Which version?
This Tutorial was written with iText 7.0.x in mind, however, if you go to the linked Examples you will find them for the latest available version of iText. If you are looking for a specific version, you can always download these examples from our GitHub repo (Java/.NET).
The ElementPropertyContainer has three direct subclasses: Style, RootElement, and AbstractElement. We've briefly discussed Style at the end of chapter 1. We've discussed the RootElement subclasses Canvas and Document in the previous chapter. We'll deal with the AbstractElement class in the next three chapters:
-
We'll start with the
ILeafElementimplementationsTab,Link,Text, andImagein this chapter. -
We'll continue with the
BlockElementobjectsDiv,LineSeparator,List,ListItem, andParagraphin the next chapter. -
We'll conclude with the
BlockElementobjectsTableandCellin chapter 5.
Note that we've already discussed the AreaBreak object in chapter 2. We'll have covered all of the basic building blocks by the end of chapter 5.
In the previous chapter, we've used a txt file as a resource to create a PDF document. In this chapter, and in the chapters that follow, we'll also use a CSV file, jekyll_hyde.csv, as data source. See figure 3.1.
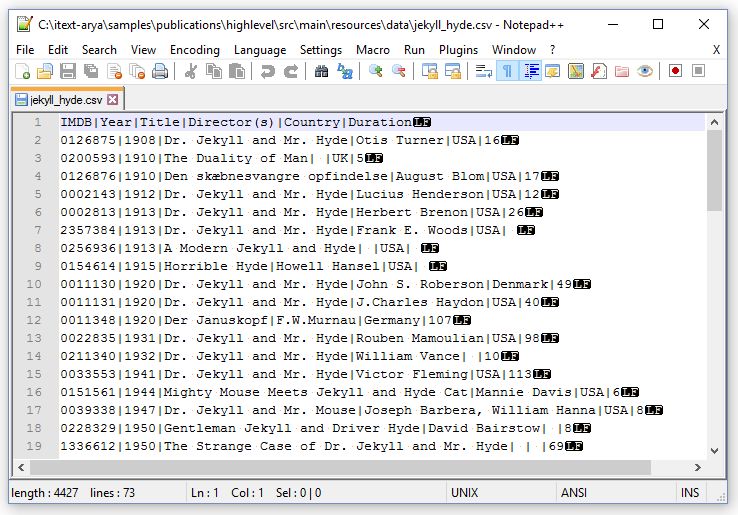
As you can see, this CSV file could be interpreted as a database table containing records that consist of 6 fields:
-
An IMDB number- the ID of an entry in the Internet Movie Database (IMDB) that was based on the Jekyll and Hyde story by Robert Louis Stevenson.
-
A year- the year the corresponding movie, short film, cartoon, or video was produced.
-
A title- the title of the movie, short film, cartoon, or video.
-
Director or directors- the director or directors who made the movie, short film, cartoon, or video.
-
A country- the country where the movie, short film, cartoon, or video was produced.
-
A run length- the number of minutes of the movie, short film, cartoon, or video.
We will use the CsvTo2DList utilities class to read this CSV file, that was stored using UTF-8 encoding, into a two-dimensional List> list.
public static final List> convert(String src, String separator)
throws IOException {
List> resultSet = new ArrayList>();
BufferedReader br = new BufferedReader(
new InputStreamReader(new FileInputStream(src), "UTF8"));
String line;
List record;
while ((line = br.readLine()) != null) {
StringTokenizer tokenizer = new StringTokenizer(line, separator);
record = new ArrayList();
while (tokenizer.hasMoreTokens()) {
record.add(tokenizer.nextToken());
}
resultSet.add(record);
}
return resultSet;
}
In this chapter, we'll render this two-dimensional list to a PDF using Tab elements.
Working with Tab elements
Let's take a look at the JekyllHydeTabsV1 example:
List> resultSet = CsvTo2DList.convert(SRC, "|");
for (List record : resultSet) {
Paragraph p = new Paragraph();
p.add(record.get(0).trim()).add(new Tab())
.add(record.get(1).trim()).add(new Tab())
.add(record.get(2).trim()).add(new Tab())
.add(record.get(3).trim()).add(new Tab())
.add(record.get(4).trim()).add(new Tab())
.add(record.get(5).trim());
document.add(p);
}
In line 1, we use our CsvTo2DList utilities class to create a resultSet of type List>. In line 2, we loop over the rows of this result set, and we create a Paragraph containing all the fields in the record list. In-between, we add Tab objects.
Figure 3.2 shows the resulting PDF.
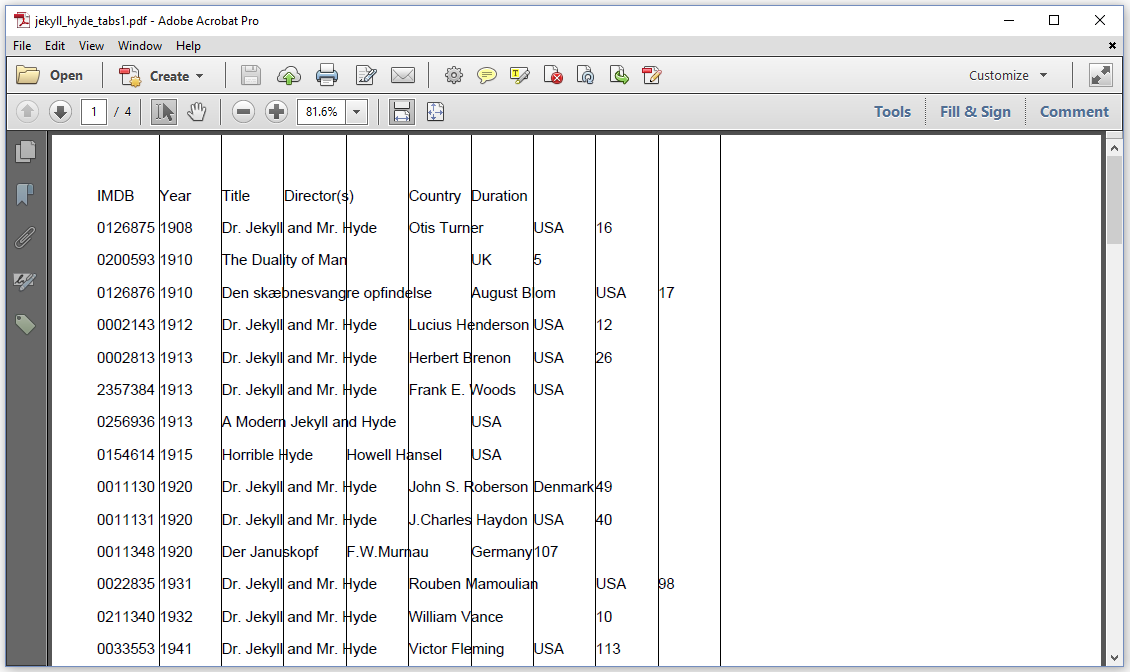
As you can see, we've added extra lines to show the default tab positions.
PdfCanvas pdfCanvas = new PdfCanvas(pdf.addNewPage());
for (int i = 1; i <= 10; i++) {
pdfCanvas.moveTo(document.getLeftMargin() + i * 50, 0);
pdfCanvas.lineTo(document.getLeftMargin() + i * 50, 595);
}
pdfCanvas.stroke();
By default, each tab position is a multiple of 50 user units (which, by default, equals 50 pt), starting at the left margin of the page. Those tab positions work quite well for the first three fields ("IMDB", "Year", and "Title"), but the "Director(s)" field starts at different positions, depending on the length of the "Title" field. Let's fix this and try to get the result shown in figure 3.3.
