Why Python and iText?
Python is regularly cited as one of (if not the) most popular programming languages, and it’s easy to see why. The clean and straightforward syntax makes it easy to read, and its extensive community support make it extremely attractive to beginners.
On top of that though, Python is also extraordinarily versatile and scalable, with a level of library diversity which many other competing languages lack. Its popularity initially surged during the 2000s with the rise of the Internet and open-source software, with frameworks like Django and Flask gaining popularity for web development.
The explosion of data science and machine learning in the 2010s provided another huge boost to Python’s popularity. With libraries like Tensorflow, NumPy, Pandas, and many others, Python has became the number one choice for data analysis and AI.
Now, imagine if you could plug into iText’s advanced PDF creation and manipulation for these workflows. For example, Python developers could generate PDFs from Pandas data structures or use iText for data visualization with Matplotlib. In addition, they would also be able to utilize iText’s class-leading digital signing and validation capabilities, and extensive support for the PDF/A and PDF/UA standards for archiving and universal accessibility. Wouldn’t that be great?
Bridging the Gap With Python.NET
Well this is actually possible thanks to Python.NET, a powerful tool that allows Python and .NET languages to interoperate almost seamlessly. Maintained by the .NET Foundation, it’s an open-source package that allows you to script, or even build entire applications in Python, using .NET services and components written in any language targeting the Common Language Runtime (CLR).
With this, we can directly use the C# port of iText Core in Python environments. This article and its associated GitHub repository takes you through the steps to create a pip-installable package for iText 9 distribution, install it, and then use it to generate PDFs in Python using .NET bindings.
We haven’t stopped there though. For additional ease-of-use, we made use of a handy tool that generates typing stubs for IDE auto-completion, and also ported a whole bunch of iText code examples to get you started. These cover common iText operations such as digital signatures, form fields, merging documents, and much more. There’s also examples of using the pdfHTML add-on to create PDFs from HTML templates.
If you want to skip the preamble and try it out yourself, you can head over to itext/itext-python-example where you’ll find all you need to get started. However, if you want more of the background then stick around to find out how this actually works.
For those who are interested, we’ll also cover some limitations and snags we encountered along the way, and show how we managed to resolve or work around them. With all that said, let’s get started.
Getting Started With Python.NET
Getting started with Python.NET is pretty easy, at least on Windows. First you need to install the pythonnet package in your environment. In the source code itself you import the clr module, which will initialize a .NET runtime for you to interact with, and from that point onward you can import .NET namespaces as if they were regular Python packages.
For example, here is a "Hello, World!", which uses System.Console from .NET within Python:
import clr
from System import Console
Console.WriteLine("Hello, World!")
This is great, but we want to load an external library. Thankfully, there is a mechanism to do that. Just call clr.AddReference and you are good to go. With that in mind, we'll try to create a simple PDF document, using the iText layout engine. As for the libraries, we'll download them from NuGet and put them next to the script into a binaries directory.
from pathlib import Path
BINARIES_DIR = Path(__file__).parent / "binaries"
import clr
clr.AddReference(str(BINARIES_DIR / "itext.kernel.dll"))
clr.AddReference(str(BINARIES_DIR / "itext.layout.dll"))
from iText.Kernel.Pdf import PdfWriter, PdfDocument
from iText.Layout import Document
from iText.Layout.Element import Paragraph
pdf_writer = PdfWriter("test.pdf")
pdf_doc = PdfDocument(pdf_writer)
doc = Document(pdf_doc)
doc.Add(Paragraph("Hello, World!"))
doc.Close()
But after running this script, instead of getting a nice PDF file, you will, most likely, get an error like this:
ModuleNotFoundError: No module named 'iText'
This is not very surprising. While the NuGet package does include the iText libraries themselves, it doesn't include any of its transitive dependencies. You can, of course, manually collect all of them, catching all the Could not load file or assembly errors along the way, but this is pretty time-consuming and will make future updates much more painful than they need to be. Additionally, this approach won't be very robust, as libraries are loaded lazily. So, you might not even know that something is missing, until you start using a class or function which directly depends on the missing library.
