Which version?
This Tutorial was written with iText 7.0.x in mind, however, if you go to the linked Examples you will find them for the latest available version of iText. If you are looking for a specific version, you can always download these examples from our GitHub repo (Java/.NET).
When writing a tutorial, I always prefer working with real-world use cases. That's not always easy because real-world use cases can get quite complex, whereas a tutorial needs to explain different concepts as simple as possible. While I was looking for a theme for this tutorial, I stumbled upon the short story "The Strange Case of Dr. Jekyll and Mr. Hyde" by Robert Louis Stevenson. I made a first example turning a plain text file into a PDF eBook and I liked the result. When I discovered how many movies, cartoons and series were made based on this work, I saw an opportunity to create a database that could be converted into a table. The movie posters could serve as sample material when discussing images in PDF.
But first things first: let's start with an example that displays the title and the author using different fonts. This will allow us to introduce some classes such as FontProgram and PdfFont.
Creating a PdfFont object
If we look at figure 1.1, we see that three different fonts were used to create a PDF document with the title and the author of the Jekyll and Hyde story: Helvetica, Times-Bold and Times-Roman. In reality, three other fonts are used by the viewer: ArialMT, TimesNewRomanPS-BoldMT and TimesNewRomanPSMT.
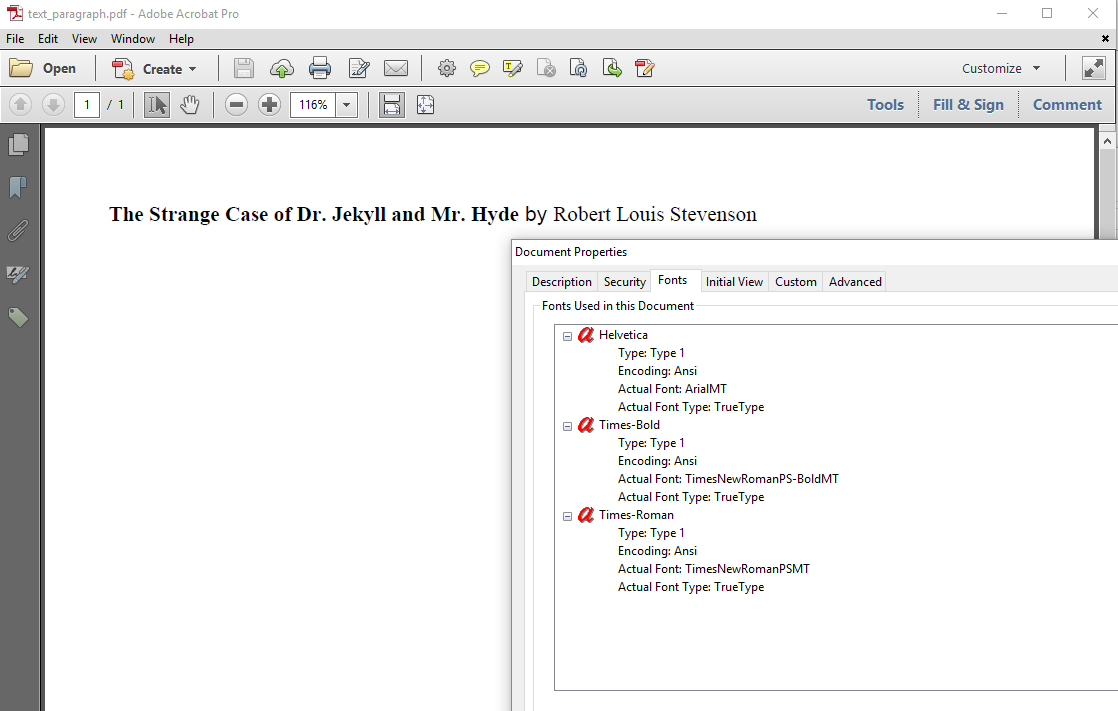
The MT in the names of the Actual Font refers to the vendor of the fonts: the Monotype Imaging Holdings, Inc. These are fonts shipped with Microsoft Windows. If you'd open the same file on a Linux machine, other fonts would be used as actual fonts. This is typically what happens when you don't embed fonts. The viewer searches the operating system for the fonts that are needed to present the document. If a specific font can be found, another font will be used instead.