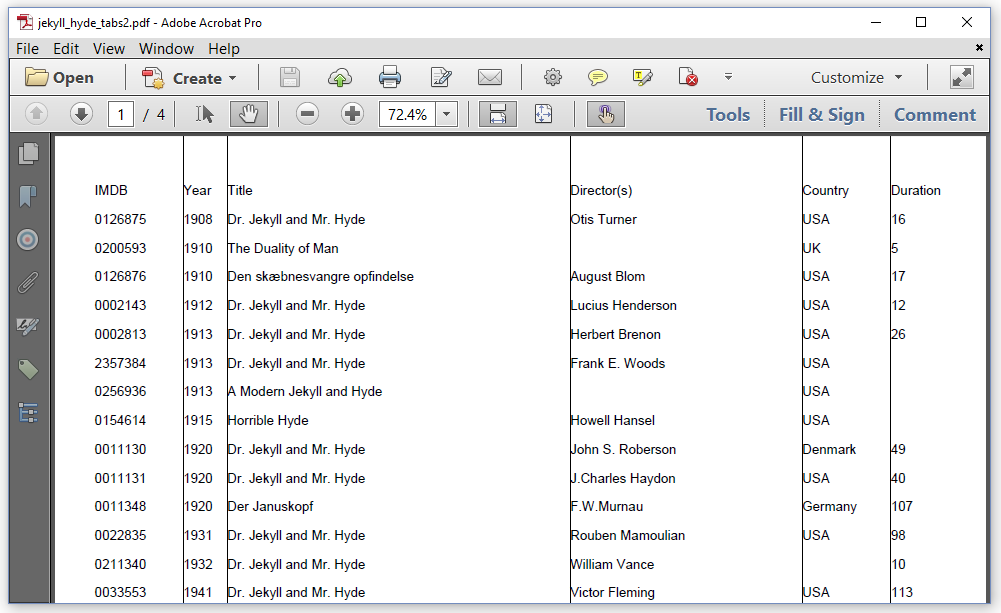
In the JekyllHydeTabsV2 example, we define specific tab positions using the TabStop class.
float[] stops = new float[]{80, 120, 430, 640, 720};
List<TabStop> tabstops = new ArrayList();
PdfCanvas pdfCanvas = new PdfCanvas(pdf.addNewPage());
for (int i = 0; i < stops.length; i++) {
tabstops.add(new TabStop(stops[i]));
pdfCanvas.moveTo(document.getLeftMargin() + stops[i], 0);
pdfCanvas.lineTo(document.getLeftMargin() + stops[i], 595);
}
pdfCanvas.stroke();
We've stored 5 tab stops in a float array in line 1, we create a List of TabStop objects in line 2, we loop over the different float values in line 4 and add the 5 tab stops to the TabStop list in line 5. While we are at it, we also draw lines that will show us the position of each tab stop, so that we have a visual reference to check if iText positioned our content correctly.
The next code snippet is almost an exact copy of what we had before.
List> resultSet = CsvTo2DList.convert(SRC, "|");
for (List record : resultSet) {
Paragraph p = new Paragraph();
p.addTabStops(tabstops);
p.add(record.get(0).trim()).add(new Tab())
.add(record.get(1).trim()).add(new Tab())
.add(record.get(2).trim()).add(new Tab())
.add(record.get(3).trim()).add(new Tab())
.add(record.get(4).trim()).add(new Tab())
.add(record.get(5).trim());
document.add(p);
}
Line 4 is the only difference: we use the addTabStops() method to add the List object to the Paragraph. The different fields are now aligned in such a way that the content starts at the position defined by the tab stop; the tab stop is to the left of the content. We can change this alignment as shown in figure 3.4.
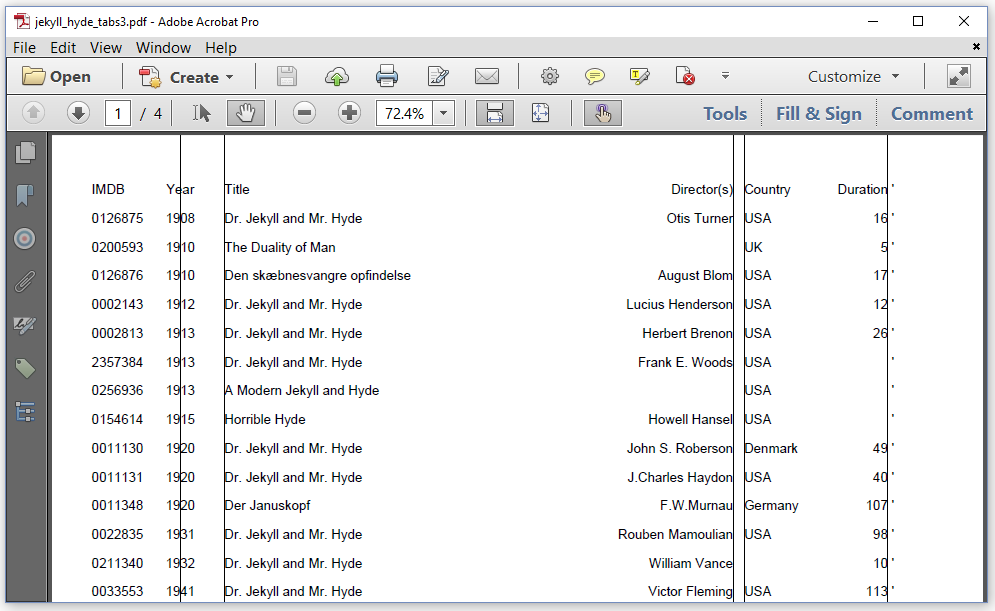
The JekyllHydeTabsV3 example shows how this is done:
float[] stops = new float[]{80, 120, 580, 590, 720};
List tabstops = new ArrayList();
tabstops.add(new TabStop(stops[0], TabAlignment.CENTER));
tabstops.add(new TabStop(stops[1], TabAlignment.LEFT));
tabstops.add(new TabStop(stops[2], TabAlignment.RIGHT));
tabstops.add(new TabStop(stops[3], TabAlignment.LEFT));
TabStop anchor = new TabStop(stops[4], TabAlignment.ANCHOR);
anchor.setTabAnchor(' ');
tabstops.add(anchor);
We have 5 tabstops:
-
The first tab stop will center the Year at position 80; for this we use
TabAlignment.CENTER. -
The second tab stop will make sure that the title starts at position 120; for this we use
TabAlignment.LEFT. -
The third tab stop will make sure that the name(s) of the director(s) ends at position 580; for this we use
TabAlignment.RIGHT. -
The fourth tab stop will make sure that the country starts at position 590.
-
The fifth tab stop will align the content based on the position of the space character; for this we use
TabAlignment.ANCHORand we define a tab anchor using thesetTabAnchor()method.
If you look at the CSV file, you see that we don't have any space characters in the "Run length" field, so let's add adapt our code and add " \'" to that field. See line 10 in the following snippet.
List> resultSet = CsvTo2DList.convert(SRC, "|");
for (List record : resultSet) {
Paragraph p = new Paragraph();
p.addTabStops(tabstops);
p.add(record.get(0).trim()).add(new Tab())
.add(record.get(1).trim()).add(new Tab())
.add(record.get(2).trim()).add(new Tab())
.add(record.get(3).trim()).add(new Tab())
.add(record.get(4).trim()).add(new Tab())
.add(record.get(5).trim() + " \'");
document.add(p);
}
Figure 3.5 shows yet another variation on this example.
