Busted! This isn't a frequently asked question. I made it up because I thought the answer was interesting enough for this book.
The metadata.html HTML file has some metadata added inside its <head> section:
<html>
<head>
<title>Metadata</title>
<meta name="description" content="A page with metadata">
<meta name="keywords" content="metadata, keywords, test">
<meta name="application-name" content="pdfHTML tutorial">
<meta name="author" content="Bruno Lowagie">
</head>
<body>
<h1>Metadata</h1>
<p>Please check the document properties of the PDF file for the metadata.</p>
</body>
</html>
Now let’s convert this simple HTML file to PDF using the C07E08_Metadata (Java/.NET) example.
public void createPdf(String src, String dest) throws IOException {
PdfWriter writer = new PdfWriter(dest, new WriterProperties().addXmpMetadata());
HtmlConverter.convertToPdf(new FileInputStream(src), writer);
}
As you can see, we’ve made sure that we also add metadata in the XMP format.
When we look at the Description tab of the Document Properties, we see the title of the page (<title>), the author (<meta name="author">), the subject (<meta name="description">), the keywords (<meta
name="keywords">), and the application (<meta name="application-name">). The rest of the metadata, such as the creation date, the modification date, and the PDF producer, is added automatically.
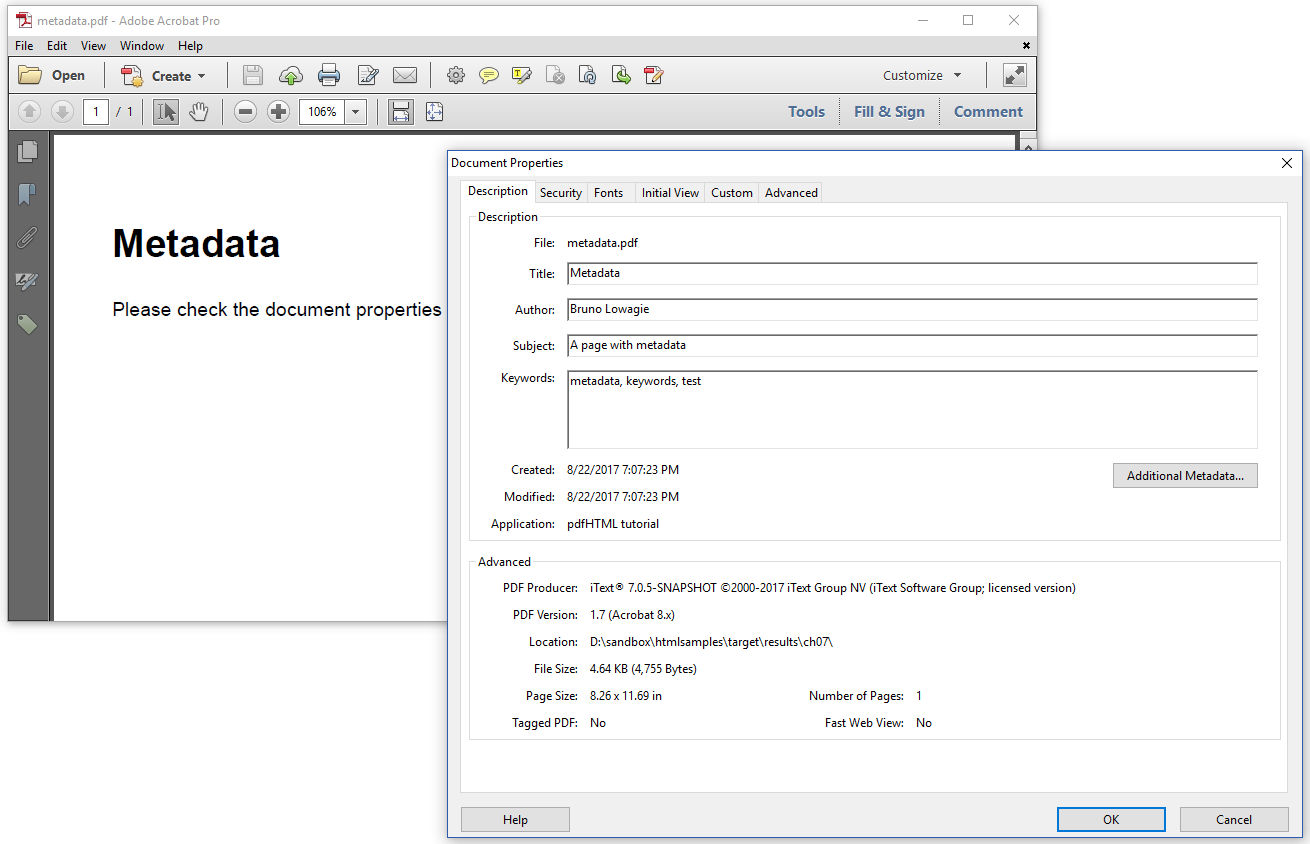
Most of the metadata shown above is information taken from the Info dictionary. This approach of storing metadata is deprecated in PDF 2.0 in favor of XMP metadata.