Why not have .NET SDK do the work for us? There is no direct way to conveniently download the whole dependency tree using the SDK tools, but we could create a dummy .NET project and dotnet publish it, which will give us the libraries we need. And if we want to use a later version of the library, we would only need to update the project file.
The iText library comes in net461 and netstandard2.0 varieties. We will target netstandard2.0 for now, as it is supported on a larger variety of platforms. We'll also throw in bouncy-castle-adapter and pdfhtml packages for good measure. Here is the dummy csproj file that we will be using:
<?xml version="1.0" encoding="utf-8"?>
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<OutputType>Exe</OutputType>
<TargetFramework>netstandard2.0</TargetFramework>
<Platforms>AnyCPU</Platforms>
<RootNamespace>_csharp_dependency_stub</RootNamespace>
</PropertyGroup>
<ItemGroup>
<PackageReference Include="itext" Version="9.1.0" />
<PackageReference Include="itext.bouncy-castle-adapter" Version="9.1.0" />
<PackageReference Include="itext.pdfhtml" Version="6.1.0" />
</ItemGroup>
</Project>
So now we could just run dotnet publish on the project, copy all the libraries and run our script. But, surprisingly, you'll get an error, like this:
System.IO.FileNotFoundException: Could not load file or assembly 'System.Text.Encoding.CodePages ...
The iText library does depend on System.Text.Encoding.CodePages >= 4.3.0, but if you check the publish directory, you won't find it there. And the reason for this is rather peculiar. NuGet downloads version 4.3.0 of the library (which is a bit confusing, if you've used any other package manager) and it, actually, has two different platform-dependent binaries: one for win and one for nix. So when you ask dotnet to publish it, it just silently skips it without any warnings.
To combat that, you can just run dotnet publish --use-current-runtime instead, which will publish libraries which are relevant to your current platform. And with all those binaries the Python script should now work as expected, as in it will create a brand new PDF document for you to enjoy.
For the most part, all of the above should be enough to start trying iText out in Python on Windows. But in the itext-python-example repository, we took extra efforts to make it a bit easier:
-
It contains a script for building an
itextpypackage, which includes all the necessary binaries within it and has additional helper python code to get started. -
Binaries are collected for Windows, Mac and Linux, so the package should work across multiple platforms.
Package preparation is done in a rather complex script which collects binaries and generates python package files. Most of the complexity comes from the above issue, in that it is not clear how to force dotnet to give us all the binaries we need for all the platforms. To make it work, we publish a stub project for multiple runtime configurations one by one and then collect binaries together in one place, while at the same time combining identical binaries to reduce the overall package size. There is a lingering feeling that there is an easier and more robust way to do this, but at least it works for now.
With the itextpy package all the initializing code with clr can be replaced with just two lines:
import itextpy
itextpy.load()
This will handle runtime creation and will add all the necessary iText references for you.
Switching to Linux and macOS
If you tried the examples above on a non-Windows platform, you might have encountered some additional problems. Python.NET started its life at a time when .NET was still, predominantly, a Windows-only platform, so some of the defaults still reflect that.
For example, on Windows it will use .NET Framework as the default runtime. Yes, .NET Framework, not .NET. This has its benefits, as it is available out-of-the-box on any modern Windows system, but it is not what you would expect from modern .NET development.
It is even more confusing for Linux and macOS. Even though Python.NET supports the .NET Core runtime branch, .NET is not used by default on any of the platforms. In our case it uses Mono instead.
While Mono was impressive at the time and brought .NET Framework out of its Windows-only shell, in most use cases it has been obsoleted by .NET Core and, later, just .NET. Today you might not even find Mono to be easily available in your package manager of choice.