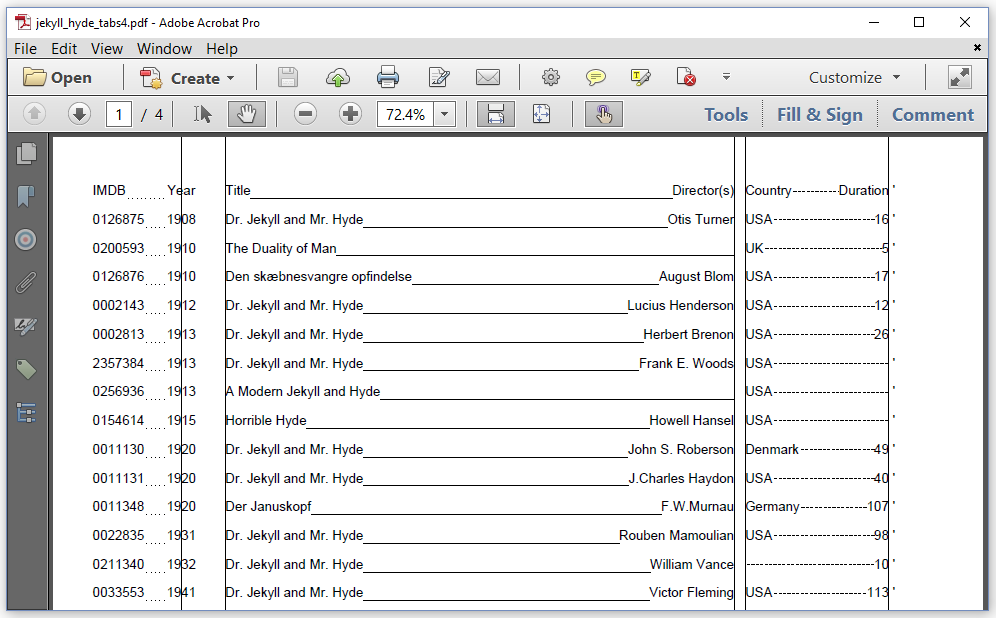
In the JekyllHydeTabsV4 example, we add tab leaders.
float[] stops = new float[]{80, 120, 580, 590, 720};
List tabstops = new ArrayList();
tabstops.add(new TabStop(stops[0], TabAlignment.CENTER, new DottedLine()));
tabstops.add(new TabStop(stops[1], TabAlignment.LEFT));
tabstops.add(new TabStop(stops[2], TabAlignment.RIGHT, new SolidLine(0.5f)));
tabstops.add(new TabStop(stops[3], TabAlignment.LEFT));
TabStop anchor = new TabStop(stops[4], TabAlignment.ANCHOR, new DashedLine());
anchor.setTabAnchor(' ');
tabstops.add(anchor);
A tab leader is defined using a class that implements the ILineDrawer interface. We add a dotted line between the IMDB id and the year, a solid line between the title and the director(s), and a dashed line between the country and the run length.
You could implement the ILineDrawer interface to draw any kind of line, but iText ships with three implementations that are ready to use: SolidLine, DottedLine, and DashedLine. Each of these classes allows you to change the line width and color. The DottedLine class also allows you to change the gap between the dots. In the next chapter, we'll also use these classes to draw line separators with the LineSeparator class.
At first sight, using the Tab object seems to be a great way to render content in a tabular form, but there are some serious limitations.
Limitations of the Tab functionality
The previous screen shots looked nice because we chose our tab stops wisely. We rendered our data on an A4 page with landscape orientation, leaving sufficient space to render all the data. This won't always be possible. In figure 3.6, we try to add the same content on an A4 page with portrait orientation.
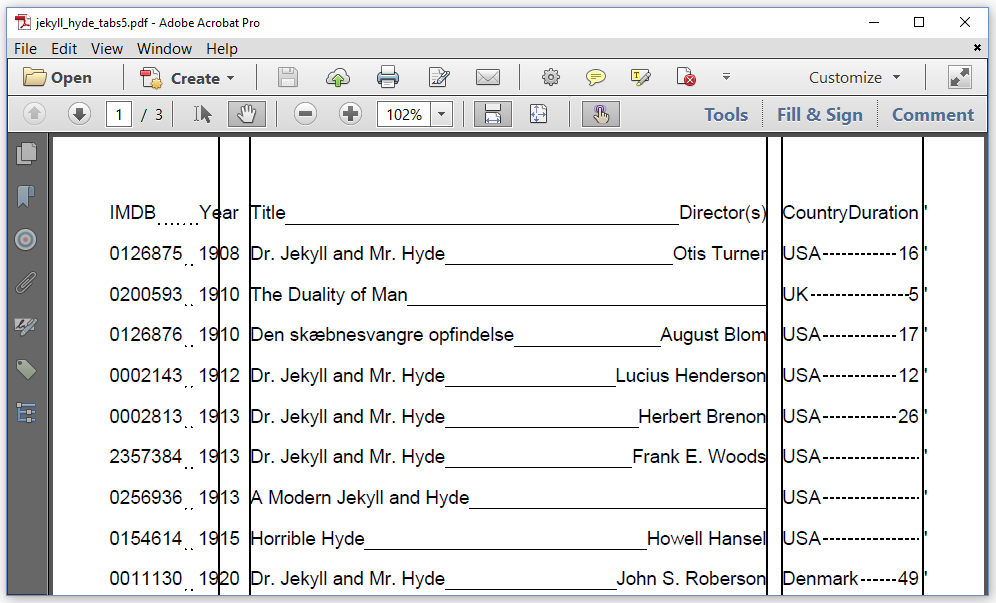
This PDF was made with the JekyllHydeV5 example. As you can see, this still looks quite nice, apart from the fact that "Country" and "Duration" stick together on the first line.
The Tab functionality contained some errors in iText 7.0.0. Due to rounding errors, some text wasn't aligned correctly in a seemingly random way. This problem was fixed in iText 7.0.1.
Another bug that was fixed in iText 7.0.1 is related to the SolidLine class. In iText 7.0.0, the line width of a SolidLine was ignored.
When we scroll down in the document, we see a more serious problem when there's no sufficient space to fit the title and the director next to each other. Director "Charles Lamont" pushes the country to the "Duration" column and the number of minutes gets shown on a second row.
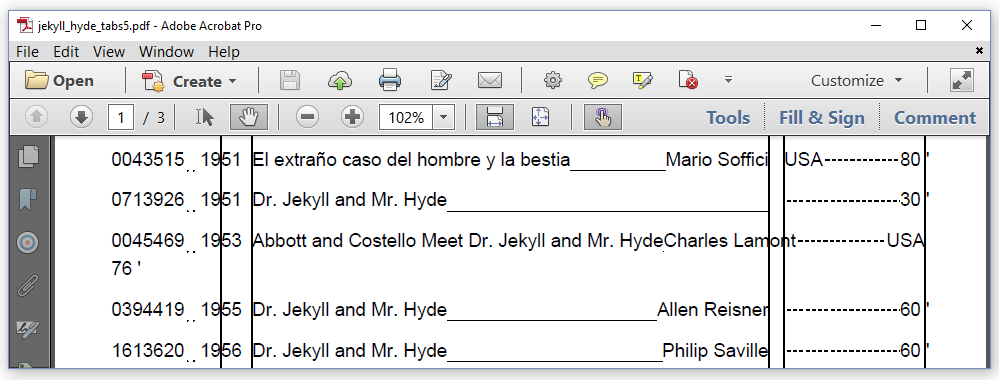
We can solve these problems by using the Table and Cell class to organize data in a tabular form. These objects will be discussed in chapter 5 of this tutorial. For now, we'll continue with some more ILeafElement implementations.
Adding links
In the previous examples, we've added the ID of the movie, short film, cartoon, or video as actual content. This ID can help us find the movie on the Internet Movie Database (IMDB). In Figure 3.8, we don't show the ID, but when we click on the title of a movie, we can jump to the corresponding page on IMDB.