Traditionally, there are 14 fonts that every PDF viewer should be able to recognize and render in a reliable way: four Helvetica fonts (normal, bold, oblique, and bold-oblique), four Times-Roman fonts (normal, bold, italic, and bold-italic), four Courier fonts (normal, bold, oblique, and bold-oblique), Symbol and Zapfdingbats. These fonts are often referred to as the Standard Type 1 fonts. Not every viewer will use that exact font, but it will use a font that looks almost identical.
To create the PDF shown in figure 1.1, we used three of these fonts: we defined two fonts explicitly; one font was defined implicitly. See the Text_Paragraph example.
PdfDocument pdf = new PdfDocument(new PdfWriter(dest));
Document document = new Document(pdf);
PdfFont font = PdfFontFactory.createFont(FontConstants.TIMES_ROMAN);
PdfFont bold = PdfFontFactory.createFont(FontConstants.TIMES_BOLD);
Text title =
new Text("The Strange Case of Dr. Jekyll and Mr. Hyde").setFont(bold);
Text author = new Text("Robert Louis Stevenson").setFont(font);
Paragraph p = new Paragraph().add(title).add(" by ").add(author);
document.add(p);
document.close();
In line 1, we create a PdfDocument using a PdfWriter as parameter. These are low-level objects that will create PDF output based on your content. We're creating a Document instance in line 2. This is a high-level object that will allow you to create a document without having to worry about the complexity of PDF syntax.
In lines 5 and 6, we create a PdfFont using the PdfFontFactory. In the FontConstants object, you'll find a constant for each of the 14 Standard Type 1 fonts. In line 7, we create a Text object with the title of Stevenson's short story and we set the font to TIMES_BOLD. In line 8, we create a Text object with the name of the author and we set the font to TIMES_ROMAN. We can't add these Text objects straight to the document, but we add them to a BlockElement, more specifically a Paragraph, in line 9.
Between the title and the author, we add " by " as a String object. Since we didn't define a font for this String, the default font of the Paragraph is used. In iText, the default font is Helvetica. This explains why we see the font Helvetica listed in the font overview in figure 1.1.
In line 10, we add the paragraph to the document object; we close the document object in line 11.
We have created our first Jekyll and Hyde PDF using fonts that aren't embedded. As a result, slightly different fonts can be used when rendering the document. We can avoid this by embedding the fonts.
Creating a FontProgram object
iText supports the Standard Type 1 fonts, because the io-jar contains the Adobe Font Metrics (AFM) files of those 14 fonts. These files contain the metrics that are needed to calculate the width and the height of words and lines. This is needed to create the layout of the text.
If we want to embed a font, we need a font program. In the case of the Standard Type 1 fonts, this font program is stored in PostScript Font Binary (PFB) files. In the case of the 14 standard Type 1 fonts, those files are proprietary; they can't be shipped with iText because iText Group doesn't have a license to do so. We are only allowed to ship the metrics files.
As a consequence, iText can't embed these 14 fonts, but this doesn't mean that iText can't embed fonts. In the Text_Paragraph_Cardo example, we use three font programs of the Cardo font family to create a PDF with embedded subsets of those fonts. The Cardo font programs were released under the Summer Institute of Logistics (SIL) Open Font License (OFL).
The result is shown in figure 1.2.