Luckily for us, you can force using .NET on any platform by explicitly specifying it in Python.NET either via the PYTHONNET_RUNTIME environment variable or explicitly loading the runtime in code at the beginning:
import pythonnet
pythonnet.load("coreclr")
But if you try using coreclr with iText 9.1.0, you might encounter this exception:
System.TypeInitializationException: The type initializer for 'iText.IO.Util.ResourceUtil' threw an exception.
---> System.ArgumentException: The path is empty. (Parameter 'path')
The ResourceUtil initializer handles loading of some of our optional resource libraries, like itext.hyph and itext.font-asian. To locate them ResourceUtil uses the BaseDirectory property of the current app domain as the search directory. But with .NET Core under Python.NET it is initialized to an empty string. While there is a null check present in the code, the empty string passes through and causes havoc later down the line.
This issue is fixed for the iText Core 9.2.0 release, so the script and binary patching described in the following section is no longer required.
Since the iText library is open source, you could build it locally yourself and have the fix already available. But it would still be nice to also have a fix without needing to build the library yourself. In our example, since we don't include the resource libraries, we can safely ignore the loading code. If you have experience in decompiling and editing IL code by hand, then it is relatively easy to just skip one if block at the end of an already existing function. This is what we've done in this small script. This binary patch is applied automatically, if you build the itextpy package from the example repository, so in that case coreclr should just work.
But what about Mono, does it work out-of-the box? In our tests it didn't, as we were getting a different initialization exception:
System.EntryPointNotFoundException: SystemNative_GetUnixName assembly:<unknown assembly> type:<unknown type> member:(null)
at (wrapper managed-to-native) Interop+Sys.GetUnixNamePrivate()
at Interop+Sys.GetUnixName () [0x00000] in <862459bd886947438b3fcf70c862f252>:0
at System.Runtime.InteropServices.RuntimeInformation.IsOSPlatform (System.Runtime.InteropServices.OSPlatform osPlatform) [0x00009] in <862459bd886947438b3fcf70c862f252>:0
...
Looking though the Mono source code it seems like the RuntimeInformation library should be ignored and a Mono implementation should be used instead... Without going in too deep, while Mono didn't work with the 4.0.0 version of library, pinning it to the latest 4.3.0 version solved the issue. So the package should run on Mono as well.
While it is nice, that Mono also works, it is a bit odd to be using it now as the default non-Windows option. For convenience we've also changed the defaults in the example package, so that you won't need to explicitly specify coreclr every time.
But Why Is My Code Editor Angry With Me?
With everything settled, now we have access to the vast .NET ecosystem within Python and we can use iText for any of our PDF-related needs. But if you've done the library loading yourself without the help of our example itextpy package, you might notice that your IDE of choice is not very happy, even though the code itself runs just fine.
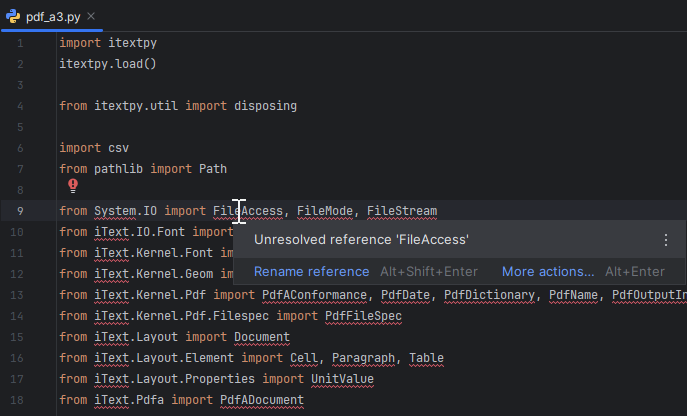
The more you think about it, it starts to make sense. Your code editor cannot find an iText or a System package in your Python environment. Even if you look at the clr.AddReference calls, they don't actually reference the namespaces at all, only the binaries themselves. These packages are created at runtime during script execution by Python.NET itself. So, to help you with these packages, the code editor needs to run the same initialization code that we have in our script.
