Previous part (Create an extraction template - pdf2Data Documentation)
Each data field in pdf2Data should have a bounding box (BBox) and at least one selector.
Note,
1. The BBox doesn't necessarily need to include the value that is being extracted by the parsing rule.
2. Always confirm changes of a data field by clicking the "Confirm" button. to update the extracted results,
Please see the Template Editor UI guide for details.
For this invoice, we can assume everybody wants to extract the following values from this invoice.
-
Invoice number
-
Invoice date
-
Due date
-
Total amount
-
Invoice items
-
Contractor's postal address
-
Bank details: Account number, Bank's SWIFT, Account name
-
QR code value
Let start from top to bottom.
Invoice number
Looking at the sample file, you will find the invoice number directly below the "Invoice #" string. We can assume that this will always be the case for any subsequent invoices from this contactor.

Paragraph selector
In cases when the required value can be found under a static string, the best approach for extraction is using the "Paragraph" selector.
The "paragraph name" parameter allows you to specify the line after which all data should be extracted as a paragraph.
In our case, the paragraph name is "Invoice #"
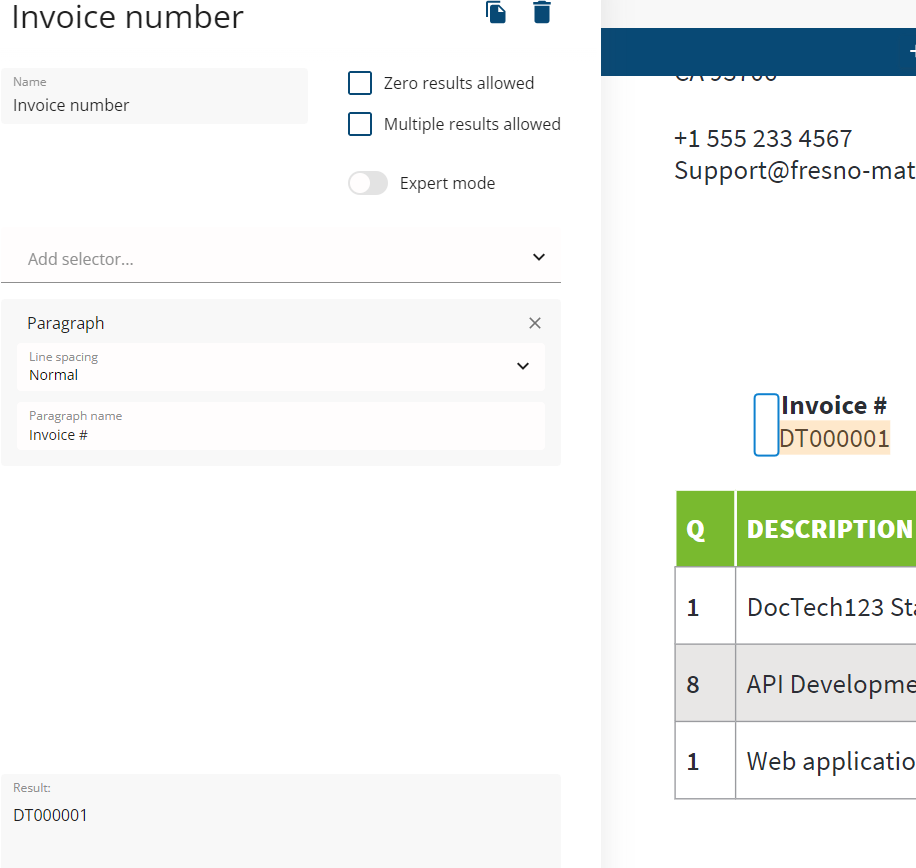
Paragraph is a BBox-independent selector.
Invoice date
It is true (at least in this case) that the same approach as we used for Invoice number would also work for the date fields in this invoice. You would just need to change the Paragraph name to "Invoice date" and "Due date" respectively.
However, it should be noted that iText pdf2Data contains a specific selector for dates. Therefore, we recommend using the "date" selector if you are going to extract calendar dates.
Date selector
In general terms, the date selector is suitable for extracting calendar dates in all formats, but a single data field can contain values in the same format only.