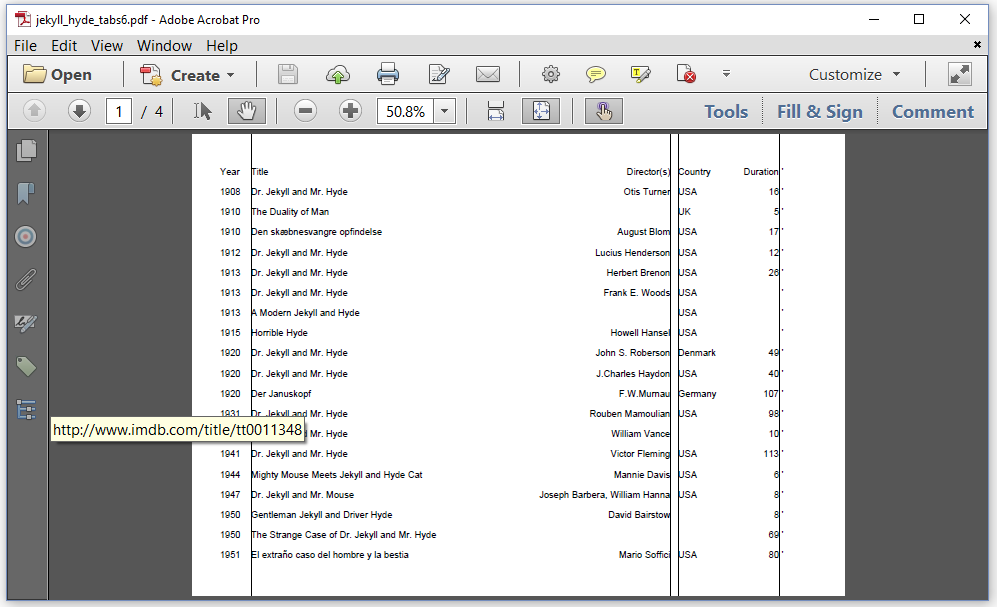
We create these links in the JekyllHydeTabsV6 example.
List> resultSet = CsvTo2DList.convert(SRC, "|");
for (List record : resultSet) {
Paragraph p = new Paragraph();
p.addTabStops(tabstops);
PdfAction uri = PdfAction.createURI(
String.format("https://www.imdb.com/title/tt%s", record.get(0)));
Link link = new Link(record.get(2).trim(), uri);
p.add(record.get(1).trim()).add(new Tab())
.add(link).add(new Tab())
.add(record.get(3).trim()).add(new Tab())
.add(record.get(4).trim()).add(new Tab())
.add(record.get(5).trim() + " \'");
document.add(p);
}
In line 5-6, we create a PdfAction object that links to an URL. This URL is composed of https://www.imdb.com/title/tt/ and the IMDB ID. In line 7, we create a Link object using a String containing the title of the movie, and the PdfAction. As a result, you will be able to jump to the corresponding IMDB page when clicking a title.
Interactivity in PDF is achieved by using annotations. Annotations aren't part of the real content. They are objects added on top of the content. In this case, a link annotation is used. There are many other types of annotations, but that's outside the scope of this tutorial. There are also many types of actions. For now, we've only used a URI action. We'll use some more in chapter 6.
The Link class extends the Text class. Appendix A lists a series of methods that are available for the Link as well as for the Text class to change the font, to change the background color, to add borders, and so on.
Extra methods available in the Text class
We've already worked with Text objects on many occasions in the previous chapters, but let's take a closer look at some Text functionality we haven't discussed yet.
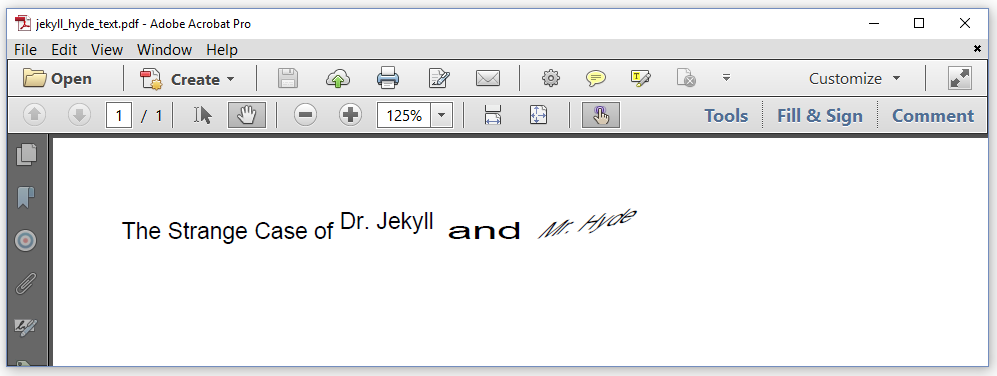
The first Text object shown in figure 3.9 is what text normally looks like. For the words "Dr. Jekyll", we defined a text rise. We scaled the word "and" horizontally. And we skewed the words "Mr. Hyde." The methods used to achieve this can be found in the TextExample example.
Text t1 = new Text("The Strange Case of ");
Text t2 = new Text("Dr. Jekyll").setTextRise(5);
Text t3 = new Text(" and ").setHorizontalScaling(2);
Text t4 = new Text("Mr. Hyde").setSkew(10, 45);
document.add(new Paragraph(t1).add(t2).add(t3).add(t4));
We distinguish three new methods:
-
The parameter passed to the
setTextRise()method is the number of user units above the baseline of the text. You can also use a negative value if you want the text to appear below the base line. -
The parameter of the
setHorizontalScaling()method is the horizontal scaling factor we want to use. In this case, the word" and "will be rendered double as wide as normal. -
The parameters of the
setSkew()method define two angles in degrees. The first parameter is the angle between the text and its baseline. The second parameter is the angle that will be used to skew the characters. ThesetSkew()method is used to mimic an italic font (see chapter 1).
We'll continue using the Text object explicitly or implicitly in every example that involves text. The second half of this chapter will be dedicated entirely to the Image class.
Introducing images
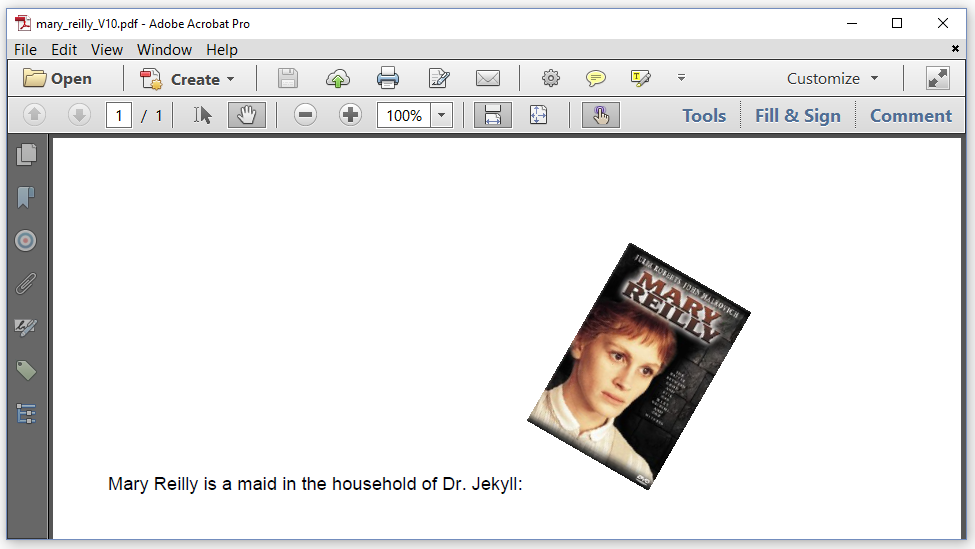
In 1996, Stephen Frears made a movie with Julia Roberts in the role of Mary Reilly, a maid in the household of Dr. Jekyll. Let's take an image of the poster of this movie and add it to a document as done in figure 3.10.