Or does it?
Python 3 brought a bunch of improvements to the language, and one of those useful improvements is type hinting, which was released with Python 3.5.
def greeting(name: str) -> str:
return 'Hello ' + name
With projects like mypy, type hinting allows you to bring a bit of static typing order into the usual duck typing chaos. Your IDE, most likely, uses something like mypy in the background, when it screams at you, when you try to math.log a string or casefold an integer.
While, usually, typing information is written in the Python code itself, there is also a mechanism to provide typing information separately via stub files. These are files with a pyi extension, which only include the typing data for your type checker to use. You can put those next to the actual implementation py files. This makes them somewhat similar to header interface files in something like C++, though in Python you don't have a linker writing you novels, when typing information doesn't match the implementation or if it is missing entirely.
Additionally, within PEP 561 there is a section about stub-only packages. This allows you to provide stub files separately from the implementation package itself. There is an officially supported collection of stub-only packages called typeshed, which includes type stubs for a variety of popular 3rd party Python libraries. Your IDE, most likely, uses these packages to make its type checking job easier.
So this means, that we can create type stubs for our .NET assemblies, which will bring us auto-completion and type checking for .NET classes in our Python code editor. As long as there are iText-stubs and System-stubs directories to find, we are in the clear. But how will we create them? If you just look at the number of APIs added between .NET Standard 1.6 and 2.0, it measures in the thousands! And iText itself is not a small library either.
There are multiple tools for generating type stubs for Python libraries, but for .NET the choice is rather slim. This is also amplified by the fact, that any stubs we generate will be dependent on the way Python.NET maps .NET classes and methods to Python ones. In our searches we've stumbled upon a small project on GitHub: python-stub-generator. It is pretty easy to use, you just pass all the .NET assemblies to the tools and it outputs all the stubs in a tree directory structure. All you need to do is just add the -stubs suffixes to the root packages and your IDE should be able to use them. While the generated stubs don't cover all the cases and don't include documentation, they are still incredibly useful when writing code.
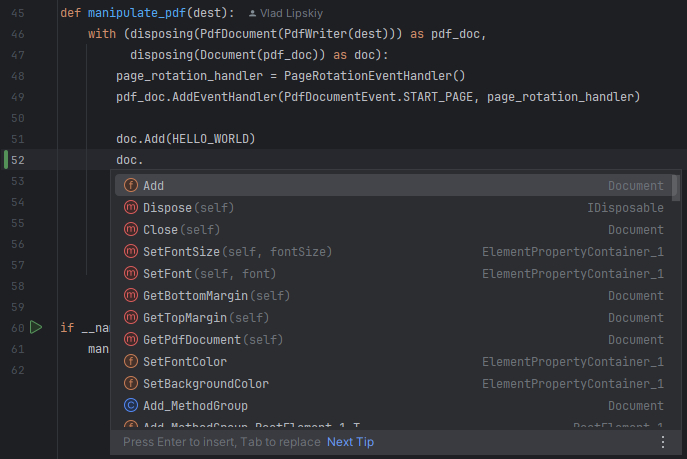
Not only the editor is no longer angry, but we also have auto-completion working. Isn't that nice?
In the example repository you should get stubs automatically within the itextpy package. They are generated with this relatively simple script. It downloads a fork of the stub generation tool, builds it locally and then uses it to generate stubs for iText, which are later bundled in the wheel.
As for regular .NET classes, we've excluded them from the wheel as it would be a bit weird for iText to provide them. Instead one of our developers generated, tweaked and pushed .NET Standard stubs to PyPI.
This package is included as a dependency of the example itexpy package. It is not an ideal situation, as you don't need these stubs at runtime, but it makes it easier for you to set up a working development environment. In the end, even if you don't need to process PDFs, our investigation might still be useful for your own Python.NET adventures.
Surely It Can’t Be That Easy?