This selector defines the exact format to be recognized from the content of the BBox, while looking for matches both inside and outside
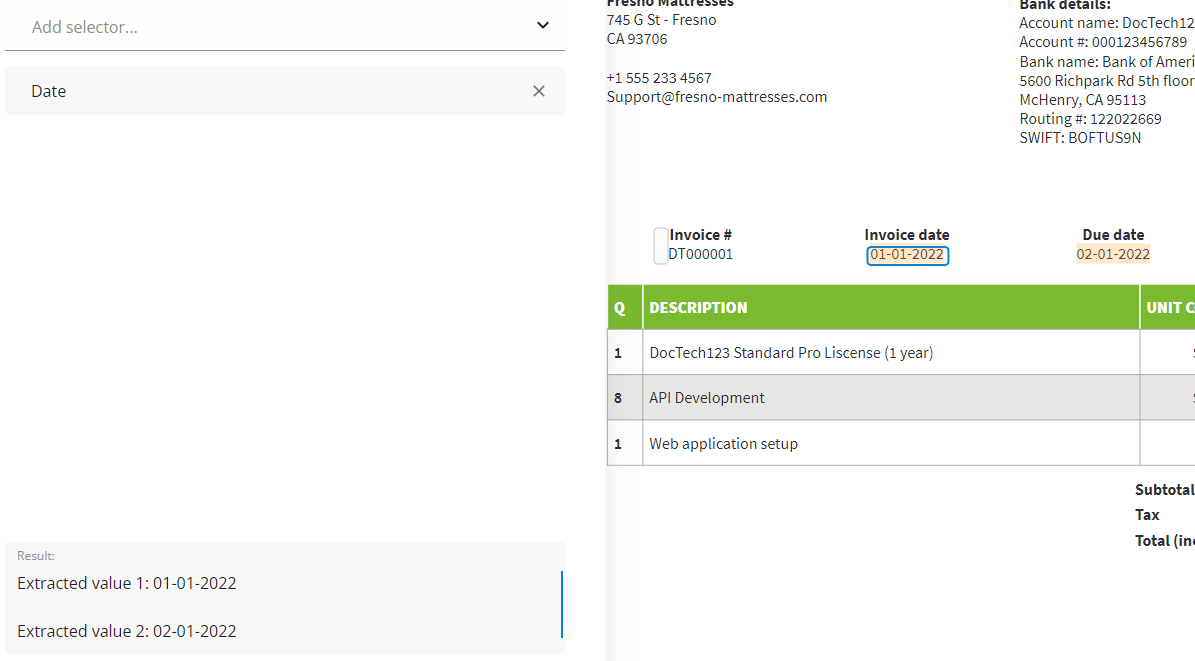
As you can see in the screenshot above, using the Date selector as a standalone selector will select all detected date values from the document (2 values for this sample).
We can filter out the unwanted output by adding another selector to the parsing pipeline.
Picker selector.
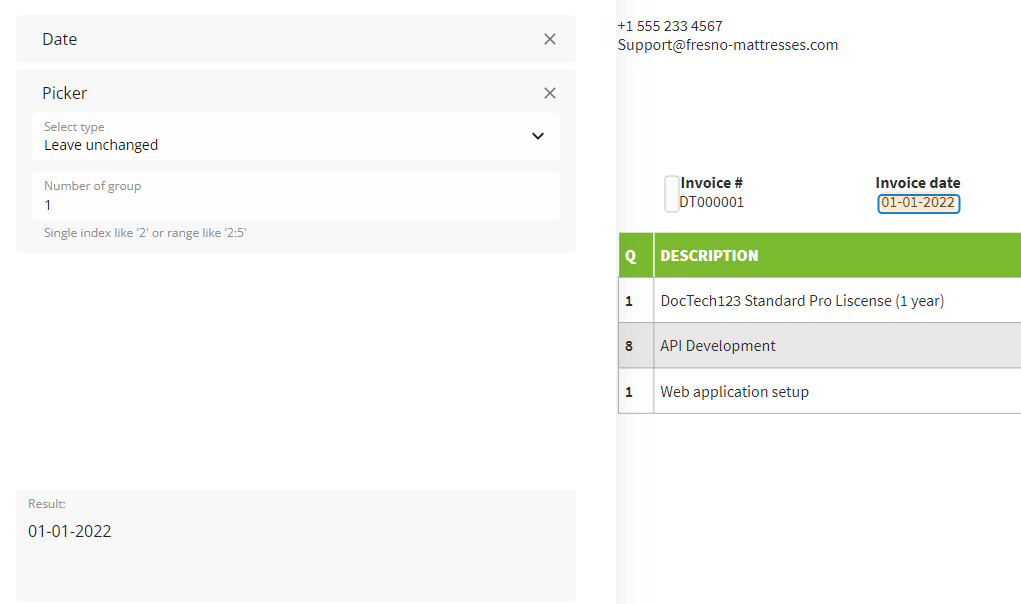
For the Invoice date field, you should pick the first element.
