the PDF are pretty simple.
PdfDocument pdfDoc = new PdfDocument(new PdfWriter(dest));
Document document = new Document(pdfDoc);
document.Add(new Paragraph(new Text("The Revenant nominations list"))
.SetTextAlignment(TextAlignment.CENTER));
But we need to take a really close look once we start to loop over the entries in the TreeMap.
PdfDocument firstSourcePdf = new PdfDocument(new PdfReader(SRC1));
foreach (KeyValuePair<String, int> entry in TheRevenantNominations) {
//Copy page
PdfPage page = firstSourcePdf.GetPage(entry.Value).CopyTo(pdfDoc);
pdfDoc.AddPage(page);
//Overwrite page number
Text text = new Text(String.Format("Page %d", pdfDoc.GetNumberOfPages() - 1));
text.SetBackgroundColor(Color.WHITE);
document.Add(new Paragraph(text).SetFixedPosition(pdfDoc.GetNumberOfPages(), 549, 742, 100));
//Add destination
String destinationKey = "p" + (pdfDoc.GetNumberOfPages() - 1);
PdfArray destinationArray = new PdfArray();
destinationArray.Add(page.GetPdfObject());
destinationArray.Add(PdfName.XYZ);
destinationArray.Add(new PdfNumber(0));
destinationArray.Add(new PdfNumber(page.GetMediaBox().GetHeight()));
destinationArray.Add(new PdfNumber(1));
pdfDoc.AddNamedDestination(destinationKey, destinationArray);
//Add TOC line with bookmark
Paragraph p = new Paragraph();
p.AddTabStops(new TabStop(540, TabAlignment.RIGHT, new DottedLine()));
p.Add(entry.Key);
p.Add(new Tab());
p.Add((pdfDoc.GetNumberOfPages() - 1).ToString());
p.SetProperty(Property.ACTION, PdfAction.CreateGoTo(destinationKey));
document.Add(p);
}
firstSourcePdf.Close();
Here we go:
-
Line 1: we create a
PdfDocumentwith the source file containing all the info about all the nominations. -
Line 2: we loop over an alphabetic list of the nominations for "The Revenant".
-
Line 4-5: we get the page that corresponds with the nomination, and we add a copy to the
PdfDocument. -
Line 7: we create an iText
Textelement containing the page number. We subtract 1 from that page number, because the first page in our document is the unnumbered page containing the TOC. -
Line 8: we set the background color to
Color.WHITE. This will cause an opaque white rectangle to be drawn with the same size of theText. We do this to cover the original page number. -
Line 9: we add this
textat a fixed position on the the current page in thePdfDocument. The fixed position is: X = 549, Y = 742, and the width of the text is 100 user units. -
Line 11: we create a key we'll use to name the destination.
-
Line 12-17: we create a
PdfArraycontaining information about the destination. We'll refer to the page we've just added (line 15), we'll define the destination using an X,Y coordinate and a zoom factor (line 16), we add the values of X (line 17), Y (line 18), and the zoom factor (line 19). -
Line 18: we add the named destination to the
PdfDocument. -
Line 20: we create an empty
Paragraph. -
Line 21: we add a tab stop at position X = 540, we define that the tab needs to be right aligned, and the space preceding the tab needs to be a
DottedLine. -
Line 22: we add the nomination to the
Paragraph. -
Line 23: we introduce a
Tab. -
Line 24: we add the page number minus 1 (because the page with the TOC is page 0).
-
Line 25: we add an action that will be triggered when someone clicks on the
Paragraph. -
Line 26: we add the
Paragraphto thedocument. -
Line 28: we close the source document.
We've been introducing a lot of new functionality that really requires a more in-depth tutorial, but we're looking at this example for one main reason: to show that there's a significant difference between the PdfDocument object, to which a new page is added with every pass through the loop, and the Document object, to which we keep adding Paragraph objects on the first page.
Let's go through some of these steps one more time to add the checklist.
