The grouping selector was introduced back in version 2.1.9 of pdf2Data, though its functionality was extended with the addition of the JSON output support in iText pdf2Data 3.1.1.
Note that this article is the updated version for iText pdf2Data 4.0. If you are still using pdf2Data 2.*.* please see the original article.
Grouping is a flexible and powerful mechanism, which can be used in many use-cases. One of which we will demonstrate here.
Prerequisites
To get the most out of this article you should have
-
An understanding of how to build your own template and the pdf2Data Editor UI.
-
Deployed the pdf2data Editor, or have access to our trial instance.
Introduction
The grouping selector allows the grouping of a data field's values depending on its y coordinate related to the coordinates of another data field's values.
For now, the creation of this rule is available only in the Expert mode of the pdf2Data template editor, which is not actually as difficult as it sounds.
Create Data Fields
As you can see in the screenshot below we have two different invoices:
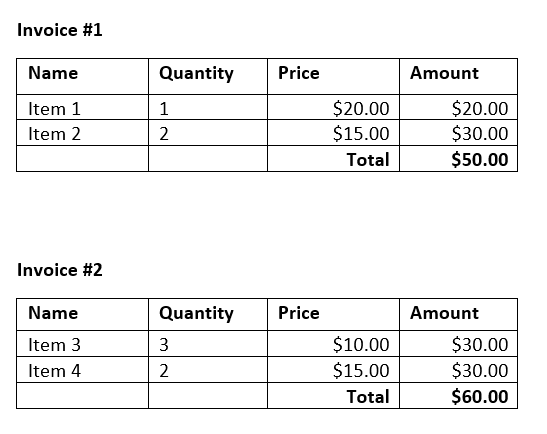
The extraction of the invoice numbers and their related total amounts is our goal here.
We will create 2 data fields (in the User mode):
-
InvoiceNumber.
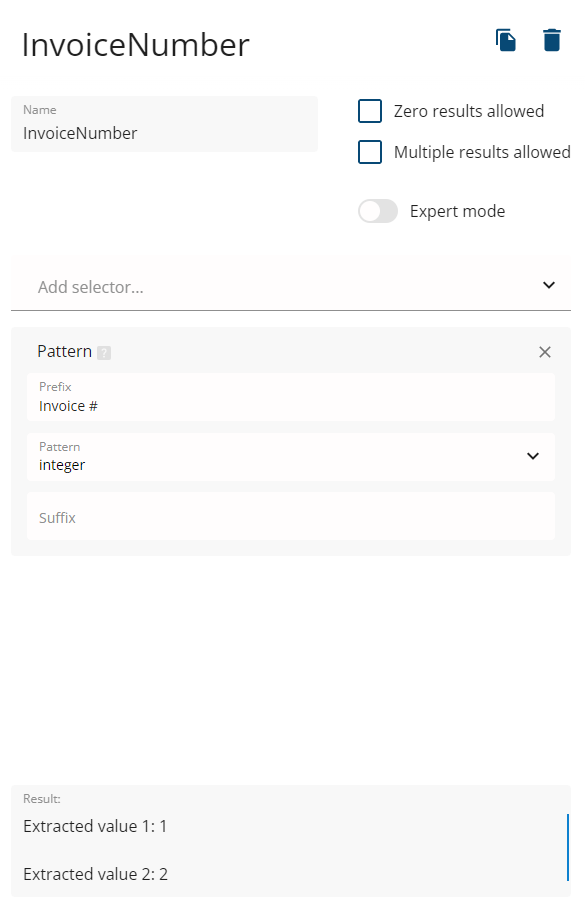
-
TotalAmount
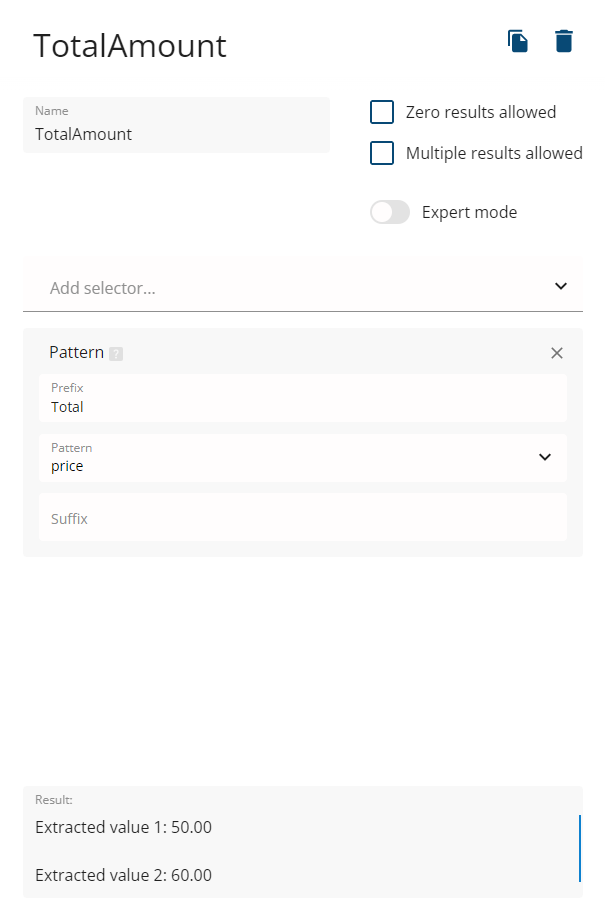
The output will have the following structure for both JSON and XML
InvoiceNumber : <ListOfAllInvoiceNumbersExtracted>
TotalAmount : <ListOfAllTotalAmountsExtracted>
XML
<elements>
<data name="InvoiceNumber">
<text>1</text>
<text>2</text>
</data>
<data name="TotalAmount">
<text>50.00</text>
<text>60.00</text>
</data>
</elements>
JSON
"data": [
{ "name": "InvoiceNumber",
"table": [ ],
"image": [ ],
"text": [
{"text": "1"},
{"text": "2"}
],
"group": [ ]
},
{ "name": "TotalAmount",