The code to achieve this, is very simple. See the MaryReillyV1 example.
public static final String MARY = "src/main/resources/img/0117002.jpg";
public void createPdf(String dest) throws IOException {
PdfDocument pdf = new PdfDocument(
new PdfWriter(new FileOutputStream(dest)));
Document document = new Document(pdf);
Paragraph p = new Paragraph(
"Mary Reilly is a maid in the household of Dr. Jekyll: ");
document.add(p);
Image img = new Image(ImageDataFactory.create(MARY));
document.add(img);
document.close();
}
We have the path to our image in line 1. The ImageDataFactory uses this path in line 9 to get the image bytes and to convert them into an ImageData object that can be used to create an Image object. In this case, we are passing a JPEG image, and we add that image straight to the document object in line 10.
JPEG images are stored inside a PDF as-is. It isn't necessary for iText to convert the image bytes into another image format. PNG for instance, isn't supported in PDF, hence iText will have to convert each PNG image we pass into a compressed bitmap.
Images are stored outside the content stream of the page in an object named an image XObject. XObject stands for eXternal Object. The bytes of the image are stored in a separate object outside the content stream. Now suppose that we would add the same image twice as is done in figure 3.11.
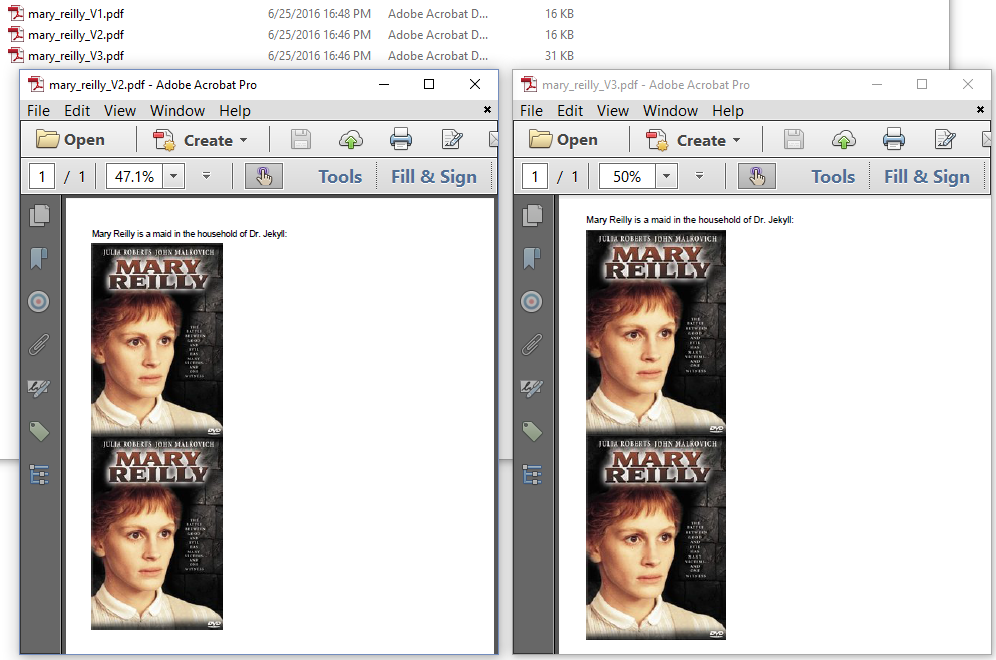
When we compare the files mary_reilly_V2.pdf and mary_reilly_V3.pdf, they look exactly the same to the naked eye. When we look at the file size of the files, we notice something strange:
-
The file marked as V2 has the same file size as the file marked as V1. In other words, the file with two images has more or less the same file size as the file with a single image. This is consistent with what we said before: the file is stored inside the document only once as an external object. We refer to this XObject twice.
-
The file marked as V3 looks identical to the file marked as V2, but its file size is almost double the size of the file marked as V2. It's as if the image bytes of our JPEG are added twice to the PDF document.
The code we used to create the file marked as V2 can be found in the MaryReillyV2 example:
Image img = new Image(ImageDataFactory.create(MARY));
document.add(img);
document.add(img);
We create one img object; we add this image twice to the same document. As a result, the image is shown twice, but the image bytes are stored in a single image XObject.
Now let's take a look at the MaryReillyV3 example.
Image img1 = new Image(ImageDataFactory.create(MARY));
document.add(img1);
Image img2 = new Image(ImageDataFactory.create(MARY));
document.add(img2);
In this snippet, we create two Image instances for the same image, and we add both of these instances to the same document. Once more the image is shown twice, but now it's also stored twice (redundantly) inside the document.
There's a direct relationship between an Image object in iText and an image XObject inside the PDF. Every new Image object that is created and added to a document, results in a separate image XObject inside the PDF. If you create two or more Image objects of the same image, you'll end up with a bloated PDF file with too many redundant image XObjects. This is clearly something you want to avoid.
In these first examples, we added Image objects without defining a location. The first image was added right under our first paragraph. The second image was added right under the first one. We can also choose to add the Image at specific coordinates.
Changing the position and width of an image
The two PDFs in figure 3.12 look identical, yet there were created in slightly different ways.
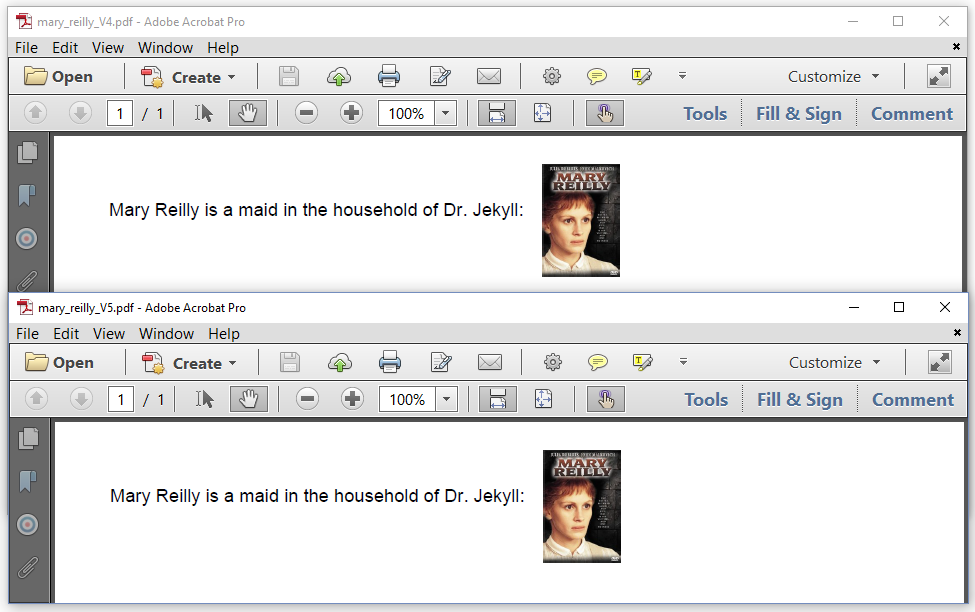
The top PDF was created using the MaryReillyV4 example:
Image img = new Image(ImageDataFactory.create(MARY), 320, 750, 50);
document.add(img);
In this example, we define the position and the size of the image in the Image constructor. We define the position as x = 320; y = 750, and we define a width of 50 user units (which is, by default, a width of 50 pt). The height of the image will be adjusted accordingly, preserving the aspect ratio of the image.
The second PDF was created using the MaryReillyV5 example.
Image img = new Image(ImageDataFactory.create(MARY));
img.setFixedPosition(320, 750, UnitValue.createPointValue(50));
document.add(img);
In this case, we use the setFixedPosition() method to define the position and size of the image. Note that we use the UnitValue to define that 50 is a value expressed in pt. The other option is to define the width as a percentage.
There are different variations available for the Image constructor and the setFixedPosition() method. For instance, you can also define a page number as is done in the MaryReillyV6 example.
