Previous part (Define parsing rules in Template editor - pdf2Data Documentation)
As soon as you have completed defining your parsing rules, you need to click the "Exit" button at the top-right of the Editor to be redirected back to the "Create parsing template page".
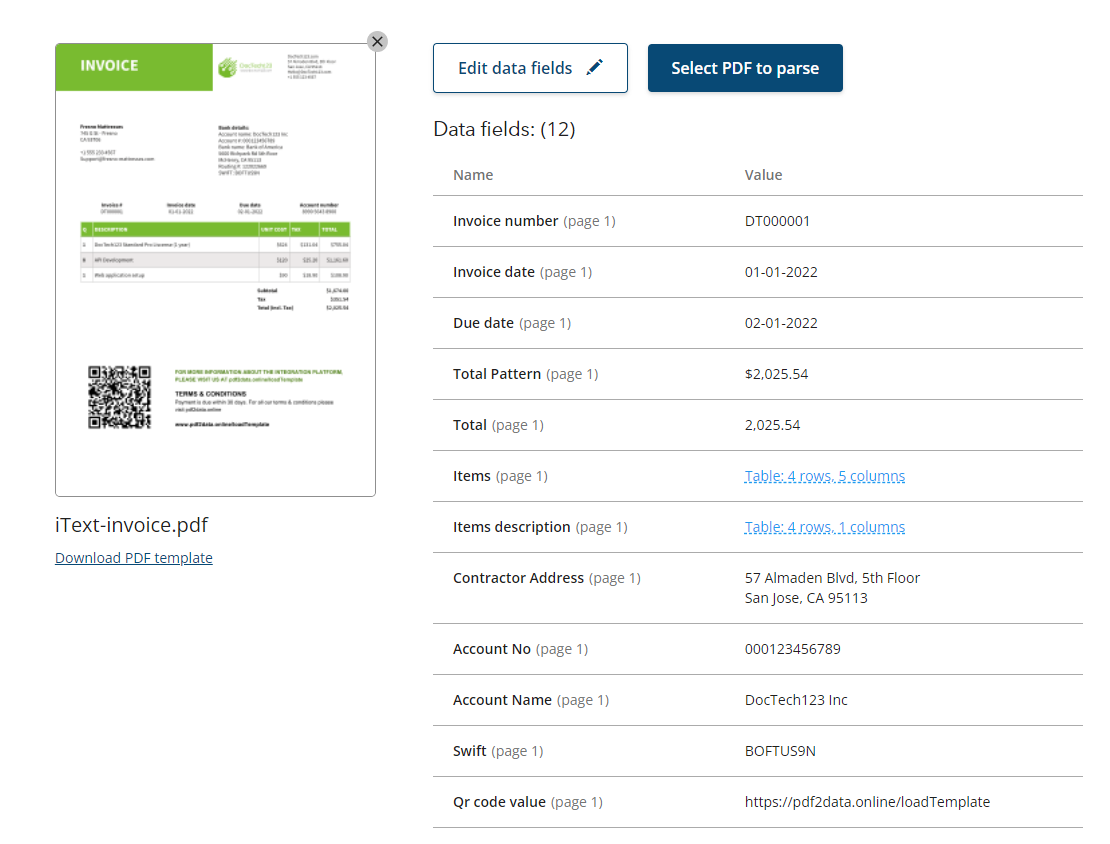
Now you can see an overview of all data fields defined in the template, together with the corresponding output data.
This template can be used to mass-process PDF invoices with a similar layout by the pdf2Data SDK in your Java or .NET application, or by the pdf2Data CLI. Please refer to the SDK how-to guide for more details.
You need to download the PDF template and store it somewhere where it can be available for your application. However, to make sure that your template is flexible enough, it is good to manually test it on a few samples beforehand. This can be done by clicking the "Select PDF to parse" button.
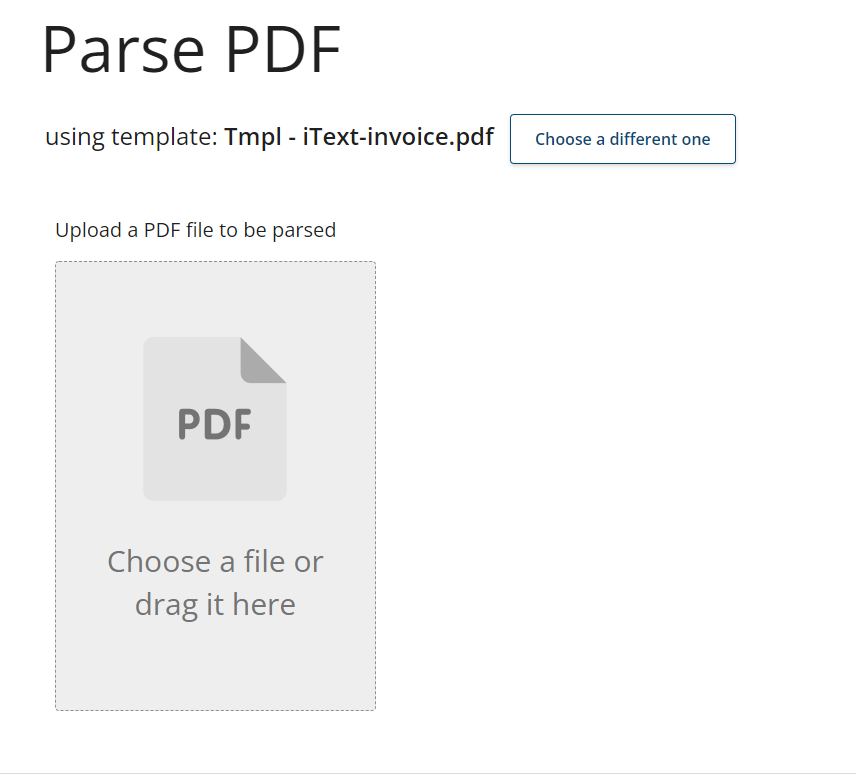
It opens the Parse PDF page where you can upload a file to be parsed with this template.
