The regular expression selector is the most powerful selector in iText pdf2Data's toolbox. Unsurprisingly then, it is also the least user-friendly selector.
It implements the standard regular expression search, and accordingly requires knowledge of RegExp syntax from a user.
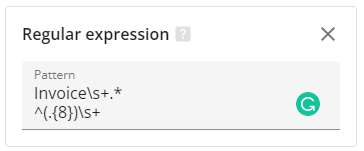
This selector has only one mandatory parameter - Pattern, that contains a regular expression to be found in a PDF.
The regular expressions may also contain groups defined within round brackets. In this case, only the string captured by the group within brackets will be extracted.
Example
Pattern: Invoice\s+(\d{3}) returns a 3-digit number that appears after the word "Invoice", this number should be separated from "Invoice" by one or more spaces.
Most of the data you require from a PDF can be extracted without this selector, please see the tutorial for example usage. However, if you feel passionate about rexExps, you don`t need anything but the regular expression selector for data extraction.
You can specify two-line regular expression, however in the majority of cases this can be replaced by using the Paragraph selector - pdf2Data Documentation
Output data format:
lines