"table": [ ],
"image": [ ],
"text": [
{"text": "50.00"},
{"text": "60.00"}
],
"group": [ ]
}
]
}
To be honest though, this structure is not that useful for further processing.
Group Data Fields
A structure like the following, however:
<FirstInvoiceNumberExtracted> : <TotalAmount>,
<SecondInvoiceNumberExtracted> : <TotalAmount>
is much more useful from an integration perspective.
In our file, we can see that the Invoice word strictly separates the data field values, so we can use it as a value for the grouping selector.
We will create an auxiliary data field for a grouping of values, or you can use InvoiceNumber which gives you a slightly different output structure:
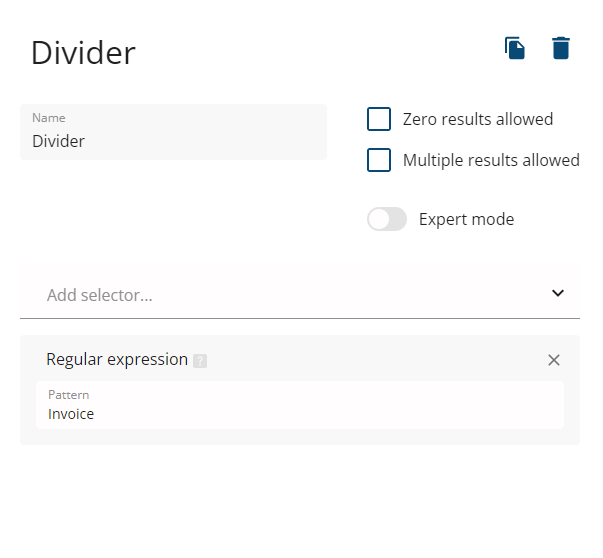
For both of our fields we need to add the Grouping selector and specify "Divider" as a grouping field.
And the output will be as follows:
XML
<elements>
<data name="Divider" grouped="true">
<group>
<text>Invoice</text>
<data name="InvoiceNumber">
<text>1</text>
</data>
<data name="TotalAmount">
<text>50.00</text>
</data>
</group>
<group>
<text>Invoice</text>
<data name="InvoiceNumber">
<text>2</text>
</data>
<data name="TotalAmount">
<text>60.00</text>
</data>
</group>
</data>
</elements>
JSON
{
"data": [
{
"name": "Divider",
"grouped": true,
"group": [
{
"text": {
"text": "Invoice"
},
"data": [
{
"name": "InvoiceNumber",
"text": [
{
"text": "1"
}
],
},
{
"name": "TotalAmount",
"text": [
{
"text": "50.00"
}
],
}
]
},
{
"text": {
"text": "Invoice"
},
"data": [
{
"name": "InvoiceNumber",
"text": [
{
"text": "2"
}
],
},
{
"name": "TotalAmount",
"text": [
{
"text": "60.00"
}
],
"group": [ ]
}
]
}
]
}
]
}
Next steps
You can use the attached template for mass handling of PDFs by native libraries for Java and .NET or command line interface or just play around with it in pdf2Data 3.0 Editor - pdf2Data Documentation
Resources