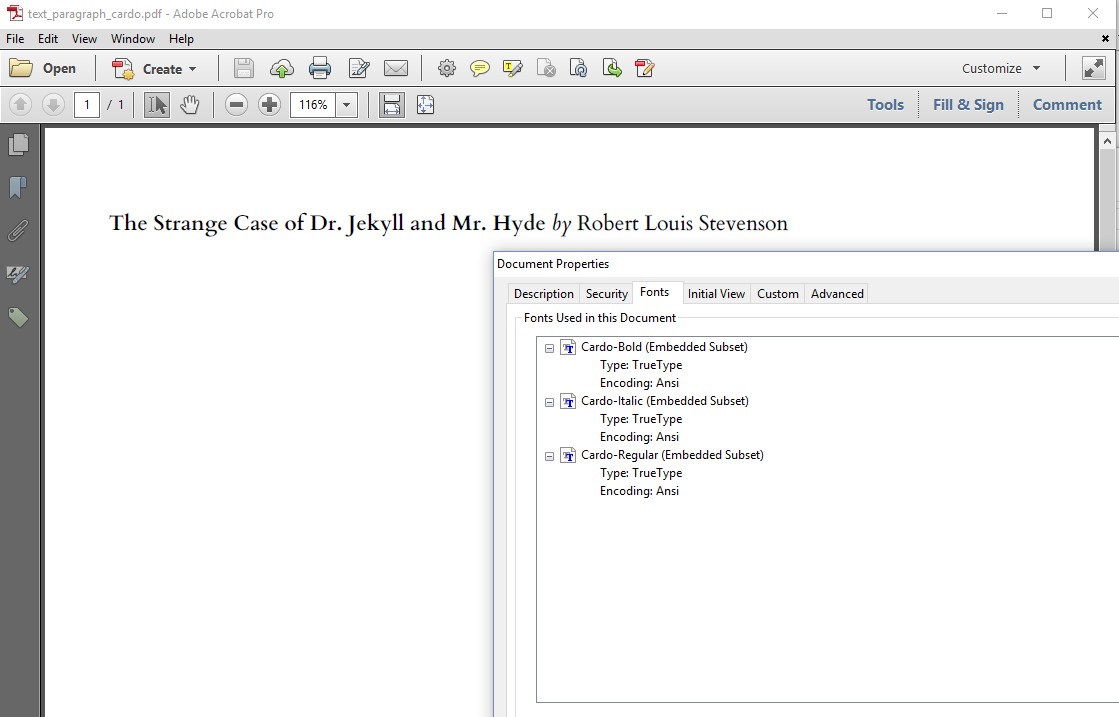
First we need the path to the font programs for the three Cardo fonts: Cardo-Regular.ttf, Cardo-Bold.ttf and Cardo-Italic.ttf:
public static final String REGULAR =
"src/main/resources/fonts/Cardo-Regular.ttf";
public static final String BOLD =
"src/main/resources/fonts/Cardo-Bold.ttf";
public static final String ITALIC =
"src/main/resources/fonts/Cardo-Italic.ttf";
Next, we can use these paths to create a FontProgram object obtained from the FontProgramFactory.
FontProgram fontProgram =
FontProgramFactory.createFont(REGULAR);
Using the FontProgram instance, we can create a PdfFont object.
PdfFont font = PdfFontFactory.createFont(
fontProgram, PdfEncodings.WINANSI, true);
Note that we pass an encoding (PdfEncodings.WINANSI), and that we indicate that the font needs to be embedded (true). We can also use the shorthand notation by passing the path to the font program to the PdfFontFactory.
PdfFont bold = PdfFontFactory.createFont(BOLD, true);
PdfFont italic = PdfFontFactory.createFont(ITALIC, true);
We can now use these three fonts to compose our Paragraph object:
Text title =
new Text("The Strange Case of Dr. Jekyll and Mr. Hyde").setFont(bold);
Text author = new Text("Robert Louis Stevenson").setFont(font);
Paragraph p = new Paragraph().setFont(italic)
.add(title).add(" by ").add(author);
document.add(p);
The font Helvetica no longer appears in the font list in figure 1.2 because we changed the default font for the paragraph at the level of the Paragraph object.
The difference between FontProgram and PdfFont
In most of the examples that follow, we'll always use the PdfFontFactory to create PdfFont objects. That object always uses a FontProgram instance internally, but there is one important difference between the PdfFont and the FontProgram class that you need to be aware of:
-
A
FontProgramobject can be used to create differentPdfFontobjects for different PDF documents. -
A
PdfFontobject can only be used for a singlePdfDocument.
You can use a PdfFont object only once because it keeps track of all the glyphs that are needed in that specific document. By doing so, the full font program doesn't need to be added to the PDF; adding a subset of the font program is sufficient. This can result in much smaller PDF files.
