In this chapter, we'll change two of the most important internal mechanisms of the pdfHTML add-on.
-
We'll override the default functionality that matches HTML tags with iText objects, more specifically the
DefaultTagWorkerFactory(Java/.NET) mechanism, and -
We'll override the default functionality that matches CSS styles to iText styles, more specifically the
DefaultCssApplierFactory(Java/.NET) mechanism.
Some of the examples will be rather artificial, but by examining them, you'll get a better insight into the inner workings of pdfHTML.
Changing the behavior of a tag
Up until now, we've always implicitly used the DefaultTagWorkerFactory (Java/.NET) class. This is a class that implements the ITagWorkerFactory (Java/.NET) interface. There is a single method in this factory interface: getTagWorker(IElementNode tag, ProcessorContext context)/GetTagWorker(IElementNode tag, ProcessorContext context).
-
The
IElementNode(Java/.NET) object can give you information about the tag that is being processed (e.g. the name of the tag); -
The
ProcessorContext(Java/.NET) can give you access to thePdfDocument(Java/.NET) and several other converter properties.
This getTagWorker()/GetTagWorker() method returns an ITagWorker (Java/.NET) instance.
The DefaultTagWorkerFactory (Java/.NET) implements the getTagWorker()/GetTagWorker() method, and uses the DefaultTagWorkerMapping object to map the name of a tag to an ITagWorker (Java/.NET) instance. This mapping is stored in a TagProcessorMapping (Java/.NET) instance.
These are some examples of the default tag worker mapping:
-
The
<span>-tag is mapped to theSpanTagWorker(Java/.NET) class, -
The
<a>-tag is mapped to theATagWorker(Java/.NET) class, which extends theSpanTagWorker(Java/.NET) class, -
The
<b>-tag and<i>-tag are also mapped to theSpanTagWorker(Java/.NET) class. Those tags are considered to be special types of<span>tags. -
And so on.
PTagWorker (Java/.NET), SpanTagWorker (Java/.NET), ATagWorker (Java/.NET) and so on all implement the ITagWorker (Java/.NET) interface, more specifically, they implement the following four methods:
-
processContent()/ProcessContent()– processes whatever text content is present inside the open and close tag of the element,
-
processTagChild()/ProcessTagChild()– processes the other tags nested inside the open and close tag of the element,
-
processEnd()/ProcessEnd()– contains code that is executed after everything else is processed, and
-
getElementResult()/GetElementResult()– can be used to retrieve the final result, an
IPropertyContainer(Java/.NET) instance.
These tag worker classes are responsible for creating and populating iText objects. For instance: the PTagWorker (Java/.NET) class has a Paragraph (Java/.NET) object as a member-variable. When a <p> tag is encountered, the following steps take place:
-
An instance of the
Paragraph(Java/.NET) member-variable is created in the constructor of thePTagWorker(Java/.NET) object, -
Content is gathered in the processContent()/ProcessContent() and processTagChild()/ProcessTagChild() methods,
-
the
Paragraph(Java/.NET) is finalized in the processEnd()/ProcessEnd() method, and -
the finalized
Paragraph(Java/.NET) is returned by the getElementResult()/GetElementResult() method.
In the C05E01_ATagAsSpan.java example, we will take an example from chapter 2 (the 2_inline_css.html HTML file), but we'll change the tag worker factory in such a way that the <a>-tag is treated as a <span> tag. Figure 5.1 shows the resulting PDF.
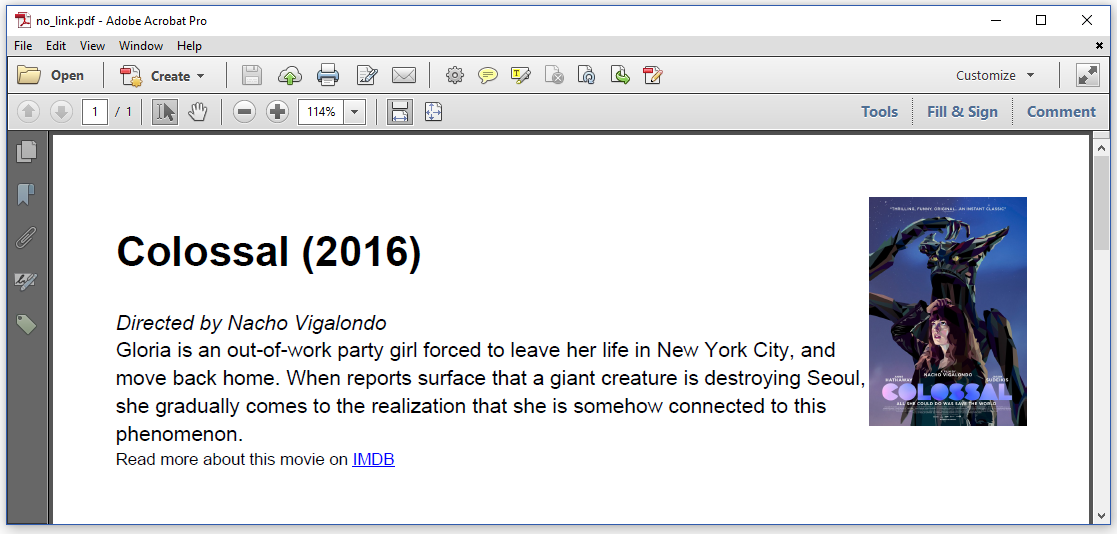
This document looks exactly like the result we had in chapter 2, but when we try clicking the IMDB link in the actual PDF, nothing happens. The link in the HTML isn't a link in the PDF anymore because we changed the default tag worker factory with the setTagWorkerFactory()/SetTagWorkerFactory() method of the ConverterProperties (Java/.NET):
public void createPdf(String src, String dest) throws IOException {
ConverterProperties converterProperties = new ConverterProperties();
converterProperties.setTagWorkerFactory(
new DefaultTagWorkerFactory() {
@Override
public ITagWorker getCustomTagWorker(
IElementNode tag, ProcessorContext context) {
if ("a".equalsIgnoreCase(tag.name()) ) {
return new SpanTagWorker(tag, context);
}
return null;
}
} );
HtmlConverter.convertToPdf(new File(src), new File(dest), converterProperties);
}
public void CreatePdf(string src, string dest)
{
ConverterProperties properties = new ConverterProperties();
properties.SetTagWorkerFactory(new CustomTagWorkerFactory());
HtmlConverter.ConvertToPdf(new FileInfo(src), new FileInfo(dest), properties);
}
class CustomTagWorkerFactory : DefaultTagWorkerFactory
{
public override ITagWorker GetCustomTagWorker(IElementNode tag, ProcessorContext context)
{
if ("a".Equals(tag.Name(), StringComparison.OrdinalIgnoreCase))
{
return new SpanTagWorker(tag, context);
}
return null;
}
}
We could, of course, create a completely new implementation of the ITagWorkerFactory (Java/.NET) interface, but that would be a tremendous work. We want to benefit from as much existing pdfHTML functionality as possible, so that tags such as <div>, <h1>, and so on, are rendered correctly.