To test everything out, we've started converting some of our .NET samples to Python ones. And, to our surprise, most of it just automagically worked. For the most part, you could just port code one-to-one, with most of the differences coming from syntax and stylistic differences (ex. snake_case vs. PascalCase).
But even then, there were still some minor caveats. We'll go through some of them here.
Implementing .NET interfaces in Python
Occasionally, you will encounter APIs which will require you to implement some sort of interface to get the result you want. Some examples include common patterns like dependency injection, strategy or even just regular event handlers and loggers. And at this point you'll wonder, how can I implement a .NET interface in Python?
Somewhat surprisingly, this magically almost works. You can implement .NET interfaces as if they were regular Python ones. And with type hints your IDE will even help you implement them with useful warnings and implementation generators!
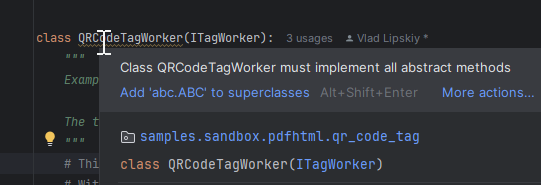
But if you try to use it, that's when the "almost" part comes in. You'll, most likely, get some weird errors like this:
TypeError: interface takes exactly one argument
And this is an ideal scenario. If you try to derive from a non-abstract class and override some of its methods, you'll find out that .NET code doesn't call your Python code at all!
While you won't find anything about this in the official documentation, you might stumble upon a solution elsewhere. As it turns out, in such cases your class needs to have a magic __namespace__ attribute, which will define, in which namespace the .NET adapter class for your Python class will reside. This is the reason, why you will see these constructions in our samples:
# This is the namespace for this object in .NET
# Without this, it won't work with Python.NET
__namespace__ = "Sandbox.PdfHtml"
So when in doubt, just add __namespace__ and you are good to go.
The Adventure of the AbstractPdfDocumentEventHandler
At this point, we know that we can derive from .NET classes and easily override virtual public methods for our needs. Let's say, for example, you want to add a watermark on your PDF document. For this you can just register a custom event handler, which will trigger when a PDF page has been finished. And then in the handler itself you'll draw the watermark in the OnAcceptedEvent method. Easy!
After running your script you'll notice an odd error, when script execution gets to the event handler definition:
Traceback (most recent call last):
File "watermarking.py", line 26, in <module>
class WatermarkingEventHandler(AbstractPdfDocumentEventHandler):
TypeError: Method 'OnAcceptedEvent' in type 'Sandbox.Events.WatermarkingEventHandler' from assembly 'Python.Runtime.Dynamic, Version=0.0.0.0, Culture=neutral, PublicKeyToken=null' does not have an implementation.
But the implementation is, literally, there! And the magical __namespace__ is there as well. Though PyCharm didn't mark the method as if it is overriding something...
Actually, the reason is pretty simple. While Python doesn't really have method access modifiers, in the .NET world they exist. And if you look in the documentation, OnAcceptedEvent is not public, it is protected internal instead.
As it turns out, Python.NET only exposes public methods. So when it tries to create the .NET sibling of your Python class, the abstract method is still there without an implementation. We've just added a new public function, we didn't override the existing abstract protected one!
Sadly, there doesn't seem to be a convenient way to resolve this issue. In our example we've added a tiny C# itext.python.compat library, which, at the moment, adds just a single class:
namespace iText.Kernel.Pdf.Event
{
public abstract class PyAbstractPdfDocumentEventHandler : AbstractPdfDocumentEventHandler
{
protected sealed override void OnAcceptedEvent(AbstractPdfDocumentEvent @event)
{
_OnAcceptedEvent(@event);
}
public abstract void _OnAcceptedEvent(AbstractPdfDocumentEvent @event);
}
}
Pretty simple, and the method naming now also makes more sense with how it would be done in Python. So if you need to make an event handler in Python, inherit from PyAbstractPdfDocumentEventHandler instead.