Let's take a look at the Text_Paragraph_Cardo2 example:
protected PdfFont font;
protected PdfFont bold;
protected PdfFont italic;
public static void main(String args[]) throws IOException {
File file = new File(DEST);
file.getParentFile().mkdirs();
C01E02_Text_Paragraph_Cardo2 app =
new C01E02_Text_Paragraph_Cardo2();
FontProgram fontProgram =
FontProgramFactory.createFont(REGULAR);
FontProgram boldProgram =
FontProgramFactory.createFont(BOLD);
FontProgram italicProgram =
FontProgramFactory.createFont(ITALIC);
for (int i = 0; i < 3; ) {
app.font = PdfFontFactory.createFont(
fontProgram, PdfEncodings.WINANSI, true);
app.bold = PdfFontFactory.createFont(
boldProgram, PdfEncodings.WINANSI, true);
app.italic = PdfFontFactory.createFont(
italicProgram, PdfEncodings.WINANSI, true);
app.createPdf(String.format(DEST, ++i));
}
}
public void createPdf(String dest) throws IOException {
PdfDocument pdf = new PdfDocument(new PdfWriter(dest));
Document document = new Document(pdf);
Text title =
new Text("The Strange Case of Dr. Jekyll and Mr. Hyde")
.setFont(bold);
Text author = new Text("Robert Louis Stevenson")
.setFont(font);
Paragraph p = new Paragraph()
.setFont(italic).add(title).add(" by ").add(author);
document.add(p);
document.close();
}
In this example, we create three FontProgram instances, fontProgram, boldProgram, and italicProgram. We reuse these instances three times to create three PDF documents. For each PDF document, we create new PdfFont instances.
This following code snippet is wrong because we are trying to reuse PdfFont instances for different PDF documents:
public static void main(String args[]) throws IOException {
File file = new File(DEST);
file.getParentFile().mkdirs();
C01E02_Text_Paragraph_Cardo2 app =
new C01E02_Text_Paragraph_Cardo2();