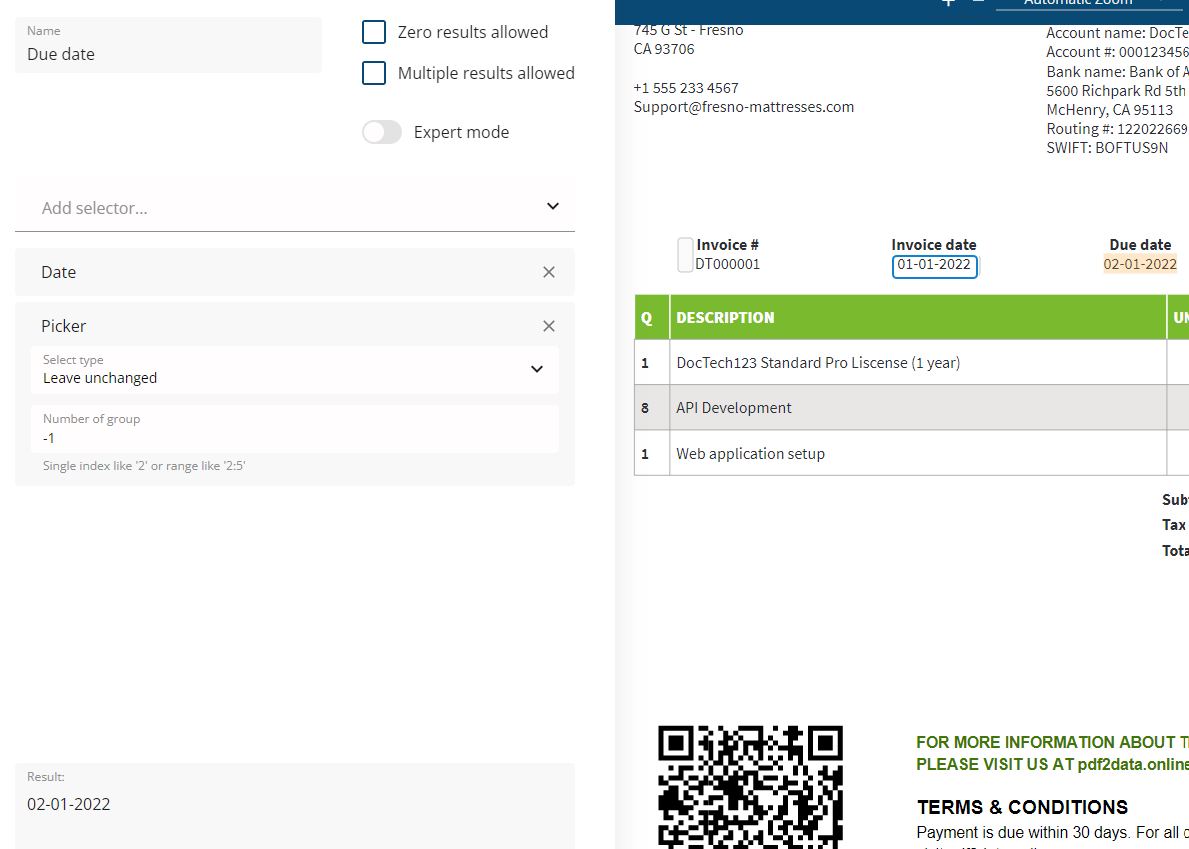
Due date
The parsing rule to return "Due date" is almost the same as for "Invoice date".
So you can use the "Clone data field" functionality, which is available while hovering over the data field name
As you remember, we picked the first value for the Invoice date. For "Due to" we need the second one, or the last one as this can be more convenient.
If you need to select a value using Picker from the end of the output, you can use negative numbers, e.g -1 for the last item.
Total amount
You can approach the extraction of the total amount value in a few different ways.
Pattern Selector
One way is to use the Pattern selector by specifying "Tax)" as a prefix:
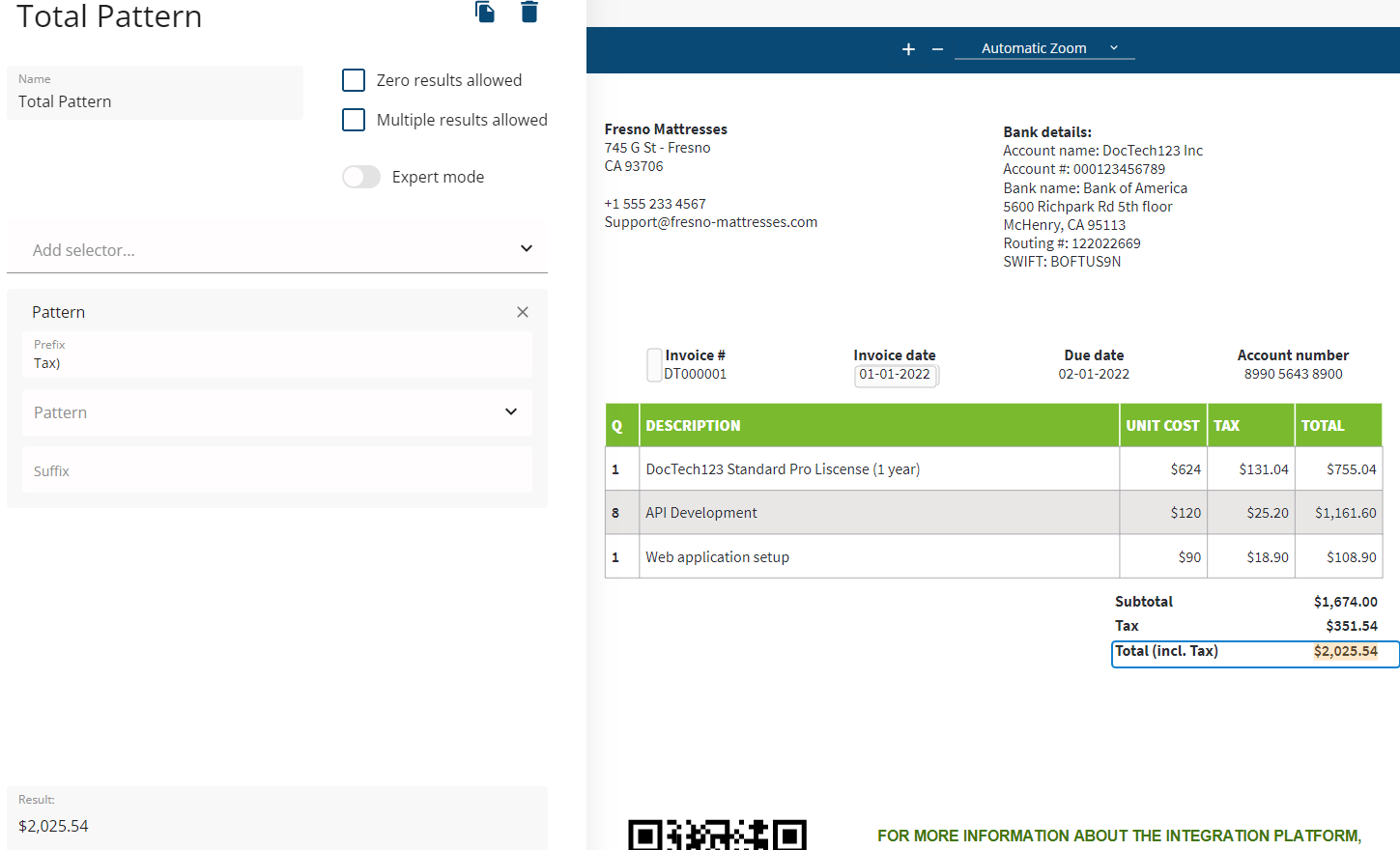
This will result in "$2,025.54" being extracted.