//Add the last page
PdfDocument secondSourcePdf = new PdfDocument(new PdfReader(SRC2));
PdfPage page_1 = secondSourcePdf.GetPage(1).CopyTo(pdfDoc);
pdfDoc.AddPage(page_1);
//Add destination
PdfArray destinationArray_1 = new PdfArray();
destinationArray_1.Add(page_1.GetPdfObject());
destinationArray_1.Add(PdfName.XYZ);
destinationArray_1.Add(new PdfNumber(0));
destinationArray_1.Add(new PdfNumber(page_1.GetMediaBox().GetHeight()));
destinationArray_1.Add(new PdfNumber(1));
pdfDoc.AddNamedDestination("checklist", destinationArray_1);
//Add TOC line with bookmark
Paragraph p_1 = new Paragraph();
p_1.AddTabStops(new TabStop(540, TabAlignment.RIGHT, new DottedLine()));
p_1.Add("Oscars\u00ae 2016 Movie Checklist");
p_1.Add(new Tab());
p_1.Add((pdfDoc.GetNumberOfPages() - 1).ToString());
p_1.SetProperty(Property.ACTION, PdfAction.CreateGoTo("checklist"));
document.Add(p_1);
secondSourcePdf.Close();
// close the document
document.Close();
This code snippet adds the check list with the overview of all the nominations. An extra line saying "Oscars® 2016 Movie Checklist" is added to the TOC.
This example introduces a couple of new concepts for educational purposes. It shouldn't be used in a real-world application, because it contains a major flaw. We make the assumption that the TOC will consist of only one page. Suppose that we added more lines to the document object, then you would see a strange phenomenon: the text that doesn't fit on the first page, would be added on the second page. This second page wouldn't be a new page, it would be the first page that we added in the loop. In other words: the content of the first imported page would be overwritten. This is a problem that can be fixed, but it's outside the scope of this short introductory tutorial.
We'll finish this chapter with some examples in which we merge forms.
Merging forms
Merging forms is special. In HTML, it's possible to have more than one form in a single HTML file. That's not the case for PDF. In a PDF file, there can be only one form. If you want to merge two forms and you want to preserve the forms, you need to use a special method and a special IPdfPageExtraCopier implementation.
Figure 6.9 shows the combination of two different forms, subscribe.pdf and state.pdf
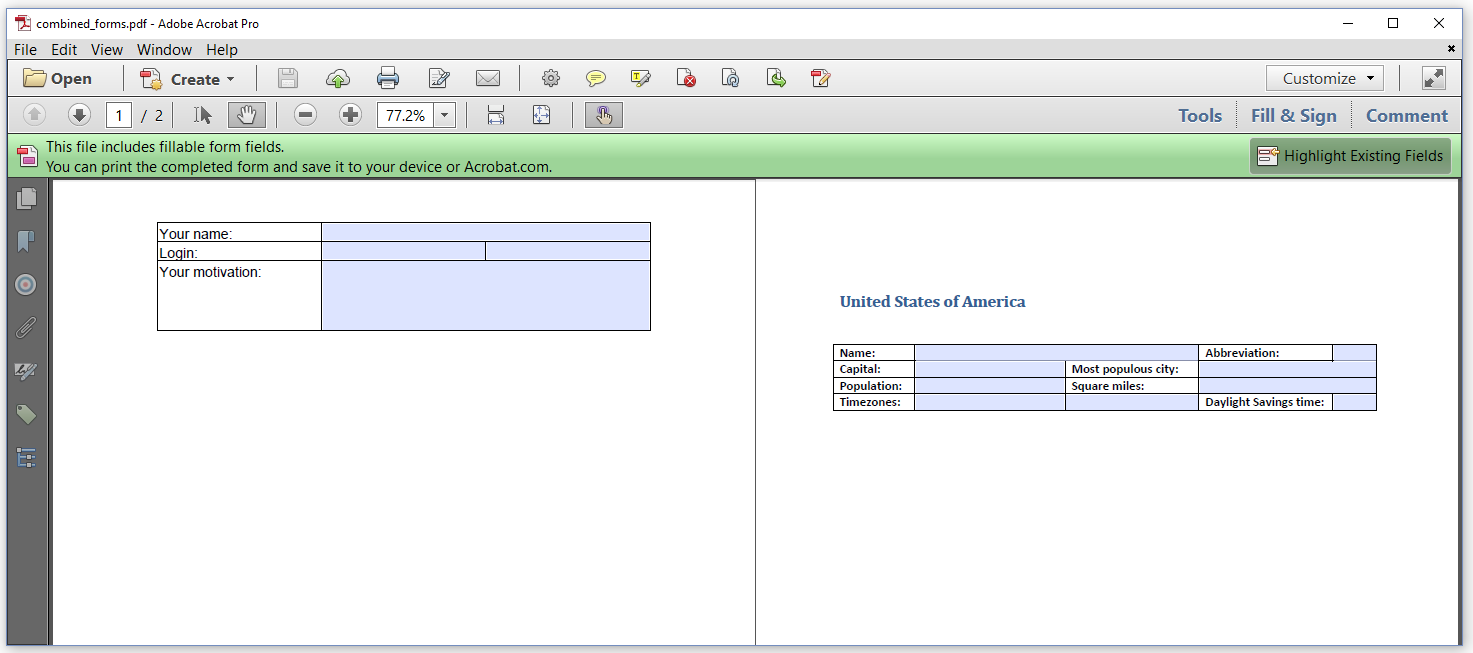
The Combine_Forms example is different from what we had before.