app.font = PdfFontFactory.createFont(REGULAR, true);
app.bold = PdfFontFactory.createFont(BOLD, true);
app.italic = PdfFontFactory.createFont(ITALIC, true);
for (int i = 0; i < 3; ) {
app.createPdf(String.format(DEST, ++i));
}
}
If we'd try this code, the following error would be thrown:
com.itextpdf.kernel.PdfException: Pdf indirect object belongs to other PDF document. Copy object to current pdf document.
This exception is thrown the second time the createPdf() method is called. We're attempting to use a PdfFont instance that belongs to the PDF that was created the first time the createPdf() method was called.
The importance of embedding
Figure 1.3 shows what would happen if we don't embed the fonts.
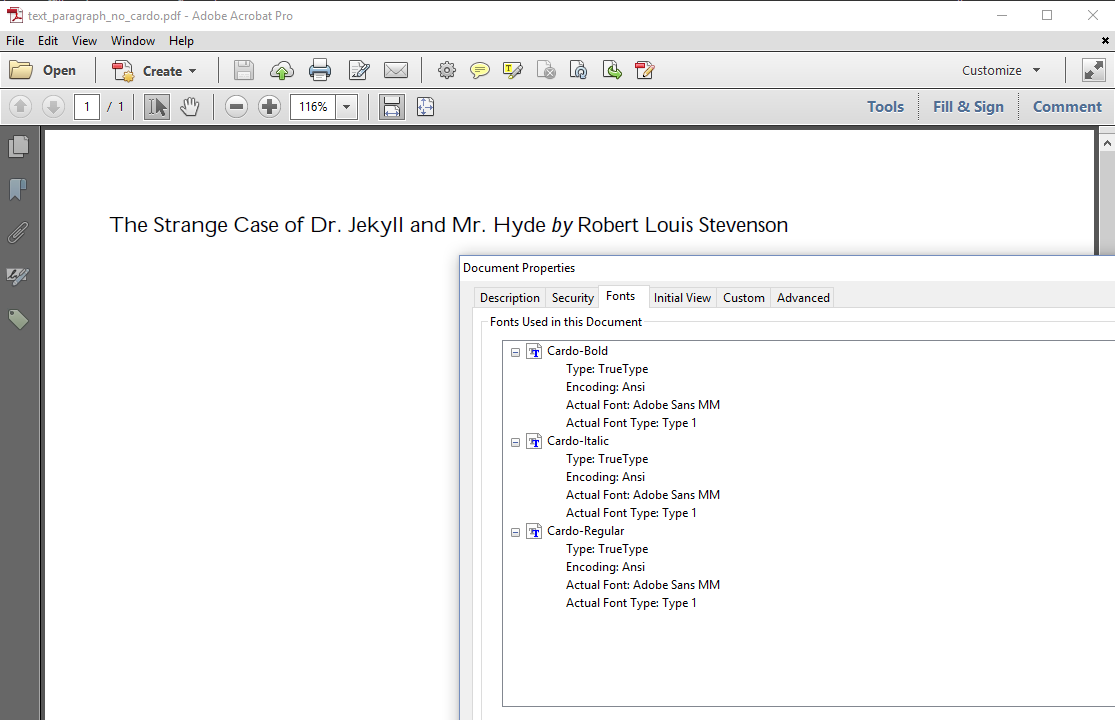
In the Text_Paragraph_NoCardo example, we have defined the fonts like this:
PdfFont font = PdfFontFactory.createFont(REGULAR);
PdfFont bold = PdfFontFactory.createFont(BOLD);
PdfFont italic = PdfFontFactory.createFont(ITALIC);
The constants REGULAR, BOLD and ITALIC refer to the correct Cardo .ttf files, but we omitted the parameter that tells iText to embed the font. Incidentally, the Cardo fonts aren't present on my PC. Adobe Reader replaced them with Adobe Sans MM. As you can see, the result doesn't look nice. If you don't use any of the standard Type 1 fonts, you should always embed the font.
The problem is even worse when you try to create PDFs in different languages. In figure 1.4, we try to add some text in Czech, Russian and Korean. The Czech text looks more or less OK, but we'll soon discover that there one character missing. The Russian and Korean text is invisible.
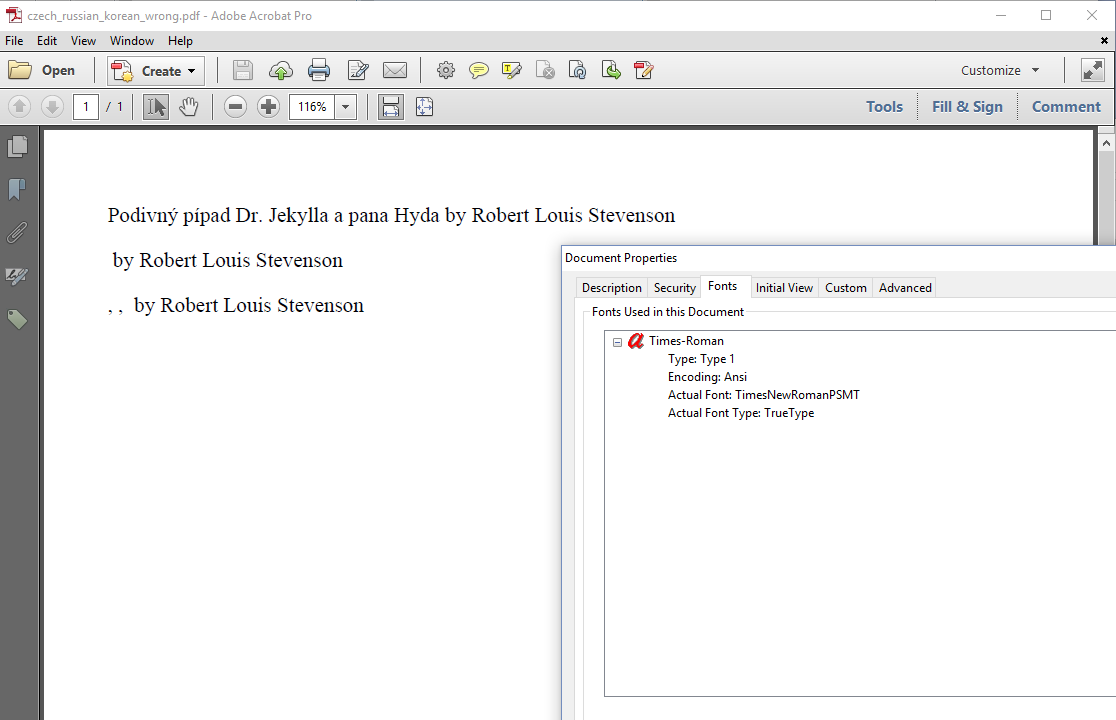
Not embedding the font isn't the only problem here. We also need to define the appropriate encoding.