Image img = new Image(ImageDataFactory.create(MARY));
img.setFixedPosition(2, 300, 750, UnitValue.createPointValue(50));
document.add(img);
In this example, adding the image on page 2, triggers the creation of a new page. See figure 3.13.
If we had been adding the image on page 200, 199 new pages would have been added in order to make sure that the image is actually on page 200. I'm not sure if there's an actual use case for the setFixedPosition() method that accepts a page number as a parameter when creating a document from scratch, but that method can also be used when adding content to an existing document.
Adding an image to an existing PDF
In the iText: Jump-Start tutorial (Java/.NET), we've been working with existing documents. We can import an existing document into iText with a PdfReader instance and create a new PDF based on the original document.
In iText 5, we would have worked with a PdfStamper object to add content to an existing PDF. Beginning with iText 7. this PdfStamper object no longer exists. Content is always added using either a PdfDocument instance (low-level content), or a Document instance (high-level content).
Let's take a look how it's done in the MaryReillyV7 example.
public void manipulatePdf(String src, String dest) throws IOException {
PdfReader reader = new PdfReader(src);
PdfWriter writer = new PdfWriter(dest);
PdfDocument pdfDoc = new PdfDocument(reader, writer);
Document document = new Document(pdfDoc);
Image img = new Image(ImageDataFactory.create(MARY));
img.setFixedPosition(1, 350, 750, UnitValue.createPointValue(50));
document.add(img);
document.close();
}
We create a PdfDocument instance using a PdfReader and a PdfWriter object. We use the PdfDocument instance to create a Document. We add an Image to that document using specific coordinates and a specific width on page 1. The result is shown in figure 3.14.
There are different ways to resize an image.
Resizing and rotating an image
We already changed the dimensions by defining a width in points, in the MaryReillyV8 example, we use a percentage.
Image img = new Image(ImageDataFactory.create(MARY));
img.setHorizontalAlignment(HorizontalAlignment.CENTER);
img.setWidthPercent(80);
document.add(img);
As shown in figure 3.15, the image is now centered on the page (using the setHorizontalAlignment() method) and it takes 80% of the available width on the page (using the setWidthPercent() method).
Note that iText will automatically scale the image to 100% of the available width when you're trying to add an image that doesn't fit.
Resizing an image doesn't change anything to the original quality of the image. The number of pixels in the image remains identical; iText doesn't change a single pixel in your image. This doesn't mean the resolution doesn't change when you resize an image. If an image is 720 pixels by 720 pixels and you render this image as a 720 pt by 720 pt image, the resolution will be 72 dots per inch. If you change the dimension to 72 pt by 72 pt, you will have a resolution of 720 dots per inch.
So far, we've been adding Image objects straight to the document. You can also add Image objects to BlockElement objects. In the MaryReillyV9 example, we add an Image to a Paragraph.
Paragraph p = new Paragraph(
"Mary Reilly is a maid in the household of Dr. Jekyll: ");
Image img = new Image(ImageDataFactory.create(MARY));
p.add(img);
document.add(p);
The result is shown in figure 5.16.
We see that the leading has been adjusted automatically, but also that the image is somewhat big. The Mary Reilly poster is 182 by 268 pixels in size. In this case, iText will use the same size in user units. As a result, the image shown in figure 3.16 measures 182 by 268 pt. iText may scale images automatically depending on the context. We already mentioned the situation where the image doesn't fit the width of the page; in chapter 5, we'll see how images behave in the context of tables.
There are also different scale() methods that allow us to scale an image programmatically. In the MaryReillyV10 example, we scale the image to 50% in X- as well as in Y-direction.
Paragraph p = new Paragraph(
"Mary Reilly is a maid in the household of Dr. Jekyll: ");
Image img = new Image(ImageDataFactory.create(MARY));
img.scale(0.5f, 0.5f);
img.setRotationAngle(-Math.PI / 6);
p.add(img);
document.add(p);
We also set a rotation angle of -30 degrees, which results in the PDF shown in figure 3.17.
These are the most common ways to change the dimensions of an Image object:
-
the
scale()method: accepts two parameters. The first one is the factor that will be used in the X-direction; the second one is the factor that will be used in the Y-direction. For instance: if you pass a value of1ffor the X-direction and0.5ffor the Y-direction, the image will be as wide as initially, but the height will be reduced to 50% of the original height. -
the
scaleAbsolute()method: also accepts two parameters. The first one is the absolute width in user units; the second one is the absolute height in user units. For instance: if you use a value of72ffor both the width and the height, the image will, by default, be rendered as an image of 1 inch by 1 inch. -
the
scaleToFit()method: also accepts two parameters. Using thescaleAbsolute()method can lead to awkward results if you don't take the aspect ratio of the image into account. The first parameter of thescaleToFit()method defines the maximum width of the image; the second one defined the maximum height. The image will be scaled preserving the aspect ratio. This means that the resulting image may be smaller than expected.
So far, we've only been using JPEG images, but iText supports many other image types.
Image types supported by iText
iText supports the following image formats: JPEG, JPEG2000, BMP, PNG, GIF, JBIG2, TIFF, and WMF. iText also supports raw image data (if you provide the pixels or the CCITT bytes). If you consider PDF to be an image format –which it isn't–, you can even import PDF pages as if they were images.
We've already covered JPEG sufficiently, we'll cover all the other formats in the next couple of examples, starting with the ImageTypes example.
Raw image data
When we use the ImageDataFactory, iText will examine the image that is provided. It will check which image type is encountered, and it will create an ImageData object for that specific image type. Most of the times, we'll import an existing image, but we can also create the raw image data on the fly. In figure 3.18, we see an image of a gradient that evolves from yellow to blue.
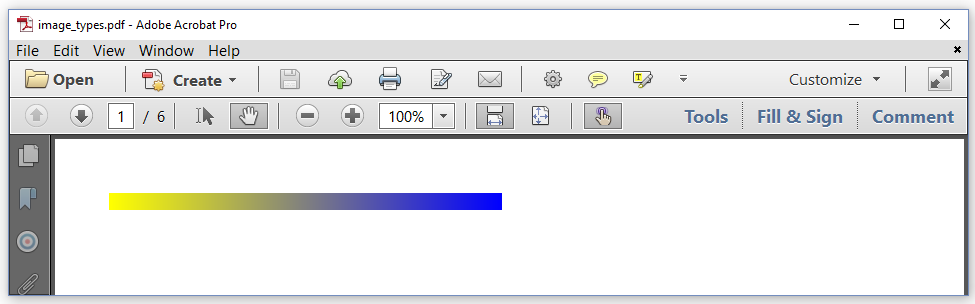
The RGB code for yellow is #FFFF00; the RGB code for blue is #0000FF. If we want to create an RGB images that shows gradient from yellow to blue, we could create an image with 256 pixels that is 256 pixels wide and 1 pixel high. We could then loop from 0 (0x00) to 255 (0xFF) creating pixels that vary from [Red = 255, Green = 255, Blue = 0] to [Red = 0, Green = 0, Blue = 255]. The total byte size of that image would be the number of pixels multiplied with the number of values needed to describe the color of each pixel. The following code snippet shows how this is done:
byte data[] = new byte[256 * 3];
for (int i = 0; i < 256; i++) {
data[i * 3] = (byte) (255 - i);
data[i * 3 + 1] = (byte) (255 - i);
data[i * 3 + 2] = (byte) i;
}
ImageData raw = ImageDataFactory.create(256, 1, 3, 8, data, null);
Image img = new Image(raw);
img.scaleAbsolute(256, 10);
document.add(img);
In this snippet, we ask the ImageDataFactory to create the ImageData for an image of 256 pixels by 1 pixel. We are using 3 components for each pixel. Each component is expressed using 8 bits per component (bpc); that's 1 byte. The fourth parameter of the create() method is the data[]. The fifth parameter is an array we can use to define transparency. We don't need this parameter in our simple example. We use the ImageData to create a new Image and we scale this image in the Y-direction. If we didn't scale the image, we'd only see a very thin line that is 1 user unit high.