PdfDocument destPdfDocument = new PdfDocument(new PdfWriter(dest));
PdfDocument[] sources = new PdfDocument[] { new PdfDocument(new PdfReader(SRC1)), new PdfDocument(new PdfReader
(SRC2)) };
PdfPageFormCopier formCopier = new PdfPageFormCopier();
foreach (PdfDocument sourcePdfDocument in sources) {
sourcePdfDocument.CopyPagesTo(1, sourcePdfDocument.GetNumberOfPages(), destPdfDocument, formCopier);
sourcePdfDocument.Close();
}
destPdfDocument.Close();
In this code snippet, we use the copyPageTo() method. The first two parameters define the from/to range for the pages of the source document. The third parameter defines the destination document. The fourth parameter indicates that we are copying forms and that the two different forms in the two different documents should be merged into a single form. PdfPageFormCopier is an implementation of the IPdfPageExtraCopier interface that makes sure that the two different forms are merged into one single form.
Merging two forms isn't always trivial, because the name of each field needs to be unique. Suppose that we would merge the same form twice. Then we would have two widget annotations for each field. A field with a specific name, for instance "name", can be visualized using different widget annotations, but it can only have one value. Suppose that you would have a widget annotation for the field "name" on page one, and a widget annotation for the same field on page two, then changing the value shown in the widget annotation on one page would automatically also change the value shown in the widget annotations on the other page.
In the next example, we are going to fill out and merge the same form, state.pdf, as many times as there are entries in the CSV file united_states.csv; see Figure 6.10.
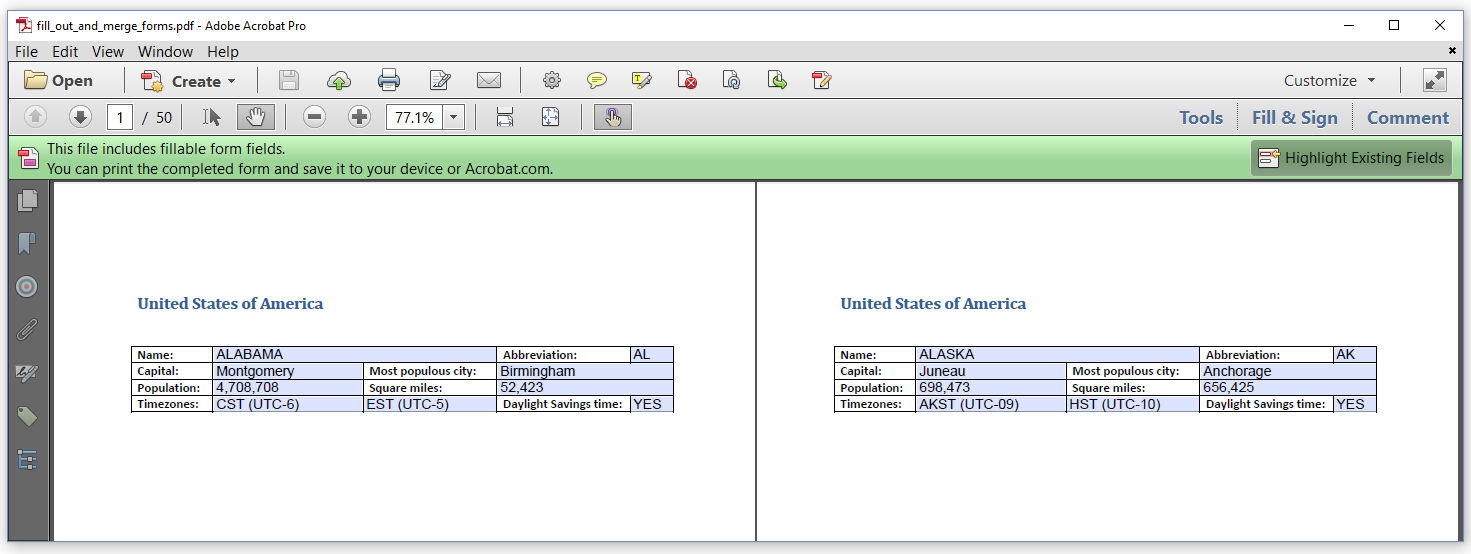
If we'd keep the names of the fields the way they are in the original form, changing the value of the state "ALABAMA" into "CALIFORNIA", would also change the name "ALASKA" on the second page, and the name of all the other states on the other pages. We made sure that this doesn't happen by renaming all the fields before merging the forms.
Let's take a look at the FillOutAndMergeForms example.
PdfDocument pdfDocument = new PdfDocument(new PdfWriter(dest));
PdfPageFormCopier formCopier = new PdfPageFormCopier();
StreamReader sr = File.OpenText(DATA);
String line;
bool headerLine = true;
int i = 1;