We can do so by reusing the functionality that is already present in the DefaultTagWorkerFactory (Java/.NET). The DefaultTagWorkerFactory (Java/.NET) has a method named getCustomTagWorker()/GetCustomTagWorker() that always returns null. This method is always the first method that is invoked by the DefaultTagWorkerFactory's (Java/.NET) implementation of the getTagWorker()/GetTagWorker() method.
-
If the getCustomTagWorker()/GetCustomTagWorker() method returns
null–which is always the case unless you override the method–, then the default tag worker mapping is used. For instance: if an<a>-tag is encountered, anATagWorker(Java/.NET) instance is returned. -
If the getCustomTagWorker()/GetCustomTagWorker() method doesn't return
null–which can be the case in our "overridden" version of theDefaultTagWorkerFactory(Java/.NET)-, the default mapping is ignored. For instance: if an<a>-tag is encountered in our example, aSpanTagWorker(Java/.NET) instance is returned instead of theATagWorker(Java/.NET) you'd expect.
We didn't override any CSS appliers (yet), which explains why the word IMDB is underlined and rendered in blue, but since we treat the <a>-tag as if it were a <span>-tag from a functional and structural point of view, no link is added. This example was written to explain the inner workings of pdfHTML. What we have done in this first example could easily be perceived as the introduction of a bug.
This doesn't mean that there aren't any useful use cases. We could for instance extend the DefaultTagWorkerFactory (Java/.NET) to support custom tags.
Introducing custom tags
Suppose that we want to send an invitation letter to different people. We create this invitation letter in HTML (see invitation.html), but we have introduced two custom tags that aren't real, existing HTML syntax: <name> and <date>:
<html>
<head>
<title>Invitation to SXSW 2018</title>
</head>
<body>
<u><b>Re: Invitation</b></u>
<br>
<p>Dear <name>SXSW visitor</name>,
we hope you had a great SXSW film festival experience last year.
And we would like to invite you to the next edition of SXSW Film
that takes place from March 9 until March 17, 2018.</p>
<p>Sincerely,<br>
The SXSW crew<br>
<date>August 4, 2017</date></p>
</body>
</html>
We convert this HTML file to PDF in the C05E02_Invitation.java example using the createPdf()/CreatePdf() method:
public void createPdf(String src, String dest) throws IOException {
HtmlConverter.convertToPdf(new File(src), new File(dest));
}
public void CreatePdf(string src, string dest)
{
HtmlConverter.ConvertToPdf(new FileInfo(src), new FileInfo(dest));
}
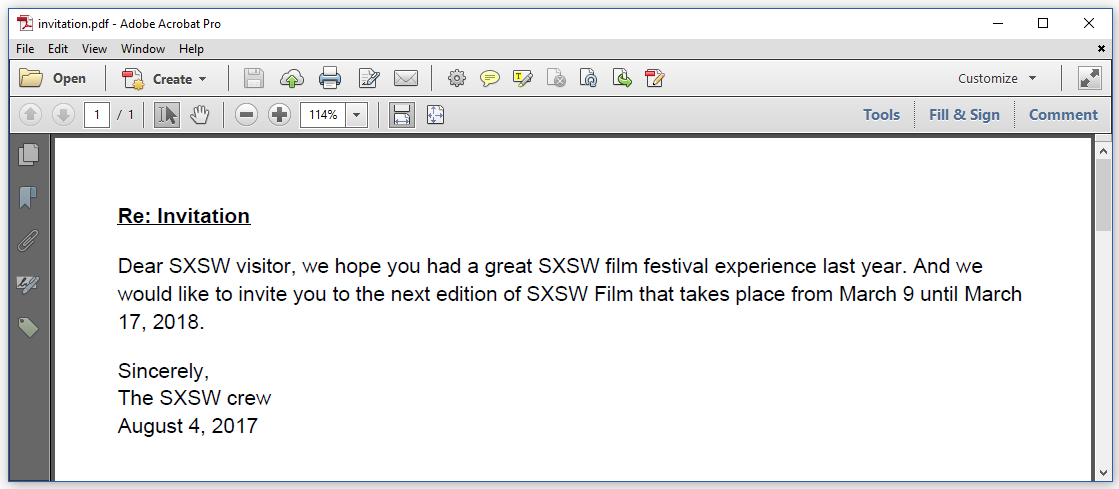
If we examine figure 5.2, we see "SXSW visitor" and "August 4, 2017" as regular text. There is no apparent difference with the rest of the content. The unknown tags are treated as ordinary <span> tags.
In the main() method of the C05E03_Invitations.java example, we take the same HTML file, but we use it to create three different PDF files:
String[] names = {"Bruno Lowagie", "Ingeborg Willaert", "John Doe"};
int counter = 1;
for (String name : names) {
app.createPdf(name, SRC, String.format(DEST, counter++));
}
string[] names = {"Bruno Lowagie", "Ingeborg Willaert", "John Doe"};
int counter = 1;
foreach (string name in names)
{
CreatePdf(name, SRC, string.Format(DEST, counter++));
}
In the createPdf()/CreatePdf() method of this adapted example, we now create a variation on the DefaultTagWorkerFactory (Java/.NET) that returns a SpanTagWorker (Java/.NET) for the tags <name> and <date>. We override the processContent()/ProcessContent() method of these SpanTagWorker (Java/.NET) instances so that the actual content (content) is ignored. Instead a name or today's date are passed as content.