Practically speaking, not being able to access protected methods shouldn't be a common issue, as in the majority of cases you will work with interfaces. But AbstractPdfDocumentEventHandler happened to be a “black swan” in this, and warranted adding a workaround for it.
Your Abstractions Are Leaking!
Most of the time Python.NET does a great job in dressing up .NET classes to look like Python ones. Very often you'll be passing regular Python strings and lists to .NET methods without even noticing and it will just work. If not for PascalCase or longer than usual package name chains, you could be fooled into thinking that you are using a regular Python library.
But sometimes that illusion breaks and more .NET code starts creeping inside your Python scripts. Here are some of the examples we've found.
Why is PdfDocument Not Closeable?
In garbage collected languages, when you are working with handles or files it is useful to be able to close them ASAP, and not just when the garbage collector decides it is time to close them for you. So, you would often use context managers for this task, like this:
with open("output.txt", "w") as f:
f.write("Hello, World!")
In the .NET world you have an IDisposable interface to achieve similar functionality. Sadly, Python.NET 3.0.5 doesn't automatically implement the context manager protocol for IDisposable classes. Annoyingly, you cannot use contextlib.closing either, as C# classes won't usually have a lower-case close method.
To circumvent this we've added a small disposing context manager implementation. So you can write code like this:
from itextpy.util import disposing
with disposing(PdfDocument(PdfReader("input.pdf"))) as doc:
print(f"Page Count: {doc.GetNumberOfPages()}")
As an interesting side-note, if you check the implementation of the context manager, you might notice, that we've written IDisposable.Dispose(obj) instead of the more obvious obj.Dispose(). This is very deliberate and if you try to write it the obvious way, you will encounter an error like this:
File "itextpy/util.py", line 68, in disposing
obj.Dispose()
^^^^^^^^^^^
AttributeError: 'PdfDocument' object has no attribute 'Dispose'
Well that's pretty confusing, as PdfDocument implements IDisposable... But if you try writing the same obj.Dispose() in C# it will also not work!
As to why this happens, in some of our classes IDisposable is implemented explicitly. In practice underneath in the CLR it means, that the Dispose method is, actually, private in PdfDocument, so it is not forwarded directly by Python.NET. In order to call Dispose you will need to explicitly upcast the object to IDisposable beforehand.
But then you might be thinking, how would I even upcast it this way in Python? I don't have the as operator available and I cannot do the C-style cast either. This is where the explicit self in Python methods comes in. We can just call IDispose.Dispose directly as a free function and pass this explicitly, which in this case will be equivalent to upcasting the object in C#. Pretty handy, huh?
What About Type Introspection?
Often enough you will encounter a method where its return type is more abstract that you would like, as you are 100% sure about its actual type from the context surrounding the function call. Like this, for example:
PdfString s = (PdfString) PdfString("Hello").MakeIndirect(pdfDoc);
You know, that MakeIndirect will return a PdfString, but you still need to explicitly cast it, since the method is defined in PdfObject and returns that instead.
But we are in the Python land with duck typing at our hands. Surely it doesn't matter here?
Actually, it didn't for a while, but in Python.NET 3.0.0 a pull request was merged, which changed that: Wrap returned objects in interface if method return type is interface.
This had a noble goal of handling issues like the one with the explicitly implemented IDisposable we mentioned before. It would be weird that a method returns IDisposable, but then we are unable to do obj.Dispose(). But on the other hand, now duck typing doesn't work in such cases. You would know that the IDisposable you've received is just a PdfDocument, but none of the methods work!
We encountered this problem, when we tried to convert the following class to Python:
class CustomHTagWorker : HTagWorker
{
public CustomHTagWorker(IElementNode element, ProcessorContext context)
: base(element, context)
{
}
public override IPropertyContainer GetElementResult()
{
var elementResult = base.GetElementResult();
if (!(elementResult is Div result))
{
return elementResult;
}
foreach (IElement child in result.GetChildren())
{
if (child is Paragraph paragraph)
{
paragraph.SetNeutralRole();
}
}
return elementResult;
}
}
The code is simple; for HTML <div> elements we get, we want to call SetNeutralRole on any immediate child <p> element. But GetElementResult returns an interface, how do we check its type? Usually isinstance from Python will just work, even for .NET classes, but here it doesn't because of the interface wrapper hiding the class.