However, this approach has a few shortcomings:
-
it is a string value that contains a currency sign, so you will need to rid of this sign in the next step
-
in cases where the original PDF was an image, the text might be unreadable meaning even if the amount is correctly recognized, the result will not be extracted.
-
the supplier might change this text at some point (e.g., to "Total") meaning you would need to change your template.
While the first issue can be fixed by passing the selector output to the picker selector, the other two make your extraction template less flexible.
Therefore, we recommend you use the Price selector instead.
Price selector
The Price selector is designed specifically for the extraction of currency values, and returns a value without a currency sign.
It is highly likely that whatever changes the supplier may make to the the layout, the total amount will remain the very last price in a document.
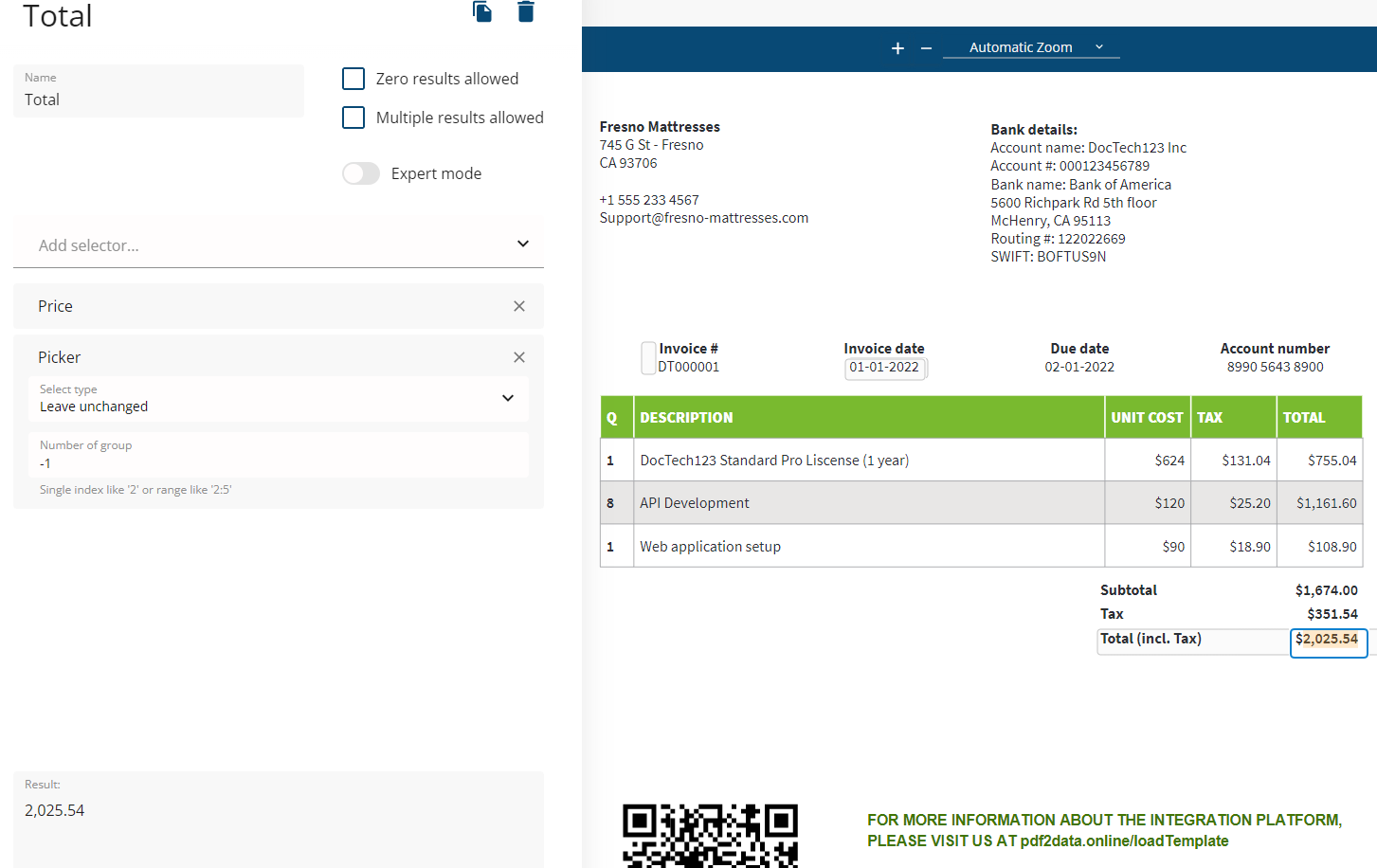
In the above screenshot there is a parsing pipeline that consists of two selectors.