public void createPdf(String name, String src, String dest) throws IOException {
SimpleDateFormat sdf = new SimpleDateFormat("MMMM d, yyyy", Locale.ENGLISH);
ConverterProperties converterProperties = new ConverterProperties();
converterProperties.setTagWorkerFactory(
new DefaultTagWorkerFactory() {
@Override
public ITagWorker getCustomTagWorker(
IElementNode tag, ProcessorContext context) {
if ("name".equalsIgnoreCase(tag.name()) ) {
return new SpanTagWorker(tag, context) {
@Override
public boolean processContent(
String content, ProcessorContext context) {
return super.processContent(name, context);
}
};
}
else if ("date".equalsIgnoreCase(tag.name()) ) {
return new SpanTagWorker(tag, context) {
@Override
public boolean processContent(
String content, ProcessorContext context) {
return super.processContent(
sdf.format(new Date()), context);
}
};
}
return null;
}
} );
HtmlConverter.convertToPdf(new File(src), new File(dest), converterProperties);
}
public void CreatePdf(string name, string src, string dest)
{
ConverterProperties properties = new ConverterProperties();
properties.SetTagWorkerFactory(new CustomTagWorkerFactory(name));
HtmlConverter.ConvertToPdf(new FileInfo(src), new FileInfo(dest), properties);
}
class CustomTagWorkerFactory : DefaultTagWorkerFactory
{
private string name = "";
public CustomTagWorkerFactory2(string name)
{
this.name = name;
}
public override ITagWorker GetCustomTagWorker(IElementNode tag, ProcessorContext context)
{
if ("name".Equals(tag.Name(), StringComparison.OrdinalIgnoreCase))
{
return new CustomSpanTagWorker(tag, context, name);
}
if ("date".Equals(tag.Name(), StringComparison.OrdinalIgnoreCase))
{
return new CustomSpanTagWorker2(tag, context);
}
return null;
}
class CustomSpanTagWorker : SpanTagWorker
{
private string name = "";
public CustomSpanTagWorker(IElementNode element, ProcessorContext context, string name) : base(element,
context)
{
this.name = name;
}
public override bool ProcessContent(string content, ProcessorContext context)
{
return base.ProcessContent(name, context);
}
}
class CustomSpanTagWorker2 : SpanTagWorker
{
public CustomSpanTagWorker2(IElementNode element, ProcessorContext context) : base(element, context)
{
}
public override bool ProcessContent(string content, ProcessorContext context)
{
return base.ProcessContent(DateTime.Now.ToString("MMMM d, yyyy",
new CultureInfo("en-US")), context);
}
}
}
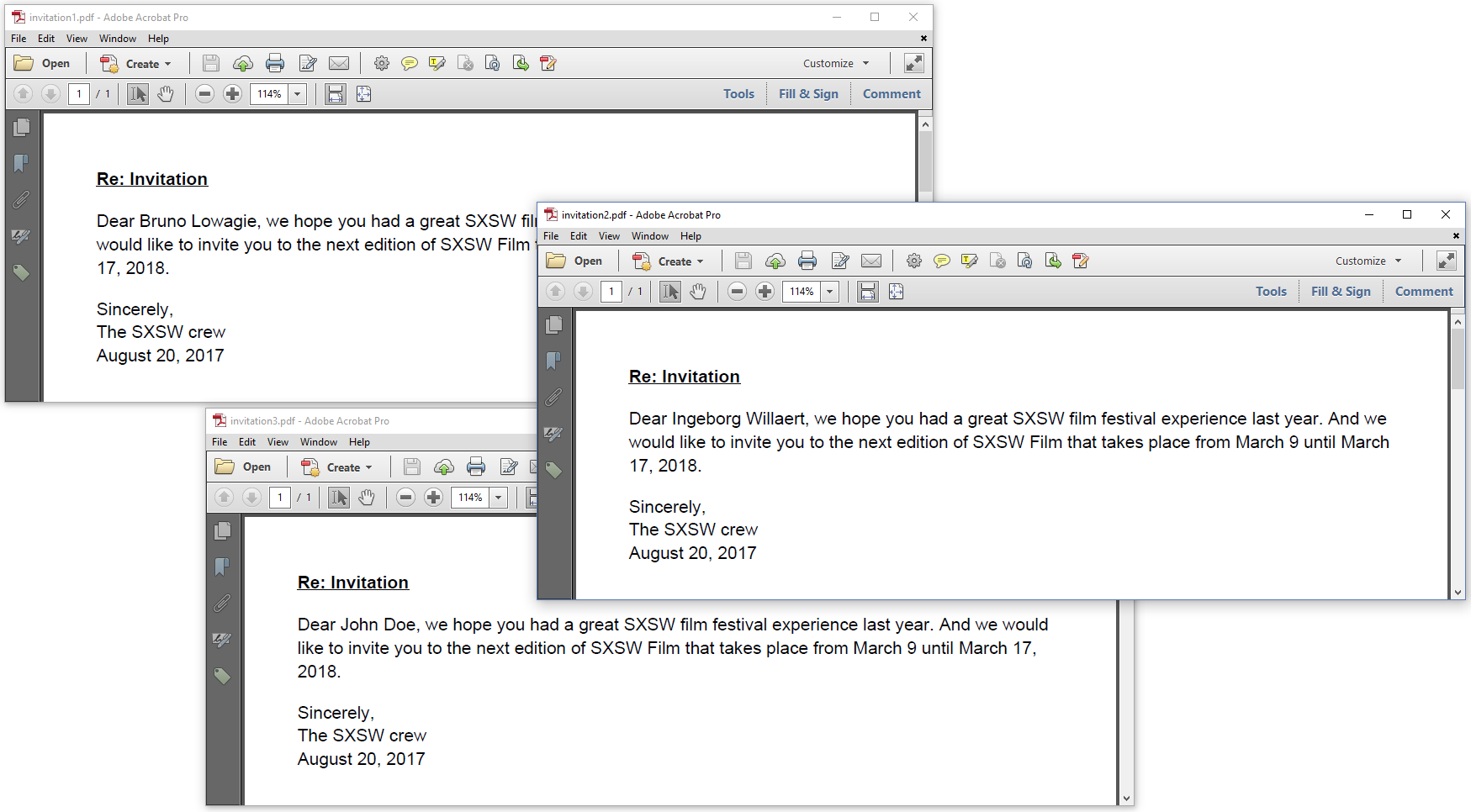
This code will cause the default content ("SXSW visitor" and "August 4, 2017") to be replaced by specific names and today's date. See figure 5.3 for the resulting PDFs.
