pdfOCR allows you to define the way text is retrieved in the Tesseract 4.1 output. There are two options for it, that you can set with the Tesseract4OcrEngineProperties class (Java/.NET):
-
BY_LINES(the default value) -
BY_WORDS
These options make a difference depending on the document you are trying to OCR, and what you want to do with it. In a nutshell, if you're OCRing an invoice for instance, BY_WORDS would make sense, but if you're OCRing a book, BY_LINES would be your safest bet.
So what is the difference really?
Putting it simply, it is how you want to aggregate the information you are extracting. Do you want pdfOCR, to try to bound several words into a line, or do you want each word to be in its own bounding box?
Why should I care?
Well, if you're using a tool like pdfSweep, and would like to redact a specific word, it would make things much easier if you can just select the specific word, and don't get a big rectangle to highlight a large area with little or no interest, hence the invoice example above. You want the cell in a table with a number to be as limited as possible.
You can see it from the example below, where BY_WORDS was used, that the detected text is individually bound to $3000.
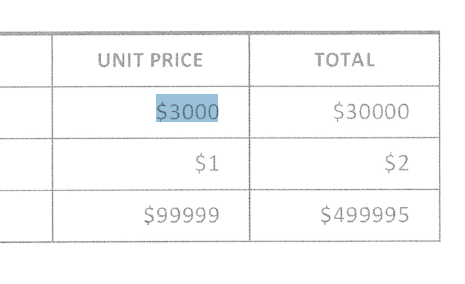
Conversely, if we had used BY_LINES, we would get:
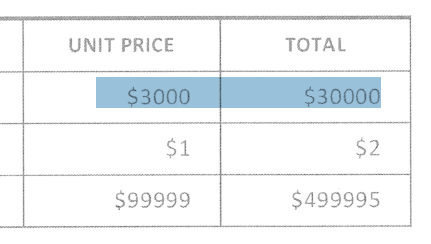
In the example of a book however, where the content is clearly laid out in lines, BY_LINES would clearly make more sense:

We hope this helps with your strategy to configure pdfOCR for the best possible output.