1. Price selects all amounts from a PDF regardless of their positions related to the BBox.
Extracted values match the pattern that the price selector builds based on the content of the BBox.
2. Picker is configured to ignore all results except the last one (-1).
Invoice items.
Invoices usually contain a table with details of an order.
Table selector
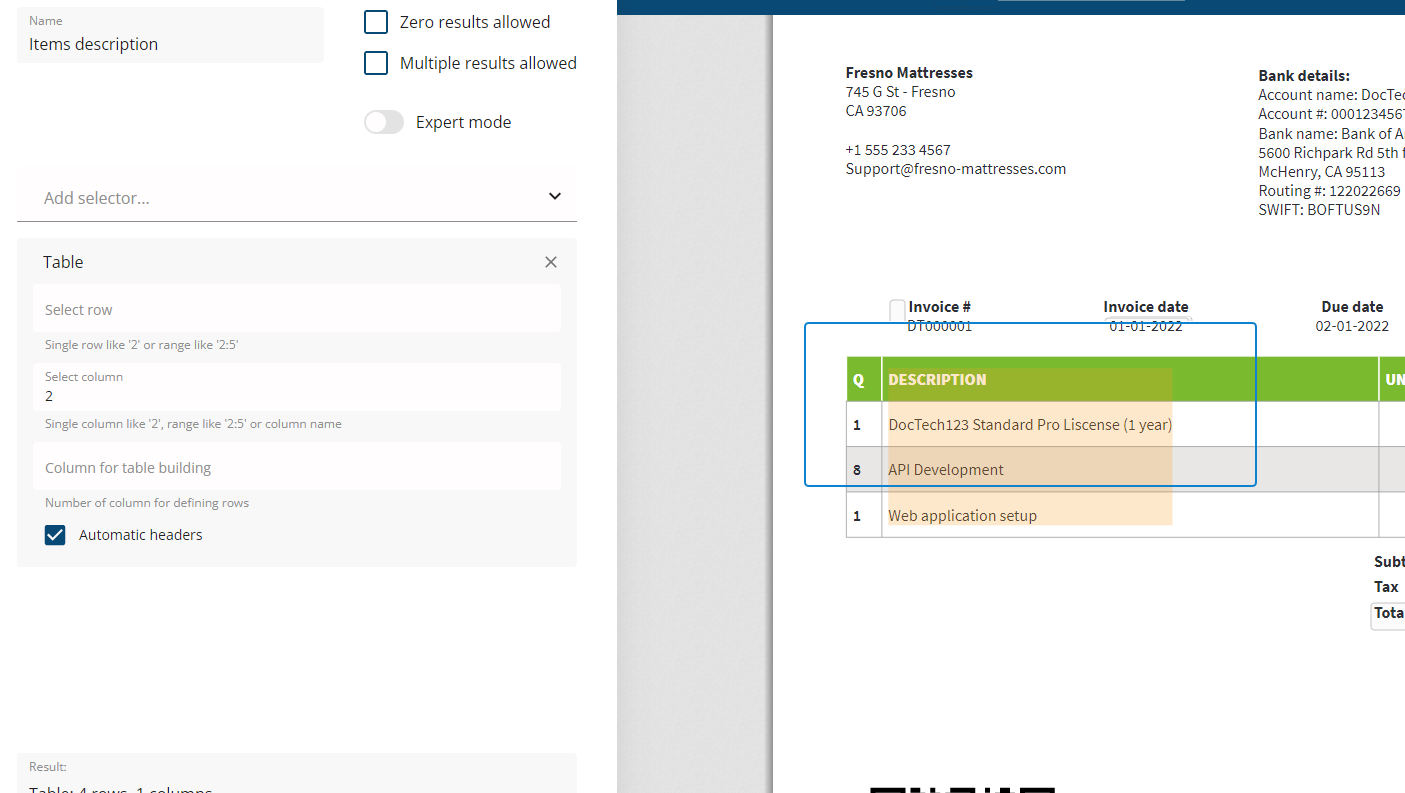
When speaking about extraction of tables, whether it is an entire table or a single column the table selector is capable of doing most of the work.
As long as a portion of that table is located within the BBox you define in your template, it is feasible for the selector to intelligently find a table and figure out its columns.
In most cases, this selector picks up the row headers automatically, however it is still possible to manually define the required columns by either their headers, or an order number for example.