iText pdf2Data applies the selected template to the file and reports which data will be extracted. In this report, you also find screenshots of how extracted values look in the PDF that has been parsed, so you can compare and provide us with feedback if you'd like.
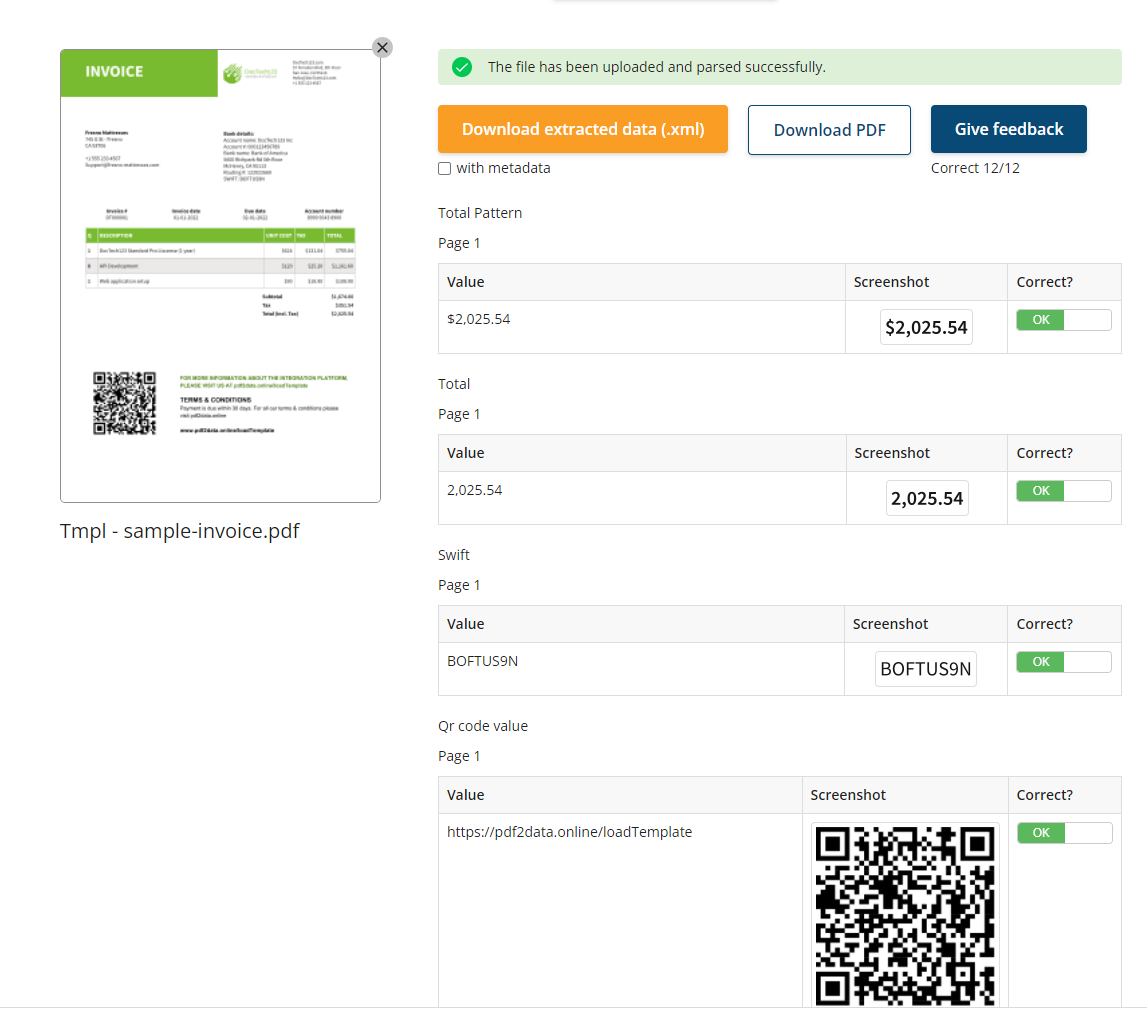
The output data is available as XML (exactly as it is for both the SDK and CLI) that can optionally include metadata, or as a PDF with the annotations containing the extraction results.
Resources.
-
Pdf to be parsed,
-
Extracted values as XML
-
XML with metadata
-
Result PDF