In some cases, it won't be possible to reuse one of the existing pdfHTML ITagWorker (Java/.NET) implementations. We'll have to create our own tag worker.
Creating your own ITagWorker implementation
Suppose that we want to create a PDF document that shows a QR code, for instance based on the following qrcode.html HTML file:
<html>
<head>
<meta charset="UTF-8">
<title>QRCode Example</title>
<link rel="stylesheet" type="text/css" href="css/qrcode.css"/>
</head>
<body>
<h1>SXXpress codes</h1>
<p>Bruno Lowagie has a South by Express pass for the following movies:
<p>Colossal</p>
<qr charset="Cp437" errorcorrection="Q">
Film: Colossal; Date: Friday, March 10; Time: 6:15 PM; Place: Alamo Lamar D
</qr>
<p>Mr. Roosevelt</p>
<qr charset="Cp437" errorcorrection="L">
Film: Mr. Roosevelt; Date: Sunday, March 12; Time: 2:15 PM; Place: Paramount Theatre
</qr>
</body>
</html>
There is no such thing as a <qr>-tag in HTML, so when we open this HTML file in a browser, we only see the text. However, we can use this HTML file to create a PDF document with QR codes instead of the text. See figure 5.4.
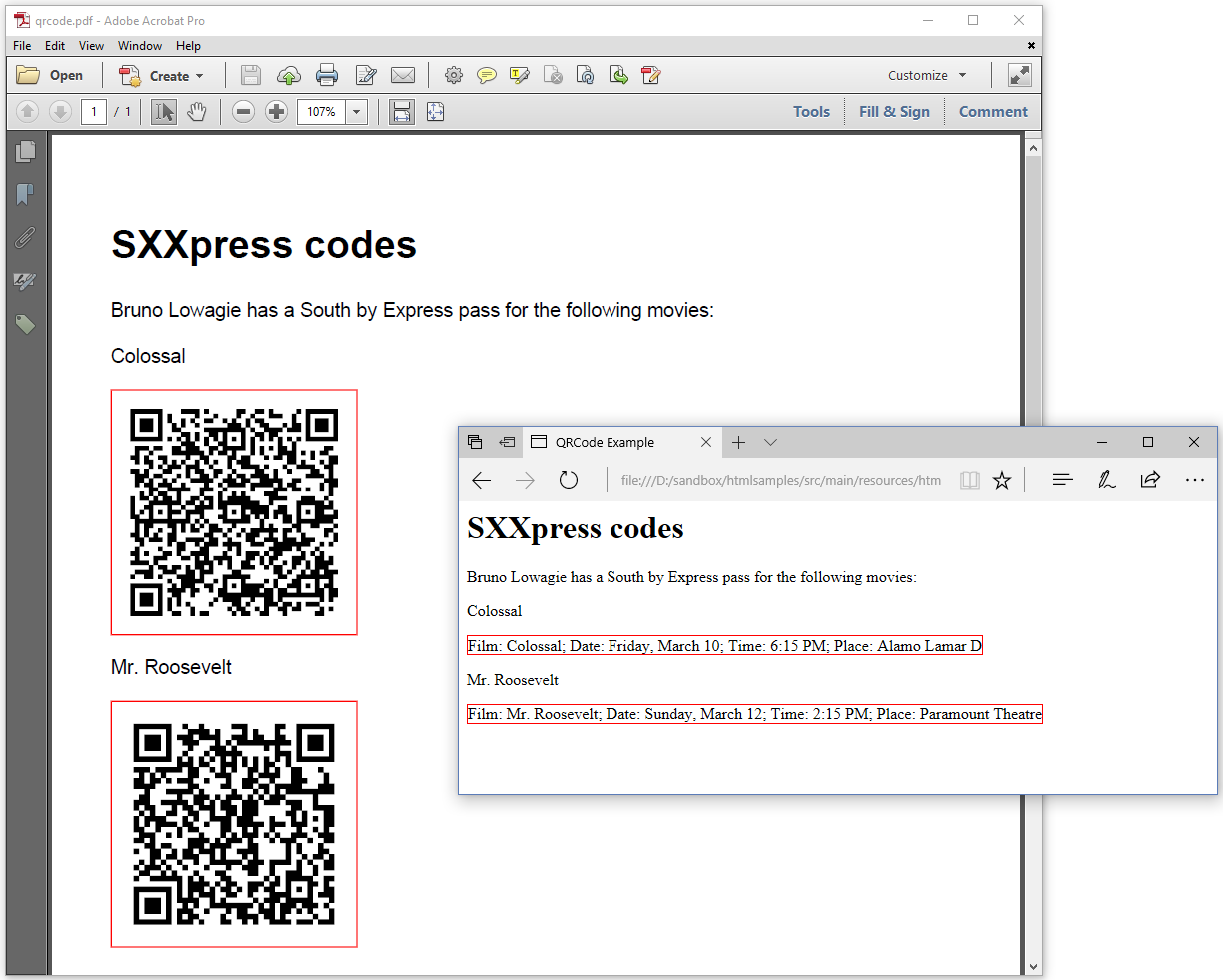
The text in the HTML file has a red border because that's how we defined the style of the <qr>-tag in the qrcode.css CSS file:
qr {
border:solid 1px red;
height:200px;
width:200px;
}
Now let's examine the C05E04_QRCode.java example to see how the PDF with the QR Code bar codes was created.
