While pdfHTML does not evaluate JavaScript, we can solve this problem by using a browser engine to preprocess the HTML + CSS + JavaScript. Some examples of such browser engines are WebKit (Chrome, Safari), Gecko (Firefox), and there are many more. For this example we decided to use Selenium WebDriver for our browser automation, in combination with Headless Chrome.
Our input HTML file is quite simple:
<!DOCTYPE html>
<html>
<body>
<div id="test">Before</div>
<script type="text/javascript">document.getElementById("test").innerHTML = "After";</script>
</body>
</html>
Before JavaScript evaluation this HTML will simply say ‘Before’, while after JavaScript evaluation it should say ‘After’.
So, lets see the output before adding a browser engine into the mix.
JAVA
import com.itextpdf.html2pdf.HtmlConverter;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
public class Main {
public static final String DEST = "results/result.pdf";
public static final String SRC = "src/main/resources/input.html";
static {
new File(DEST).getParentFile().mkdirs();
}
public static void main(String[] args) throws IOException {
String html = new String(Files.readAllBytes(Paths.get(SRC)));
HtmlConverter.convertToPdf(html, new FileOutputStream(DEST));
}
}
C#
using System;
using System.IO;
using iText.Html2pdf;
namespace EvaluatingJS
{
class Program
{
private static String DEST = "output.pdf";
private static String SRC = "input.html";
static void Main(string[] args)
{
String html = File.ReadAllText(SRC);
HtmlConverter.ConvertToPdf(html, new FileStream(DEST, FileMode.Create));
}
}
}
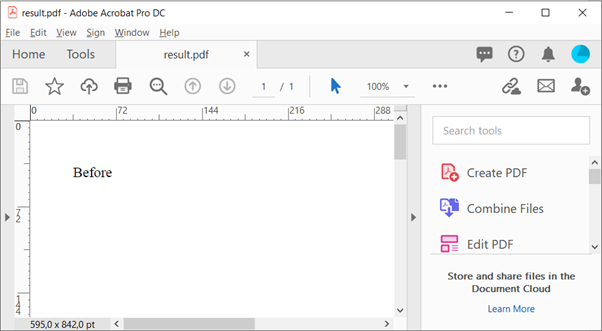
As expected, the JavaScript is not being evaluated.
Now lets try again using our headless browser. We should start by including a library that has the capability to spin up a headless browser for us. In this case we chose Selenium, as it is available for both .NET and Java.
JAVA
import com.itextpdf.html2pdf.HtmlConverter;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
public class Main {
public static final String DEST = "results/result.pdf";
public static final String SRC = "src/main/resources/input.html";
static {
new File(DEST).getParentFile().mkdirs();
}
public static void main(String[] args) throws IOException {
String html = new String(Files.readAllBytes(Paths.get(SRC)));
// We start by setting up our browser driver. The driver version you need here might differ depending on your Selenium version.
// It is also possible to use a different 3rd party library to automatically download the necessary driver.
// This way you don't have to bother with setting the path to the executable. An example of such a library is https://github.com/bonigarcia/webdrivermanager.
System.setProperty("webdriver.chrome.driver", "src/main/resources/chromedriver.exe");
ChromeOptions options = new ChromeOptions();
// Spin up the browser in "headless" mode, this way Selenium will not open up a graphical user interface.
options.addArguments("--headless");
ChromeDriver driver = new ChromeDriver(options);
// Open up the HTML file in our headless browser. This step will evaluate the JavaScript for us.
driver.navigate().to("data:text/html;charset=utf-8," + html);
// Now all we have to do is extract the evaluated HTML syntax and convert it to a PDF using iText's HtmlConverter.
String evaluatedHtml = (String) driver.executeScript("return document.documentElement.innerHTML;");
HtmlConverter.convertToPdf(evaluatedHtml, new FileOutputStream(DEST));
}
}
C#
using System;
using System.IO;
using iText.Html2pdf;
using OpenQA.Selenium.Chrome;
namespace EvaluatingJS
{
class Program
{
private static String DEST = "output.pdf";
private static String SRC = "input.html";
static void Main(string[] args)
{
String html = File.ReadAllText(SRC);
ChromeOptions options = new ChromeOptions();
// Spin up the browser in "headless" mode, this way Selenium will not open up a graphical user interface.
options.AddArgument("--headless");
// I have a copy of the chromedriver.exe file in my 'Debug' folder, as such I can pass "." as an argument and Selenium will automatically load up the correct Driver.
// If your chromedriver.exe file is located elsewhere you will have to provide a path to its parent folder.
// It is also possible to use a different 3rd party library to automatically download the necessary driver.
// This way you don't have to bother with setting the path to the executable. An example could be https://www.nuget.org/packages/Selenium.WebDriver.ChromeDriver/.
ChromeDriver driver = new ChromeDriver(".", options);
// Open up the HTML file in our headless browser. This step will evaluate the JavaScript for us.
driver.Navigate().GoToUrl("data:text/html;charset=utf-8," + html);
// Now all we have to do is extract the evaluated HTML syntax and convert it to a PDF using iText's HtmlConverter.
String evaluatedHtml = (String) driver.ExecuteScript("return document.documentElement.innerHTML;");
HtmlConverter.ConvertToPdf(evaluatedHtml, new FileStream(DEST, FileMode.Create));
}
}
}
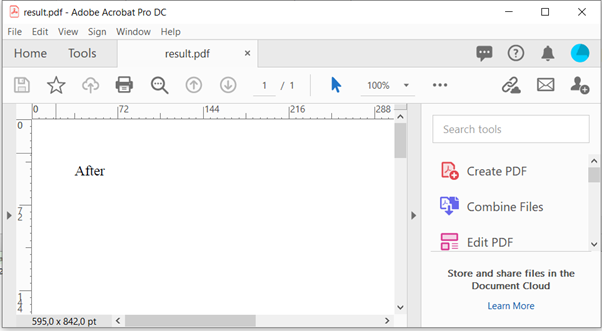
As you can see, this time the JavaScript was evaluated correctly. And our output reflects the state of the HTML after the JavaScript is executed.
Notes:
-
JavaScript can only be evaluated if it will be executed when the HTML is loaded. If the script is bound to an action (i.e. a button press) instead of document loading, it will not be processed by the browser engine.
-
For more complex documents, you might need to wait for JS to load and execute. You can do this by making use of WebDriver Waits.