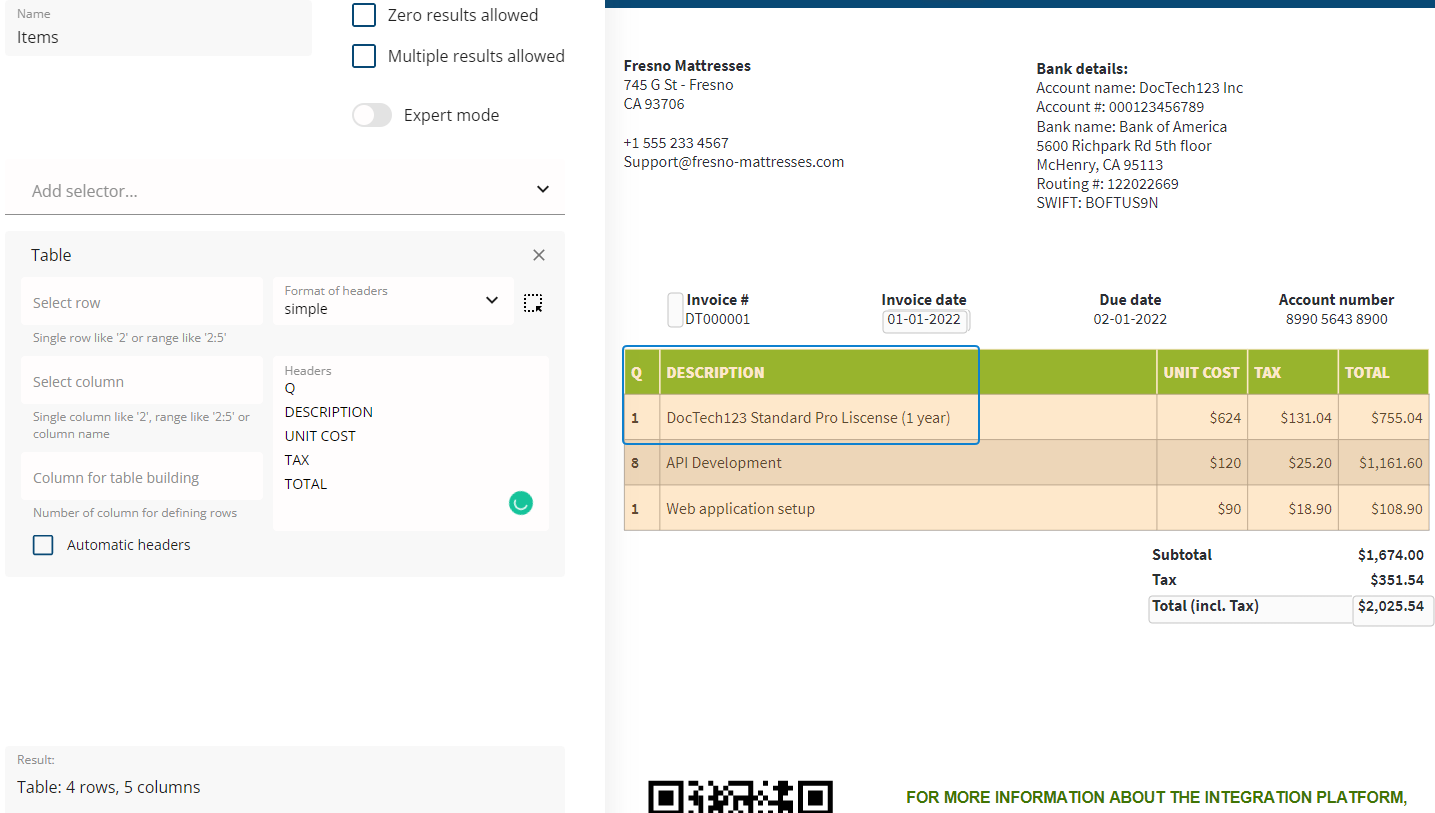
Additionally, you can set up a selection range if you need only a few rows or columns, and you can filter them our by using the parameters of the selector.