This time, we create a QRCodeTagWorkerFactory that extends the DefaultTagWorkerFactory (Java/.NET) class:
class QRCodeTagWorkerFactory extends DefaultTagWorkerFactory {
@Override
public ITagWorker getCustomTagWorker(IElementNode tag, ProcessorContext context) {
if(tag.name().equals("qr")){
return new QRCodeTagWorker(tag, context);
}
return null;
}
}
public override ITagWorker GetCustomTagWorker(IElementNode tag, ProcessorContext context)
{
if (tag.Name().Equals("qr", StringComparison.OrdinalIgnoreCase))
return new QRCodeTagWorker(tag, context);
return null;
}
If a <qr>-tag is encountered, we map it to a QRCodeTagWorker. This QRCodeTagWorker needs to implement the ITagWorker (Java/.NET) interface:
static class QRCodeTagWorker implements ITagWorker {
private static String[] allowedErrorCorrection =
{"L","M","Q","H"};
private static String[] allowedCharset =
{"Cp437","Shift_JIS","ISO-8859-1","ISO-8859-16"};
private BarcodeQRCode qrCode;
private Image qrCodeAsImage;
public QRCodeTagWorker(IElementNode element, ProcessorContext context){
Map<EncodeHintType, Object> hints = new HashMap<>();
String charset = element.getAttribute("charset");
if(checkCharacterSet(charset)){
hints.put(EncodeHintType.CHARACTER_SET, charset);
}
String errorCorrection = element.getAttribute("errorcorrection");
if(checkErrorCorrectionAllowed(errorCorrection)){
ErrorCorrectionLevel errorCorrectionLevel =
getErrorCorrectionLevel(errorCorrection);
hints.put(EncodeHintType.ERROR_CORRECTION, errorCorrectionLevel);
}
qrCode = new BarcodeQRCode("placeholder",hints);
}
@Override
public boolean processContent(String content, ProcessorContext context) {
qrCode.setCode(content);
return true;
}
@Override
public boolean processTagChild(
ITagWorker childTagWorker, ProcessorContext context) {
return false;
}
@Override
public void processEnd(IElementNode element, ProcessorContext context) {
qrCodeAsImage = new Image(qrCode.createFormXObject(context.getPdfDocument()));
}
@Override
public IPropertyContainer getElementResult() {
return qrCodeAsImage;
}
private static boolean checkErrorCorrectionAllowed(String toCheck){
for(int i = 0; i<allowedErrorCorrection.length;i++){
if(toCheck.toUpperCase().equals(allowedErrorCorrection[i])){
return true;
}
}
return false;
}
private static boolean checkCharacterSet(String toCheck){
for(int i = 0; i<allowedCharset.length;i++){
if(toCheck.equals(allowedCharset[i])){
return true;
}
}
return false;
}
private static ErrorCorrectionLevel getErrorCorrectionLevel(String level){
switch(level) {
case "L":
return ErrorCorrectionLevel.L;
case "M":
return ErrorCorrectionLevel.M;
case "Q":
return ErrorCorrectionLevel.Q;
case "H":
return ErrorCorrectionLevel.H;
}
return null;
}
}
class QRCodeTagWorker : ITagWorker
{
private static string[] allowedErrorCorrection =
{"L", "M", "Q", "H"};
private static string[] allowedCharSets =
{"Cp437", "Shift_JIS", "ISO-8859-1", "ISO-8859-16"};
private BarcodeQRCode qrCode;
private Image qrCodeAsImage;
public QRCodeTagWorker(IElementNode tag, ProcessorContext context)
{
IDictionary hints = new Dictionary();
string charset = tag.GetAttribute("charset");
if (CheckCharSet(charset))
{
hints.Add(EncodeHintType.CHARACTER_SET, charset);
}
string errorCorrection = tag.GetAttribute("errorcorrection");
if (CheckErrorCorrectionAllowed(errorCorrection))
{
ErrorCorrectionLevel errorCorrectionLevel = getErrorCorrectionLevel(errorCorrection);
hints.Add(EncodeHintType.ERROR_CORRECTION, errorCorrectionLevel);
}
}
public void ProcessEnd(IElementNode element, ProcessorContext context)
{
qrCodeAsImage = new Image(qrCode.CreateFormXObject(context.GetPdfDocument()));
}
public bool ProcessContent(string content, ProcessorContext context)
{
qrCode.SetCode(content);
return true;
}
public bool ProcessTagChild(ITagWorker childTagWorker, ProcessorContext context)
{
return false;
}
public IPropertyContainer GetElementResult()
{
return qrCodeAsImage;
}
private static bool CheckCharSet(string toValidate)
{
foreach (string charset in allowedCharSets)
{
if (toValidate.Equals(charset, StringComparison.OrdinalIgnoreCase))
{
return true;
}
}
return false;
}
private static ErrorCorrectionLevel getErrorCorrectionLevel(string lvl)
{
switch (lvl)
{
case "L":
return ErrorCorrectionLevel.L;
case "M":
return ErrorCorrectionLevel.M;
case "Q":
return ErrorCorrectionLevel.Q;
case "H":
return ErrorCorrectionLevel.H;
}
return null;
}
private bool CheckErrorCorrectionAllowed(string toValidate)
{
foreach (string errorcorrection in allowedErrorCorrection)
{
if (toValidate.Equals(errorcorrection, StringComparison.OrdinalIgnoreCase))
{
return true;
}
}
return false;
}
}
The static String arrays are possible values for hints that can be passed to the constructor of the BarcodeQRCode class. If you look at the qrcode.html HTML file, you can see that we pass these values using the attributes charset and errorcorrection.
We see two member-variables, one is a BarcodeQRCode instance; the other an Image (Java/.NET) instance. The BarcodeQRCode object is a low-level object that knows how to draw a QR code, but eventually, we'll need a result that is an instance of the IPropertyContainer (Java/.NET) interface. To get such a result, we'll wrap the bar code inside an Image (Java/.NET) object. Rest assured: this operation won't change the QR code into a raster image; it won't reduce the resolution and legibility of the QR code. The Image (Java/.NET) class is perfectly capable of storing vector images such as bar codes created with iText's barcode functionality.
After this, we have the constructor of our custom QR code tag worker. In this constructor, we first create a Map/Dictionary with "hints". We retrieve the value of these hints from the attributes of the <qr>-tag. We retrieve the charset and we retrieve the errorcorrection. We only accept allowed values, which we check with the checkCharacterSet()/CheckCharSet() and the checkErrorCorrectionAllowed()/CheckErrorCorrectionAllowed() method. We convert the errorcorrection level attribute to an ErrorCorrectionLevel using the getErrorCorrectionLevel() method. Once we've processed the attributes, we create a BarcodeQRCode instance. Since we don't know the content of the barcode yet, we use "placeholder" as value for the code.
We replace this "placeholder" by the actual content in the processContent()/ProcessContent() method. We don't expect the <qr>-tag to have any nested tags, hence the processTagChild()/ProcessTagChild() method can simply return false. At the end of the process, in the processEnd() method, we wrap the qrCode object in an Image (Java/.NET) object. As opposed to the BarcodeQRCode object, the Image (Java/.NET) class implements the IPropertyContainer (Java/.NET) interface. We return this IPropertyContainer (Java/.NET) object in the getElementResult()/GetElementResult()method.