Which values are valid for the number of components?
You can work with 1, 3, or 4 components.
-
1 component- means that you define the color of each pixel using one value. We typically call this a gray value, although it's actually a black / white (or rather color / no color) value if you only use 1 bit per component. If you have 8 bits per component, you can define gray values with an intensity varying between 0 (black) and 255 (white).
-
3 components- means that you define RGB colors using three values: Red, Green, and Blue.
-
4 components- means that you define CMYK colors using four values: Cyan, Magenta, Yellow, and blacK.
Usually, we don't have to worry about all of this, we can just pass a reference to an image or a byte[] containing an existing image, and we let iText do all the low-level work.
Let's take this first batch of image files and see what happens what we add them to a Document.
public static final String TEST1 = "src/main/resources/img/test/map.jp2";
public static final String TEST2 = "src/main/resources/img/test/butterfly.bmp";
public static final String TEST3 = "src/main/resources/img/test/hitchcock.png";
public static final String TEST4 = "src/main/resources/img/test/info.png";
public static final String TEST5 = "src/main/resources/img/test/hitchcock.gif";
public static final String TEST6 = "src/main/resources/img/test/amb.jb2";
public static final String TEST7 = "src/main/resources/img/test/marbles.tif";
We start with the .jp2 file which is an image in JPEG2000 format.
JPEG / JPEG2000
The code to add a JPEG2000 image doesn't look any different than the code to add a JPEG image.
Image img1 = new Image(ImageDataFactory.create(TEST1));
document.add(img1);
The result is shown in figure 3.19.
JPEG and JPEG200 are supported natively in PDF, this isn't the case for PNG.
BMP / PNG / GIF
GIF is supported in PDF (it's called LZW), but whenever iText encounters a BMP file, a PNG file, or a GIF file, that file gets converted into a raw image that consists of a bytes that define pixels. These pixels are then compressed and stored in the PDF.
Figure 20 shows one BMP (the butterfly), two PNG files (the first Hitchcock image and the information sign) and one GIF file that is added twice (a second Hitchcock image).
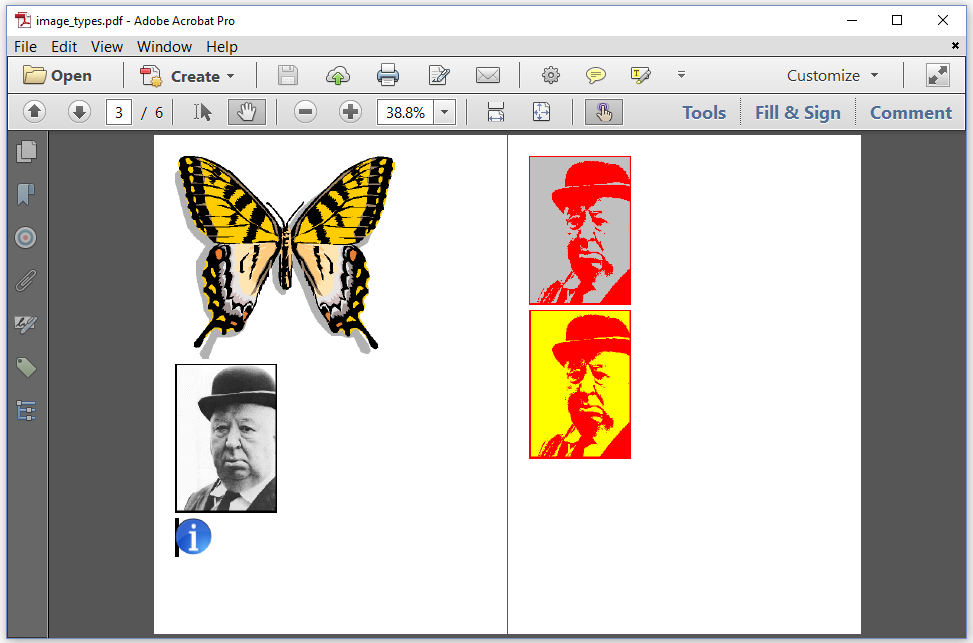
The code for the page to the left looks like this:
// BMP
Image img2 = new Image(ImageDataFactory.create(TEST2));
img2.setMarginBottom(10);
document.add(img2);
// PNG
Image img3 = new Image(ImageDataFactory.create(TEST3));
img3.setMarginBottom(10);
document.add(img3);
// Transparent PNG
Image img4 = new Image(ImageDataFactory.create(TEST4));
img4.setBorderLeft(new SolidBorder(6));
document.add(img4);
As you can see, we're using the setMarginBottom() method for img2 and img3 to introduce 10 user units of white space between the images. There is something special with img4; info.png is partly transparent. We introduce a left border with a thickness of 6 user units. We see that border, because the image is transparent. If the image were opaque, that border would have been invisible because it would have been covered by the image.
Transparent images aren't supported in PDF, at least not in the way you'd expect. When you add an image with transparent parts to a PDF, iText will add two images:
-
An opaque image: for instance, an image where the transparent part consists of black pixels,
-
An image mask: this is an image with 1 component that defines the transparency.
A PDF viewer will use both images to compose the transparent image.
If the image mask has 1 bpc, we talk about a hard mask. The pixel of the opaque image underneath the mask is either visible or invisible. If the image mask has more than 1 bpc, we talk about a soft mask. The pixel underneath the mask can be partly transparent.
The same is true for background colors. We define a gray background for the first Hitchcock image in the page on the right:
Image img5 = new Image(ImageDataFactory.create(TEST5));
img5.setBackgroundColor(Color.LIGHT_GRAY);
document.add(img5);
We only see this background, because hitchcock.gif is a GIF file with transparency. The second Hitchcock image is added in a completely different way.
AWT images
If you're working in a Java environment, you may have to work with the AWT image class java.awt.Image; iText also supports these images.
java.awt.Image awtImage =
Toolkit.getDefaultToolkit().createImage(TEST5);
Image awt =
new Image(ImageDataFactory.create(awtImage, java.awt.Color.yellow));
awt.setMarginTop(10);
document.add(awt);
We read the hitchcock.gif image into a java.awt.Image object in line 1-2. We get an ImageData object from the ImageDataFactory in line 4. The first parameter is the AWT image, the second parameter defines the color that needs to be used for the transparent part (if there is any). You can also add a Boolean as third parameter. If that parameter is true, the image will be converted to a black and white image.
JBIG2 / TIFF
Figure 3.21 shows a JBIG2 image and a TIFF image.
The code is pretty straightforward:
// JBIG2
Image img6 = new Image(ImageDataFactory.create(TEST6));
document.add(img6);
// TIFF
Image img7 = new Image(ImageDataFactory.create(TEST7));
document.add(img7);
It isn't always that easy to convert the full JBIG2 or TIFF image to PDF though. A JBIG2 image and a TIFF image can contain different pages. In that case, we need to loop over the pages and extract every page as a separate image. The same is true for animated GIF images that consist of different frames.
Animated GIFs / Paged images
In the PagedImages example, we define three new constants that refer to three different images.
public static final String TEST1 =
"src/main/resources/img/test/animated_fox_dog.gif";
public static final String TEST2 = "src/main/resources/img/test/amb.jb2";
public static final String TEST3 = "src/main/resources/img/test/marbles.tif";
Figure 3.22 shows the different frames of an animated GIF that shows an animation of a fox jumping over a dog.
Animated GIFs aren't supported in PDF, so you can't add the animation as-is to the document. We can only add every frame to the document as a separate image. That's what we do in the next code snippet.