Thankfully, there is an escape hatch available. On such interface wrappers there will be two magic fields: __implementation__ and __raw_implementation__. These allow you to get the actual concrete object back, which resolves the issue we are having here.
Why is one of them raw though, what is the difference? For example, if a method has IEnumerable<char> as the return type, but it actually returns a System.String, the result in both fields will be different. __raw_implementation__ will give you access to the System.String from the .NET world, while __implementation__ will give you an already converted Python str.
To make handling this easier, we've added some utility functions, which look something like this:
def clr_to_implementation(obj: object) -> Any:
if hasattr(obj, '__implementation__'):
return obj.__implementation__
return obj
def clr_isinstance(obj: object, class_or_tuple: type | tuple[Any, ...]) -> bool:
return isinstance(clr_to_implementation(obj), class_or_tuple)
def clr_try_cast(obj: object, typ: type[T]) -> T | None:
obj = clr_to_implementation(obj)
return obj if isinstance(obj, typ) else None
def clr_cast(obj: object, typ: type[T]) -> T:
obj = clr_try_cast(obj, typ)
if obj is None:
raise TypeError('unable to cast object')
return obj
And with that available, the class conversions works out quite nicely:
class CustomHTagWorker(HTagWorker):
__namespace__ = "Sandbox.PdfUa"
def __init__(self, element: IElementNode, context: ProcessorContext):
super().__init__(element, context)
def GetElementResult(self) -> IPropertyContainer:
element_result = HTagWorker.GetElementResult(self)
result = clr_try_cast(element_result, Div)
if result is None:
return element_result
for child in result.GetChildren():
paragraph = clr_try_cast(child, Paragraph)
if paragraph is not None:
paragraph.SetNeutralRole()
return element_result
Why Doesn't It Like My Python List?
A lot of type conversions work automagically with Python.NET, which is very nice. Your Python str will be automatically converted to System.String and char[], numbers will be converted to the corresponding .NET floating-point and integer types, a list of int will be converted to int[] and so on.
But some of the conversions you might think are trivial are not made automatically, which forces you to use the additional .NET types. We'll include some of the examples we've encountered.
First, lets look at IssuingCertificateRetriever and its SetTrustedCertificates method. It expects an ICollection<IX509Certificate> as its arguments, so you might write something like this:
trusted_certs = [root_cert]
certificate_retriever = IssuingCertificateRetriever()
certificate_retriever.SetTrustedCertificates(trusted_certs)
This won't work. If you try to run this code, you'll get the following exception:
Python.Runtime.PythonException: 'list' value cannot be converted to System.Collections.Generic.ICollection`1[iText.Commons.Bouncycastle.Cert.IX509Certificate]
It would be nice if it had some sort of interface implementing wrapper for this, but it doesn't. So you would need to write code like this instead:
from System.Collections.Generic import List
trusted_certs = List[IX509Certificate]()
trusted_certs.Add(root_cert)
certificate_retriever = IssuingCertificateRetriever()
certificate_retriever.SetTrustedCertificates(trusted_certs)
In this case we create an actual generic List from .NET, and use that directly. You might encounter similar issues with dictionaries and sets as well.