We have successfully implemented the four methods of the ITagWorker (Java/.NET) interface, and we can now use this QRCodeTagWorker in our custom QRCodeTagWorkerFactory.
We use this custom QRCodeTagWorkerFactory as one of the ConverterProperties (Java/.NET) in the createPdf()/CreatePdf() method:
public void createPdf(String src, String dest) throws IOException {
ConverterProperties properties = new ConverterProperties();
properties
.setCssApplierFactory(new QRCodeTagCssApplierFactory())
.setTagWorkerFactory(new QRCodeTagWorkerFactory());
HtmlConverter.convertToPdf(new File(src), new File(dest), properties);
}
public void CreatePdf(string src, string dest)
{
ConverterProperties properties = new ConverterProperties();
properties.SetCssApplierFactory(new QRCodeTagCssApplierFactory())
.SetTagWorkerFactory(new QRCodeTagWorkerFactory());
HtmlConverter.ConvertToPdf(new FileInfo(src), new FileInfo(dest), properties);
}
As you can tell from this snippet, we use the setTagWorkerFactory()/SetTagWorkerFactory() method to extend the tag processing mechanism, but we also used the setCssApplierFactory()/SetCssApplierFactory() method to extend the CSS functionality.
This is necessary in this example, because we defined a border color, a width, and a height for the <qr>-tag using CSS. However, since <qr> is a custom tag, iText doesn't know which implementation of the ICssApplier (Java/.NET) to use when such a tag is encountered. We can easily fix this by overriding the getCustomCssApplier()/GetCustomCssApplier() method of the DefaultCssApplierFactory (Java/.NET) class:
class QRCodeTagCssApplierFactory extends DefaultCssApplierFactory {
@Override
public ICssApplier getCustomCssApplier(IElementNode tag) {
if (tag.name().equals("qr")) {
return new BlockCssApplier();
}
return null;
}
}
class QRCodeTagCssApplierFactory : DefaultCssApplierFactory
{
public override ICssApplier GetCustomCssApplier(IElementNode tag)
{
if (tag.Name().Equals("qr", StringComparison.OrdinalIgnoreCase))
{
return new BlockCssApplier();
}
return null;
}
}
In this code snippet, we tell iText that whenever a <qr>-tag is encountered, we need to treat this tag as a block element. We simply reuse the BlockCssApplier (Java/.NET) that is used for block elements such as <div>, <p>, <blockquote>, and so on. You can inspect the source code of the DefaultTagCssApplierMapping for a complete overview of the default ICssApplier (Java/.NET) mapping.
In the next couple of examples, we'll create custom CSS appliers.
Creating custom CSS appliers
In the previous example, we extended the DefaultCssApplierFactory (Java/.NET) to add a BlockCssApplier (Java/.NET) for the <qr>-tag. In the next example, we'll create our own ICssApplier (Java/.NET) implementation.
In this rather artificial example, we'll take the sxsw.html HTML file from chapter 3, and we'll override the CSS applier for all <div>-elements. We'll ignore all the styles for these elements, except the background. If a background color is defined for a <div>-element, we'll replace the actual value with a gray value (#dddddd). See figure 5.5.
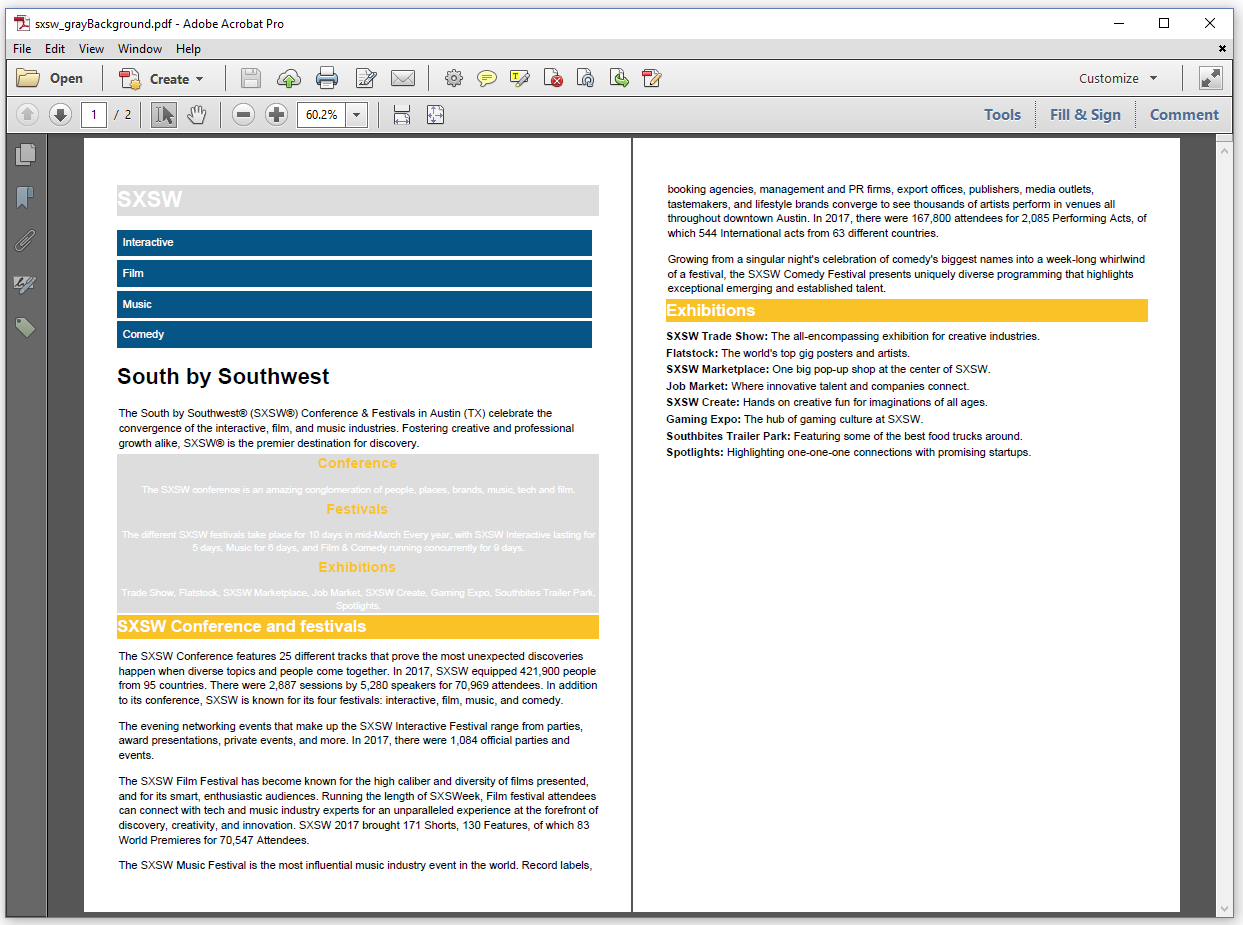
The ICssApplier (Java/.NET) interface has a single method, named apply()/Apply(). In the C05E05_GrayBackground.java example, we implement this method like this:
class GrayBackgroundBlockCssApplier implements ICssApplier {
public void apply(ProcessorContext context,
IStylesContainer stylesContainer, ITagWorker tagWorker){
Map<String, String> cssProps = stylesContainer.getStyles();
IPropertyContainer container = tagWorker.getElementResult();