XMP is metadata stored as a clear text (uncompressed) XML stream inside the PDF. Since we also added XMP metadata in our example, we can click the "Additional Metadata" button. When we go to the "Advanced" view, we can see the structure of an XML file.
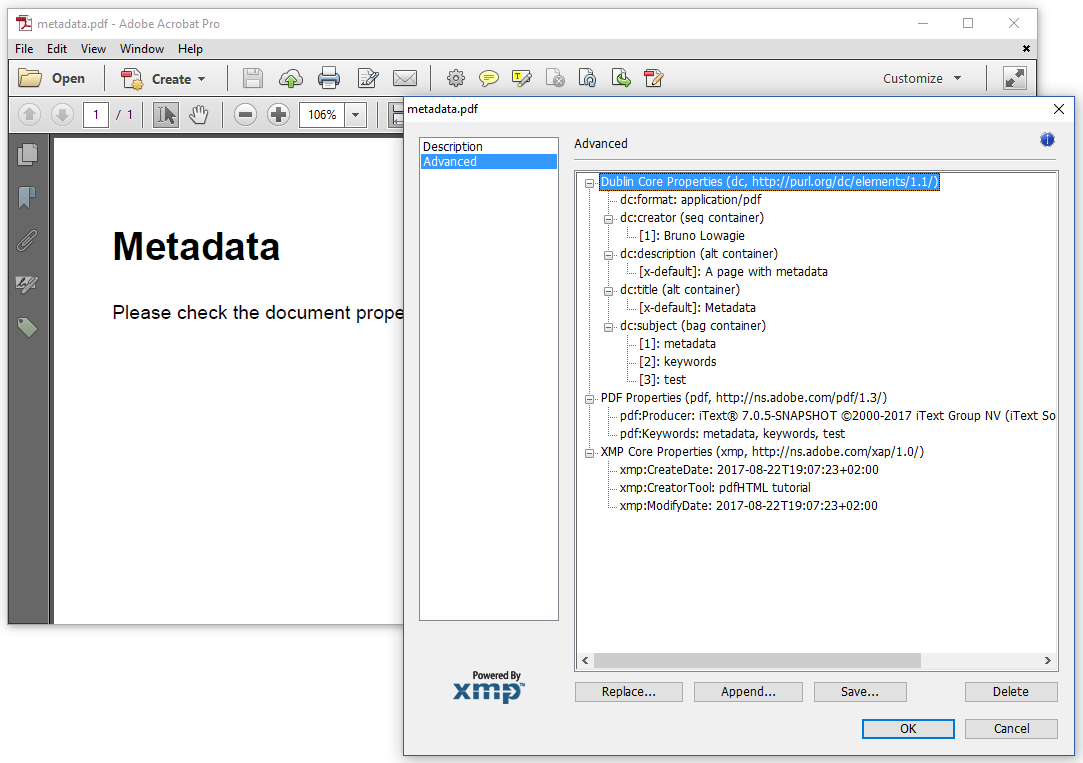
XMP uses slightly different terminology. We see three namespaces: dc (Dublin Core), pdf, and xmp. We recognize the dc:creator (<meta name="author">), the dc:description (<meta name="description">), and the dc:title (<title>). The keywords are stored twice, once as dc:subject, and once as pdf:Keywords (<meta name="keywords">). Finally, there's the xmp:CreatorTool (<meta name="application-name">).