For example, if you don`t care about prices, and need only the item descriptions, just configure this selector as below:
Contractor Address
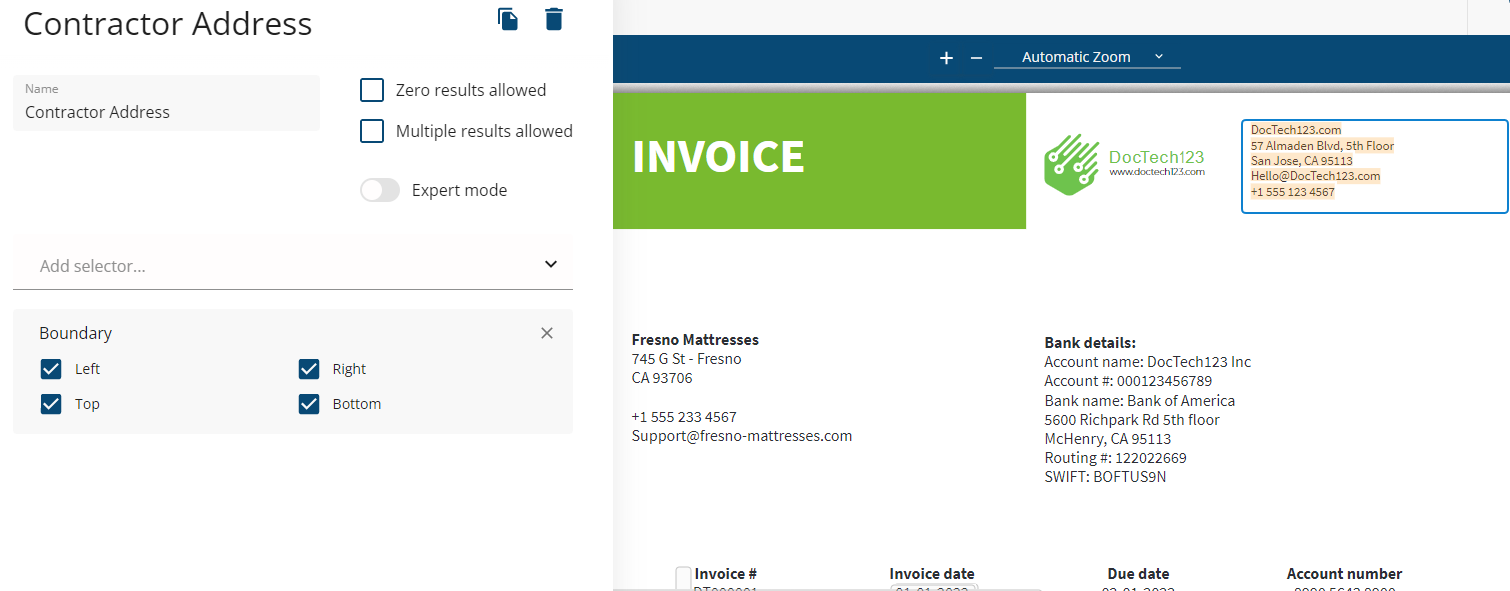
In our example, the contractor's information is rigidly located in the upper right corner of the invoice. When data to be extracted is fixed relative to the page boundaries, the fastest reliable way to extract them is using the boundary selector.
Boundary selector
Extracts text data from within the data field's BBox.
The output of the boundary selector contains 5 lines of text.
Extracted value 1: DocTech123.comExtracted value 2: 57 Almaden Blvd, 5th FloorExtracted value 3: San Jose, CA 95113Extracted value 4: Hello@DocTech123.comExtracted value 5: +1 555 123 4567
The contractor address can be found in lines 2 and 3, We can filter out our output by using the picker selector.
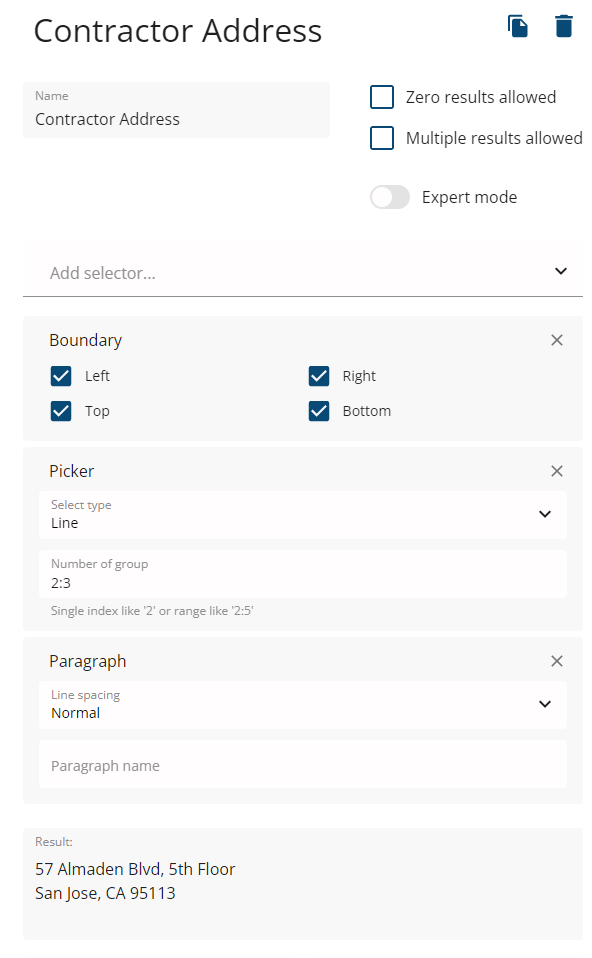
Please note, that we switch the picker's select type parameter to Line, as we are going to extract the 2nd and 3rd lines.
We also applied the Paragraph selector over the extracted lines. Without a paragraph name defined, it works as an "output converter" merging lines into a single paragraph.
Bank details. Account #, SWIFT, Account Name

All those values perfectly fit the Pattern selector use-case.
Pattern selector.

Extracts data located to the right, to the left, or in-between of the static text.
In our case, we need to extract data from the right of the text to the end of the line, so we need to specify the prefix parameter.
For each field the prefix text is different; Account #:, SWIFT:, Account Name:, but the extraction approach is the same.