if (container != null && cssProps.containsKey(CssConstants.BACKGROUND_COLOR)) {
cssProps.put(CssConstants.BACKGROUND_COLOR, "#dddddd");
BackgroundApplierUtil.applyBackground(cssProps, context, container);
}
}
}
class GrayBackgroundBlockCssApplier : ICssApplier
{
public void Apply(ProcessorContext context, IStylesContainer stylesContainer, ITagWorker tagWorker)
{
IDictionary cssProps = stylesContainer.GetStyles();
IPropertyContainer container = tagWorker.GetElementResult();
if (container != null && cssProps.ContainsKey(CssConstants.BACKGROUND_COLOR))
{
cssProps.Add(CssConstants.BACKGROUND_COLOR, "#dddddd");
BackgroundApplierUtil.ApplyBackground(cssProps, context, container);
}
}
}
If there is a background color, we replace that color with #dddddd, and we apply the background to the container with the BackgroundApplierUtil (Java/.NET) class. You can still see elements with a colored background in the resulting PDF. That's because those backgrounds were defined in the context of an <h2> or an <li> element, and our custom ICssApplier (Java/.NET) is only used for <div> elements.
In the next example, we are going to use some "Dutch CSS" to define colors. Since there is no such thing as "Dutch CSS", we're going to extend the DefaultCssApplierFactory (Java/.NET) to support this fictitious CSS functionality.
Implementing your own custom CSS
The dutch_css.html HTML file is a variation on the files we used in chapter 2, but there is something peculiar about it. It uses a Dutch version of CSS:
<html>
<head>
<title>Colossal</title>
<meta name="description" content="Gloria is an out-of-work party girl..." />
</head>
<body>
<img src="img/colossal.jpg" style="width: 120px;float: right" />
<h1 style="achtergrond: rood; kleur: wit;">Colossal (2016)</h1>
<div style="font-style: italic; kleur: blauw;">Directed by Nacho Vigalondo</div>
<div style="kleur: groen;">
Gloria is an out-of-work party girl forced to leave her life in New York City,
and move back home. When reports surface that a giant creature is
destroying Seoul, she gradually comes to the realization that she is
somehow connected to this phenomenon.
</div>
<div style="font-size: 0.8em">Read more about this movie on
<a href="www.imdb.com/title/tt4680182">IMDB</a></div>
</body>
</html>
Do you see how we defined the colors in this HTML file? We used achtergrond instead of background, kleur instead of color, and we used the colors wit, rood, groen, and blauw. Obviously, this is not going to work in a browser, but we can make it work when we convert the HTML to PDF. See figure 6.6.
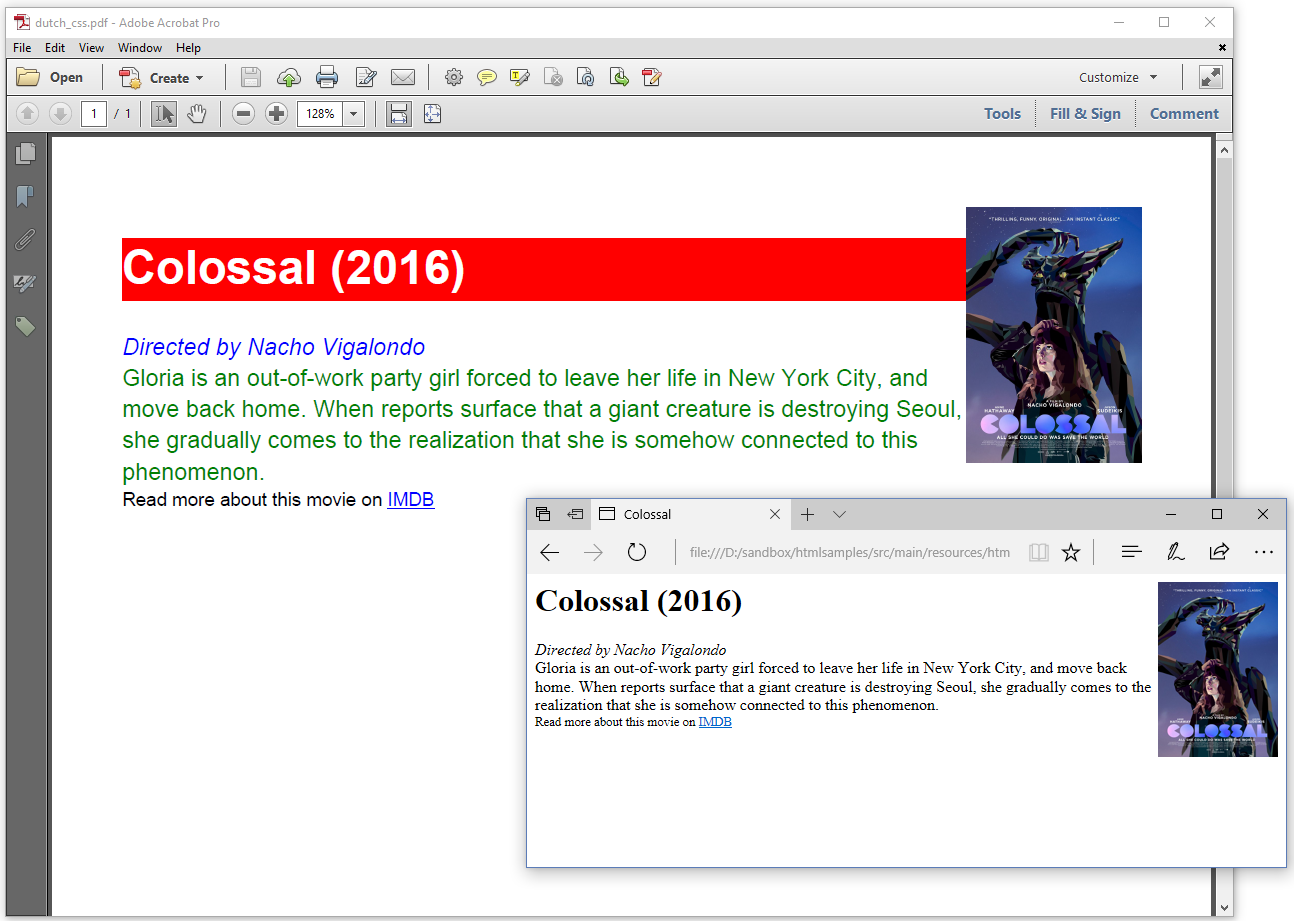
To achieve this, we mapped Dutch names of colors to English color names in the C05E06_DutchCss.java example:
public static final Map<String, String> KLEUR = new HashMap<String, String>();
static {
KLEUR.put("wit", "white");
KLEUR.put("zwart", "black");
KLEUR.put("rood", "red");
KLEUR.put("groen", "green");
KLEUR.put("blauw", "blue");
}
public static IDictionary KLEUR = new Dictionary();
static Chapter5()
{
KLEUR.Add("wit", "white");
KLEUR.Add("zwart", "black");
KLEUR.Add("rood", "red");
KLEUR.Add("groen", "green");
KLEUR.Add("blauw", "blue");
}
We also extended the BlockCssApplier (Java/.NET) class:
class DutchColorCssApplier extends BlockCssApplier {
@Override
public void apply(ProcessorContext context,
IStylesContainer stylesContainer, ITagWorker tagWorker){
Map<String, String> cssStyles = stylesContainer.getStyles();
if(cssStyles.containsKey("kleur")){
cssStyles.put(CssConstants.COLOR,
KLEUR.get(cssStyles.get("kleur")));