That XML file is also visible when you open the PDF document in a text editor.
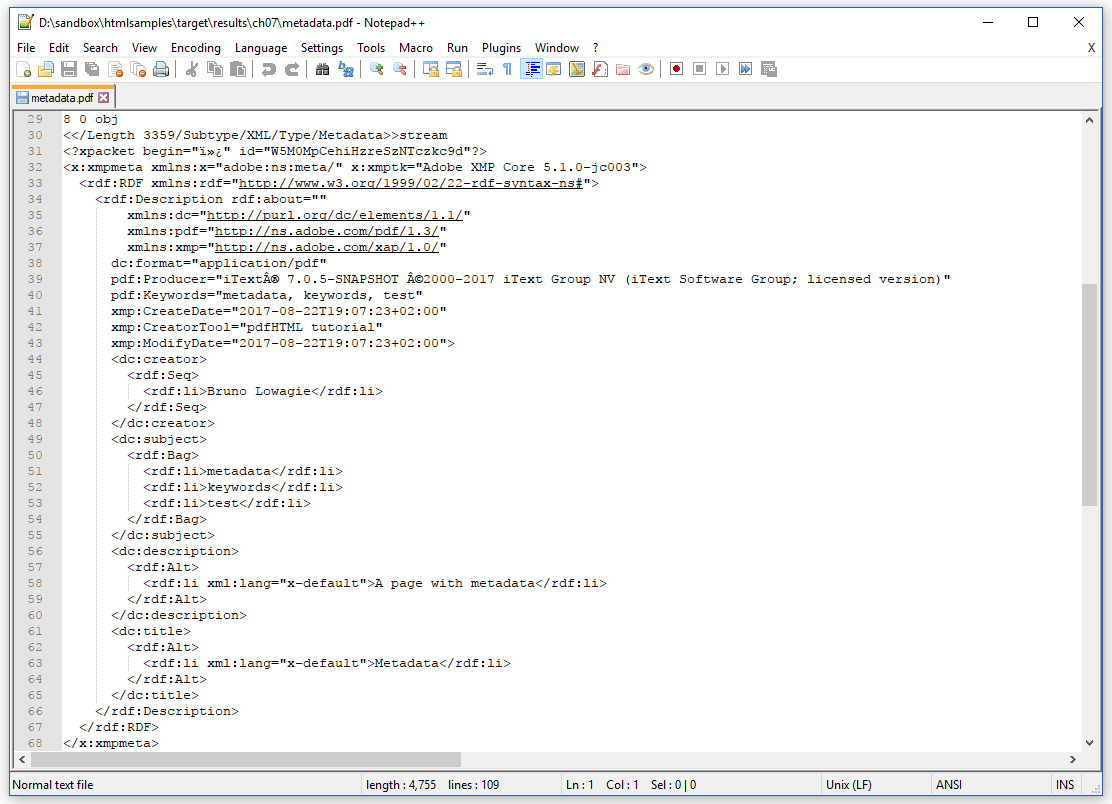
The use of XMP isn't limited to PDF. The goal of XMP is to allow content management systems to extract metadata from every binary file without being aware of the specific syntax of the binary file's format.
For instance: you could have an XMP stream inside a JPEG. Any content management system would be able to extract that XMP from the JPEG without having to use a JPEG library.
The same goes for PDF: you don't need a PDF library to read the XMP metadata from a PDF file. All you have to do is to look for the uncompressed XMP stream inside the otherwise binary file.