while ((line = sr.ReadLine()) != null) {
if (headerLine) {
headerLine = false;
continue;
}
ByteArrayOutputStream baos = new ByteArrayOutputStream();
PdfDocument sourcePdfDocument = new PdfDocument(new PdfReader(SRC), new PdfWriter(baos));
//Rename fields
i++;
PdfAcroForm form = PdfAcroForm.GetAcroForm(sourcePdfDocument, true);
form.RenameField("name", "name_" + i);
//Removed repeated lines ...
form.RenameField("dst", "dst_" + i);
//Fill out fields
StringTokenizer tokenizer = new StringTokenizer(line, ";");
IDictionary<String, PdfFormField> fields = form.GetFormFields();
PdfFormField toSet;
fields.TryGetValue("name_" + i, out toSet);
toSet.SetValue(tokenizer.NextToken());
//Removed repeated lines
fields.TryGetValue("dst_" + i, out toSet);
toSet.SetValue(tokenizer.NextToken());
sourcePdfDocument.Close();
sourcePdfDocument = new PdfDocument(new PdfReader(new MemoryStream(baos.ToArray())));
//Copy pages
sourcePdfDocument.CopyPagesTo(1, sourcePdfDocument.GetNumberOfPages(), pdfDocument, formCopier);
sourcePdfDocument.Close();
}
sr.Close();
pdfDocument.Close();
Let's start by looking at the code inside the while loop. We're looping over the different states of the USA stored in a CSV file (line 7). We skip the first line that contains the information for the column headers (line 8-10). The next couple of lines are interesting. So far, we've always been writing PDF files to disk. In this example, we are creating PDF files in memory using a ByteArrayOutputStream (line 12-13).
As mentioned before, we start by renaming all the fields. We get the PdfAcroForm instance (line 16) and we use the renameField() method to rename fields such as "name" to "name_1", "name_2", and so on. Note that we've skipped some lines for brevity in the code snippet. Once we've renamed all the fields, we set their value (line 22-28).
When we close the sourcePdfDocument (line 29), we have a complete PDF file in memory. We create a new sourcePdfDocument using a ByteArrayInputStream created with that file in memory (line 31). We can now copy the pages of that new sourcePdfDocument to our destination pdfDocument.
This is a rather artificial example, but it's a good example to explain some of the usual pitfalls when merging forms:
-
Without the
PdfPageFormCopier, the forms won't be correctly merged. -
One field can only have one value, no matter how many times that field is visualized using a widget annotation.