stylesContainer.setStyles(cssStyles);
}
if(cssStyles.containsKey("achtergrond")){
cssStyles.put(CssConstants.BACKGROUND_COLOR,
KLEUR.get(cssStyles.get("achtergrond")));
stylesContainer.setStyles(cssStyles);
}
super.apply(context, stylesContainer,tagWorker);
}
}
class DutchColorCssApplier : BlockCssApplier
{
public override void Apply(ProcessorContext context, IStylesContainer stylesContainer, ITagWorker tagWorker)
{
IDictionary cssStyles = stylesContainer.GetStyles();
if (cssStyles.ContainsKey("kleur"))
{
cssStyles.Add(CssConstants.COLOR, KLEUR["kleur"]);
stylesContainer.SetStyles(cssStyles);
}
if (cssStyles.ContainsKey("achtergrond"))
{
cssStyles.Add(CssConstants.BACKGROUND_COLOR, KLEUR["achtergrond"]);
stylesContainer.SetStyles(cssStyles);
}
base.Apply(context, stylesContainer, tagWorker);
}
}
Whenever we encounter the Dutch CSS property "kleur", we translate its value to English, and set this value as a color property. Whenever we encounter the Dutch CSS property achtergrond, we translate its value to English, and we set this value as the background property. For all the other CSS property, we rely on their implementation in the BlockCssApplier (Java/.NET) class.
We'll use this DutchColorCssApplier for every <h1>- and <div>-tag:
public void createPdf(String src, String dest) throws IOException {
ConverterProperties converterProperties = new ConverterProperties();
converterProperties.setCssApplierFactory(new DefaultCssApplierFactory() {
ICssApplier dutchCssColor = new DutchColorCssApplier();
@Override
public ICssApplier getCustomCssApplier(IElementNode tag) {
if(tag.name().equals(TagConstants.H1)
|| tag.name().equals(TagConstants.DIV)){
return dutchCssColor;
}
return null;
}
});
HtmlConverter.convertToPdf(new File(src), new File(dest), converterProperties);
}
public void CreatePdf(string src, string dest)
{
ConverterProperties properties = new ConverterProperties();
properties.SetCssApplierFactory(new CustomCssApplierFactory());
HtmlConverter.ConvertToPdf(new FileInfo(src), new FileInfo(dest), properties);
}
class CustomCssApplierFactory : DefaultCssApplierFactory
{
public override ICssApplier GetCustomCssApplier(IElementNode tag)
{
ICssApplier dutchCssApplier = new DutchColorCssApplier();
if (tag.Name().Equals(TagConstants.H1, StringComparison.OrdinalIgnoreCase) ||
tag.Name().Equals(TagConstants.DIV, StringComparison.OrdinalIgnoreCase))
{
return dutchCssApplier;
}
return null;
}
}
I leave it to your imagination in which use case this would actually be useful, but I hope that these examples provide some insights in the inner workings of pdfHTML, and at the same time prove that the pdfHTML add-on is highly extensible. Using the mechanisms described in this chapter, you can adapt pdfHTML to your own needs and requirements.
Summary
In this chapter, we changed the core functionality of the pdfHTML add-on by changing the way tags and CSS are interpreted. We (deliberately) introduced a bug that made an <a>-tag behave as if it were an ordinary <span>-tag. We introduced custom tags that served as placeholders for names, dates, and even QR Codes. We downgraded the CSS properties for <div>-tags so that every CSS property except the background would be ignored. Finally, we introduced Dutch CSS to define colors, and we made this CSS work in the HTML to PDF conversion process.
In the next chapter, we'll discuss a topic that is long overdue in this tutorial: fonts. So far, we've only used fonts such as Helvetica and FreeSans, but which other fonts can we use? We'll discover this in the next chapter.