Choosing the appropriate encoding
In figure 1.4, we tried to render the following text:
Podivný případ Dr. Jekylla a pana Hyda by Robert Louis Stevenson
Странная история доктора Джекила и мистера Хайда by Robert Louis Stevenson
하이드, 지킬, 나 by Robert Louis Stevenson
The first line is the Czech translation of "The Strange Case of Dr. Jekyll and Mr. Hyde." If you look closely at figure 1.4, you'll see that the character ř is missing. That's because the ř character is missing in the Winansi encoding. Winansi, also known as code page 1252 (CP-1252), Windows 1252, or Windows Latin 1, is a superset of ISO 8859-1 also known as Latin-1. It's a character encoding of the Latin alphabet, used by default in many applications on Western operating systems.
For the Czech text, we need to use another encoding. One option is to use code page 1250, an encoding to represent text in Central European and Eastern European languages that use Latin script. The second line reads as Strannaya istoriya doktora Dzhekila i mistera Khayda. For this text, we could use code page 1251, an encoding designed to cover languages that use the Cyrillic script. Cp1250 and Cp1251 are 8-bit character encodings. The third line is Korean for Hyde, Jekyll, Me, a South-Korean television series loosely based on the Jekyll and Hyde story. We can't use an 8-bit encoding for Korean. To render this text, we need to use Unicode. Unicode is a computing industry standard for the consistent encoding, representation, and handling of text expressed in most of the world's writing systems.
When you create a font using an 8-bit encoding, iText will create a simple font for the PDF. A simple font consists of at most 256 characters that are mapped to at most 256 glyphs. When you create a font using Unicode (in PDF terms: Identity-H for horizontal writing systems or Identity-V for vertical writing systems), iText will create a composite font. A composite font can contain 65,536 characters. This is less than the total number of available code points in Unicode (1,114,112). This means that no single font can contain all possible characters in every possible language.
Instead of Cp1250 and Cp1251, we could also use Unicode for the Czech and Russian text. Actually, when we store hard-coded text in source code, it is preferred to store Unicode values.
public static final String CZECH =
"Podivn\u00fd p\u0159\u00edpad Dr. Jekylla a pana Hyda";
public static final String RUSSIAN =
"\u0421\u0442\u0440\u0430\u043d\u043d\u0430\u044f "
+ "\u0438\u0441\u0442\u043e\u0440\u0438\u044f "
+ "\u0434\u043e\u043a\u0442\u043e\u0440\u0430 "
+ "\u0414\u0436\u0435\u043a\u0438\u043b\u0430 \u0438 "
+ "\u043c\u0438\u0441\u0442\u0435\u0440\u0430 "
+ "\u0425\u0430\u0439\u0434\u0430";
public static final String KOREAN =
"\ud558\uc774\ub4dc, \uc9c0\ud0ac, \ub098";
We'll use the values CZECH, RUSSIAN and KOREAN in our next couple of examples.
Why should we always use Unicode notations for special characters?
When the source code file is stored on disk, committed to a version control system, or transferred in any way, there's always a risk that the encoding gets lost. If a Unicode file is stored as plain text, two-byte characters change into two single-byte characters. For example, the character 킬 with Unicode value \ud0ac will change into two characters with ASCII code d0 and ac. When this happens the syllable 킬 (pronounced as "kil") changes into Ь and the text becomes illegible. It is good practice to use the Unicode notation as done in the above snippet; this will help you avoid encoding problems with your source code.