A more common use case, is to fill out and flatten the same form multiple times in memory, simultaneously merging all the resulting documents in one PDF.
Merging flattened forms
Figure 6.11 shows two PDF documents that were the result of the same procedure: we filled out a form in memory as many times as there are states in the USA. We flattened these filled out forms, and we merged them into one single document.
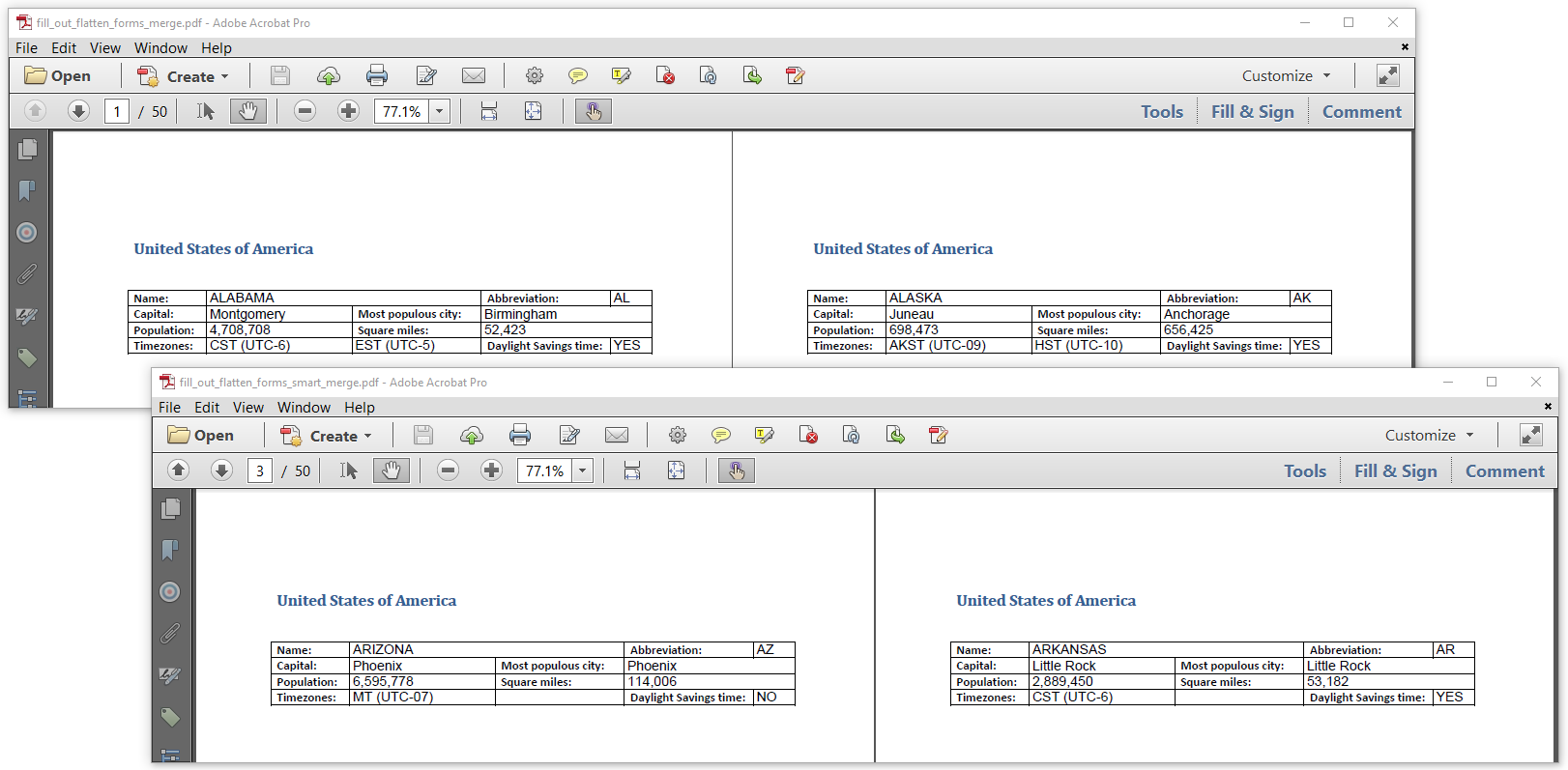
From the outside, these documents look identical, but if we look at their file size in Figure 12, we see a huge difference.