A more surprising case was with delegates. For this lets look at ValidatorChainBuilder and its WithIssuingCertificateRetrieverFactory method. It needs a function with no parameters, which returns an IssuingCertificateRetriever. Seems pretty easy, lets try it:
def factory():
return IssuingCertificateRetriever()
builder = ValidatorChainBuilder().WithIssuingCertificateRetrieverFactory(factory)
Nope, this is not good enough:
Python.Runtime.PythonException: 'function' value cannot be converted to System.Func`1[iText.Signatures.IssuingCertificateRetriever]
The same thing happens, if you try to use a lambda instead. That's a bummer. To handle this you would need to create the delegate manually, like this:
from System import Func
def factory():
return IssuingCertificateRetriever()
delegate_factory = Func[IssuingCertificateRetriever](factory)
builder = ValidatorChainBuilder().WithIssuingCertificateRetrieverFactory(delegate_factory)
The next and the last case is much more understandable, but is still something you need to keep in mind. A lot of APIs which interact with raw bytes, either reading or writing, will expect you to provide a Stream. Let's take PdfReader, for example, and try to read data from a file:
with open("input.pdf", "rb") as f:
reader = PdfReader(f)
At this point you might have already guessed the result:
Python.Runtime.PythonException: '_io.BufferedReader' value cannot be converted to System.IO.Stream
While with PdfReader you have the option to provide the file path instead, so that the file is opened within .NET, but this is not the case with every API. So we will need to bring classes from the standard library to help us again:
from itextpy.util import disposing
from System.IO import FileStream, FileMode, FileAccess
with disposing(FileStream("input.pdf", FileMode.Open, FileAccess.Read)) as f:
reader = PdfReader(f)
Personally, this case not being automated seems much more reasonable. While you could make a Stream wrapper for Python file handling classes, would you want your IO become even slower with all the Python <-> .NET jumps when reading chunks? Most likely not. But if you have a case, when you cannot open the file twice, you can always make a Stream subclass in Python yourself.
Overall, these cases are not a big deal. It already seems like a miracle, how rarely you would need explicitly use .NET types from the standard library. So even if you didn't work with .NET a lot, the overall Python.NET experience is pretty comfy.
So What Can We Do With All Of This?
As mentioned before, in the itext-python-example repository you can find build instructions for an itextpy wheel, which you can install in your Python environment and start playing around with all of this. Feel free to check out our samples directory. There are not a lot of examples at the moment, but it should be enough to get you started for tasks like table creation, document merging, creating forms, generating documents from HTML and more.
One of the more interesting examples is table of contents generation with the help of a large language model. To run this sample without any code changes, you'll need to install an additional openai package and have a local Ollama instance running with a Qwen2.5 model pulled beforehand.
The algorithm is pretty simple:
-
Read a PDF document with the help of iText and covert it into a text form.
-
Send the document in text form to the language model, and ask it to generate a table of contents for us.
-
Parse the textual response from the API into a tree-like model of the table.
-
Try to match table entries with the text on the pages, so that we could have a page number and a link for each one.
-
Getting back to iText again, generate a basic PDF page with the table of contents data, page numbers and links to those pages.
-
Prepend that page to the original document and save it.
If you've worked with language models, you'll know how difficult it might be to get them do the exact thing you want. For example, asking it to also give us page numbers for each entry might be a bit of a reach for our big fancy text generators. So, in this case we had to improvise a bit. But, in the end, the result is pretty serviceable.
Make sure that you increase the token window size in Ollama to a nice big number before running the sample. The default value is just 4096 tokens, which, most likely, won't be enough to retain the whole document in the context of the model. In that case the result will be more random and unrelated than you might expect.
If you don't have a machine beefy enough to run the models locally, you can always change the OPENAI_* variables in the script to use an external API instead, like ChatGPT.
Next time we will show you more examples of how you can augment your typical Python workloads with the robust document manipulating capabilities of iText within your grasp.
Dogfooding iText for Python
To wrap up this article, we’ve put our money where our mouth is. For the release of iText Core 9.2.0 we’ve generated and digitally signed a PDF version of the release notes using Python as well as pdfHTML.
It’s not just any PDF either, it’s also compliant with the PDF/UA-2 accessibility standard, and embeds the Python project to generate it yourself. Download the file attached to the release notes to try it out!
|
Written by |
Vlad Lipskiy, Research Engineer |