The selector below extracts the Account number:
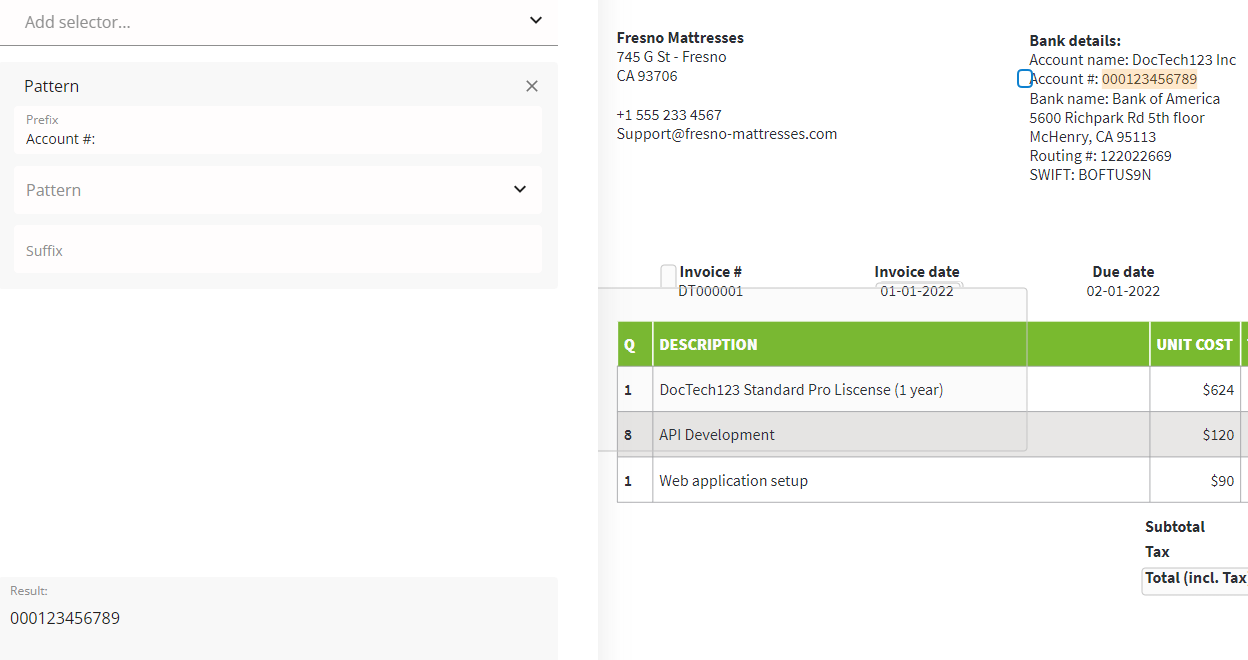
As you can see, the usage is pretty straightforward, so you can easily do the same for other fields. Please refer to the template attached to this tutorial, to double-check how it can be done.
QR code value
QR codes are getting more and more popular and being used practically everywhere. In invoices, they are often used to encode a URL to a webpage where you can find invoice-related information.
Barcode selector
The position of barcodes is usually fixed relative to a page's boundaries.
The barcode selector analyzes the BBox content and extracts value from barcodes or QR codes if there are any.
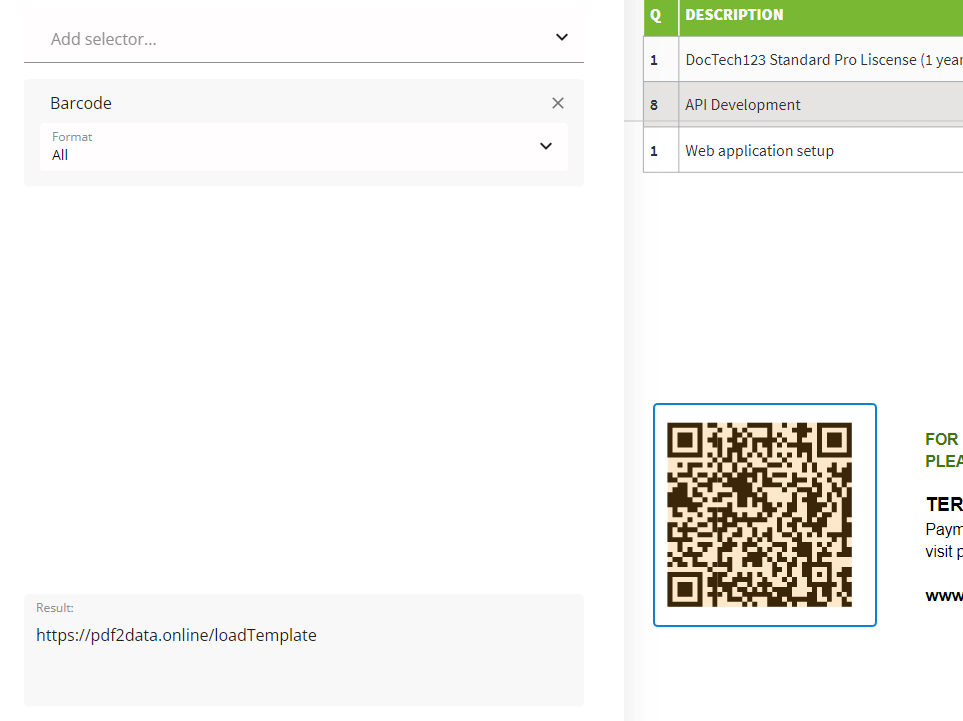
E.g. our sample invoice contains a link to the pdf2data.online website.
Resources
Original sample:
Final template: Tutorial-tmpl-iText-invoice.pdf
Next part (Test your template - pdf2Data Documentation)