What is causing this difference in file size? We need to take a look at the FillOutFlattenAndMergeForms example to find out.
PdfDocument destPdfDocument = new PdfDocument(new PdfWriter(dest1));
//Smart mode
PdfDocument destPdfDocumentSmartMode = new PdfDocument(new PdfWriter(dest2).SetSmartMode(true));
StreamReader sr = File.OpenText(DATA);
String line;
bool headerLine = true;
int i = 0;
while ((line = sr.ReadLine()) != null) {
if (headerLine) {
headerLine = false;
continue;
}
ByteArrayOutputStream baos = new ByteArrayOutputStream();
PdfDocument sourcePdfDocument = new PdfDocument(new PdfReader(SRC), new PdfWriter(baos));
//Read fields
PdfAcroForm form = PdfAcroForm.GetAcroForm(sourcePdfDocument, true);
StringTokenizer tokenizer = new StringTokenizer(line, ";");
IDictionary<String, PdfFormField> fields = form.GetFormFields();
//Fill out fields
PdfFormField toSet;
fields.TryGetValue("name", out toSet);
toSet.SetValue(tokenizer.NextToken());
//Removed repeated lines...
fields.TryGetValue("dst", out toSet);
toSet.SetValue(tokenizer.NextToken());
//Flatten fields
form.FlattenFields();
sourcePdfDocument.Close();
sourcePdfDocument = new PdfDocument(new PdfReader(new MemoryStream(baos.ToArray())));
//Copy pages
sourcePdfDocument.CopyPagesTo(1, sourcePdfDocument.GetNumberOfPages(), destPdfDocument, null);
sourcePdfDocument.CopyPagesTo(1, sourcePdfDocument.GetNumberOfPages(), destPdfDocumentSmartMode, null);
sourcePdfDocument.Close();
}
sr.Close();
destPdfDocument.Close();
destPdfDocumentSmartMode.Close();
In this code snippet, we create two documents simultaneously:
-
The
destPdfDocumentinstance (line 1) is created the same way we've been creatingPdfDocumentinstances all along. -
The
destPdfDocumentSmartModeinstance (line 3) is also created that way, but we've turned on the smart mode.
We loop over the lines of the CSV file like we did before (line 8), but since we're going to flatten the forms, we no longer have to rename the fields. The fields will be lost due to the flattening process anyway. We create a new PDF document in memory (line 13-14) and we fill out the fields (line 16-25). We flatten the fields (line 27) and close the document created in memory (line 26). We use the file created in memory to create a new source file. We add all the pages of this source file to the two PdfDocumentinstances, one working in normal mode, the other in smart mode. We no longer need to use a PdfPageFormCopier instance, because the forms have been flattened; they are no longer forms.
What is the difference between these normal and smart modes?
-
When we copy the pages of the filled out forms to the
PdfDocumentworking in normal mode, thePdfDocumentprocesses each document as if it's totally unrelated to the other documents that are being added. In this case, the resulting document will be bloated, because the documents are related: they all share the same template. That template is added to the PDF document as many times as there are states in the USA. In this case, the result is a file of about 12 MBytes. -
When we copy the pages of the filled out forms to the
PdfDocumentworking in smart mode, thePdfDocumentwill take the time to compare the resources of each document. If two separate documents share the same resources (e.g. a template), then that resource is copied to the new file only once. In this case, the result can be limited to 365 KBytes.
Both the 12 MBytes and the 365 KBytes files look exactly the same when opened in a PDF viewer or when printed, but it goes without saying that the 365 KBytes files is to be preferred over the 12 MBytes file.
Summary
In this chapter, we've been scaling, tiling, N-upping one file with a different file as result. We've also assembled files in many different ways. We discovered that there are quite some pitfalls when merging interactive forms. Much more remains to be said about reusing content from existing PDF documents.
In the next chapter, we'll discuss PDF documents that comply to special PDF standards such as PDF/UA and PDF/A. We'll discover that merging PDF/A documents also requires some special attention.