URL url1 = UrlUtil.toURL(TEST1);
List list = ImageDataFactory.createGifFrames(url1);
for (ImageData data : list) {
img = new Image(data);
document.add(img);
}
We create an URL object that uses the path to the file as input. We then create a List of ImageData objects containing the ImageData of every frame in the animated GIF. Finally, we add each frame as a separate Image to the Document.
The code to read the different pages from a JBIG2 and a TIFF file is more complex.
// JBIG2
URL url2 = UrlUtil.toURL(TEST2);
IRandomAccessSource ras2 =
new RandomAccessSourceFactory().createSource(url2);
RandomAccessFileOrArray raf2 = new RandomAccessFileOrArray(ras2);
int pages2 = Jbig2ImageData.getNumberOfPages(raf2);
for (int i = 1; i <= pages2; i++) {
img = new Image(ImageDataFactory.createJbig2(url2, i));
document.add(img);
}
// TIFF
URL url3 = UrlUtil.toURL(TEST3);
IRandomAccessSource ras3 =
new RandomAccessSourceFactory().createSource(url3);
RandomAccessFileOrArray raf3 = new RandomAccessFileOrArray(ras3);
int pages3 = TiffImageData.getNumberOfPages(raf3);
for (int i = 1; i <= pages3; i++) {
img = new Image(
ImageDataFactory.createTiff(url3, true, i, true));
document.add(img);
}
document.close();
We first need to know the number of pages in the JBIG2 or TIFF file. This requires us to create a RandomAccessFileOrArray object. With this object, we can ask the Jbig2ImageData or the TiffImageData class for the number of pages in the JBIG2 or TIFF file. We can then loop over the number of pages in that file, and we use the createJbig2() or createTiff() method to get the ImageData object needed to create an Image.
Up until now, all the Image objects that we have created, resulted in an image XObject stored in the PDF document. In the next example, we'll create a different type of XObject.
WMF / PDF
All the image types we've worked with so far were raster images. Raster images consist of pixels of a certain color put next to each other in a grid. In the XObjectTypes example, we have the following source files:
public static final String WMF = "src/main/resources/img/test/butterfly.wmf";
public static final String SRC = "src/main/resources/pdfs/jekyll_hyde.pdf";
WMF is a vector image format. Vector images don't have pixels. They are made up of basic geometric shapes such as lines and curves. These lines and curves are expressed as a mathematical equation, which means that you can easily scale them without losing any quality.
The concept of resolution doesn't exist in the context of vector images. The resolution only comes into play when you render the image to a device. The resolution of the device - a printer, a screen - will determine the resolution you perceive when looking at the vector image.
A PDF can contain raster images, and each of these raster images will have its own resolution, but the PDF itself doesn't have a resolution. The content of the PDF is also made up of geometric shapes defined using PDF syntax.
In figure 3.23, you see a WMF file representing a butterfly and a page from an existing PDF file that were added to a Document using the Image object.
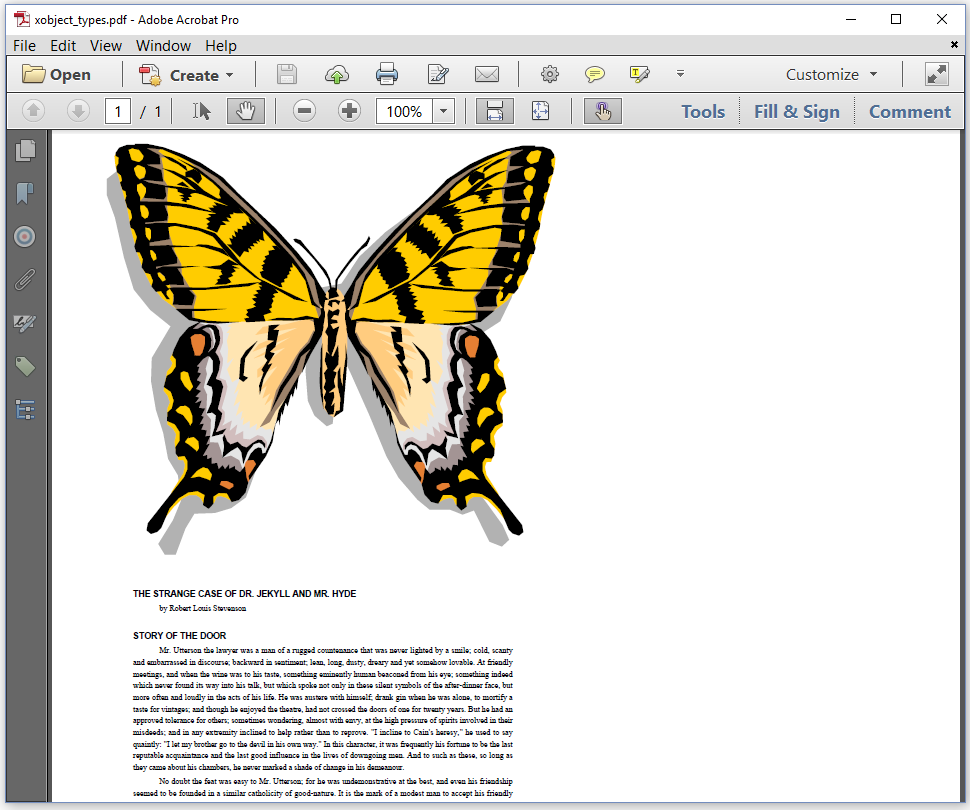
If you look inside this PDF file, you won't find any image XObject; instead you'll discover two form XObjects. A form XObject uses the same mechanism as an image XObject, except that a form XObject doesn't consist of pixels; it's a snippet of PDF syntax that is external to the page content.
If we want to add a WMF file to a Document using the Image class, we need to create a PdfFormXObject first. The WmfImageData object will help us create the ImageData that is needed to create this form XObject. We can use that xObject1 to create an Image instance.
PdfFormXObject xObject1 =
new PdfFormXObject(new WmfImageData(WMF), pdf);
Image img1 = new Image(xObject1);
document.add(img1);
We need to do something similar to import a page from an existing PDF file if we want to import that page as if it were an image.
PdfReader reader = new PdfReader(SRC);
PdfDocument existing = new PdfDocument(reader);
PdfPage page = existing.getPage(1);
PdfFormXObject xObject2 = page.copyAsFormXObject(pdf);
Image img2 = new Image(xObject2);
img2.scaleToFit(400, 400);
document.add(img2);
We start by creating a PdfReader object (line 1) and a PdfDocument based on that reader (line 2). We obtain a PdfPage from that existing document (line 3), and we copy that page as a PdfXFormObject. We can use that xObject2 to create an Image instance.
The content of the existing page will be added as if it were a vector image. All interactive features that may exist in the original page, such as links, form fields, and other annotations, will be lost.
This concludes the overview of the objects that implement the ILeafElement interface.
Summary
In this chapter, we've covered the building blocks that implement the ILeafElement interface. These elements are atomic building blocks; they aren't composed of other elements.
-
Tab-is an element that allows you to put some space between two other building blocks, either using white space, or by introducing a leader. You can also use theTabelement to align an element. -
Text-is an element that contains a snippet of text using a single font, single font size, single font color. It's the atomic text building block. -
Link-is aTextelement for which we can define aPdfAction, for instance: an action that opens a web site when we click on the text. We'll discuss more examples of links and actions in chapter 6. -
Image-is an element that can be used to create an image XObject so that you can use raster images in your PDF. For reasons of convenience, we also allow developers to wrap aPdfFormXObjectinside anImageobject so that they can use form XObjects using the same functionality that is available for image XObjects.
We haven't finished talking about these objects. We'll continue using them in the chapters that follow, starting with the next chapter that will discuss the Div, LineSeparator, Paragraph, List, and ListItem object.