Using the correct encoding isn't sufficient to solve every font problem you might encounter. In the Czech_Russian_Korean_Wrong example, we create the Paragraph objects like this:
PdfFont font = PdfFontFactory.createFont(FontConstants.TIMES_ROMAN);
document.add(new Paragraph().setFont(font)
.add(CZECH).add(" by Robert Louis Stevenson"));
document.add(new Paragraph().setFont(font)
.add(RUSSIAN).add(" by Robert Louis Stevenson"));
document.add(new Paragraph().setFont(font)
.add(KOREAN).add(" by Robert Louis Stevenson"));
This won't work because we didn't use the correct encoding, but also because we didn't define a font that supports Russian and Korean. We fix this problem in the Czech_Russian_Korean Right example by embedding the free font "FreeSans" for the Czech and Russian translation of the title. We'll use a Hancom font "HCR Batang" for the Korean text.
public static final String FONT = "src/main/resources/fonts/FreeSans.ttf";
public static final String HCRBATANG = "src/main/resources/fonts/HANBatang.ttf";
We'll use these paths as the first parameter for the PdfFont constructor. We pass the desired encoding as the second parameter. The third parameter indicates that we want to embed the font.
PdfFont font1250 = PdfFontFactory.createFont(FONT, PdfEncodings.CP1250, true);
document.add(new Paragraph().setFont(font1250)
.add(CZECH).add(" by Robert Louis Stevenson"));
PdfFont font1251 = PdfFontFactory.createFont(FONT, "Cp1251", true);
document.add(new Paragraph().setFont(font1251)
.add(RUSSIAN).add(" by Robert Louis Stevenson"));
PdfFont fontUnicode =
PdfFontFactory.createFont(HCRBATANG, PdfEncodings.IDENTITY_H, true);
document.add(new Paragraph().setFont(fontUnicode)
.add(KOREAN).add(" by Robert Louis Stevenson"));
Figure 1.5 shows the resulting PDF.
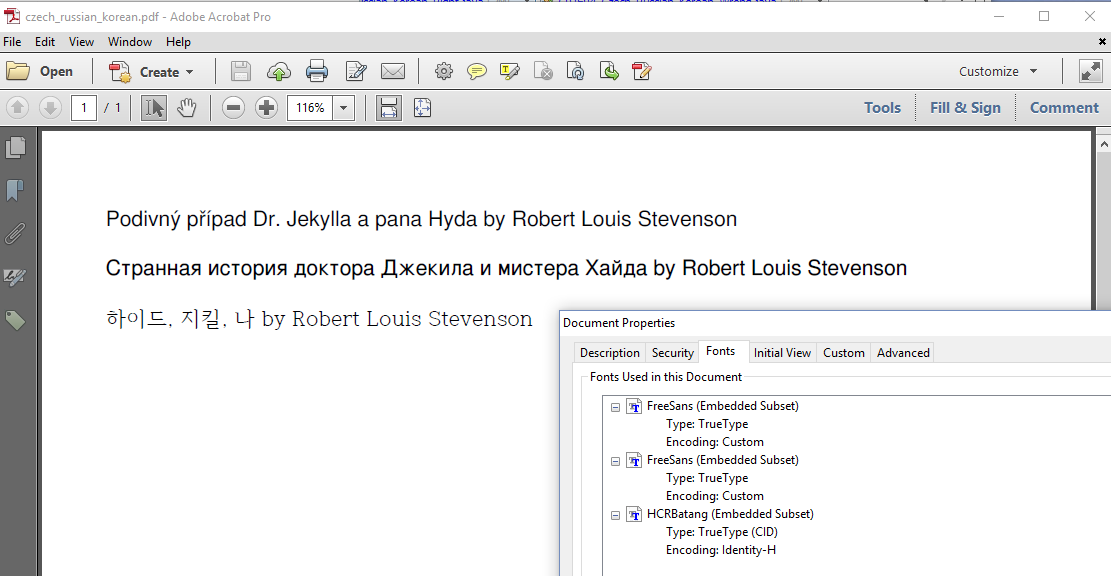
When we look at the Fonts panel in the document properties, we notice that FreeSans is mentioned twice. That is correct: we've added the font once with the encoding Cp1250 and once with the encoding Cp1251, In the Czech_Russian_Korean_Unicode example, we'll create one composite font, freeUnicode, for both languages, Czech and Russian.
PdfFont freeUnicode =
PdfFontFactory.createFont(FONT, PdfEncodings.IDENTITY_H, true);
document.add(new Paragraph().setFont(freeUnicode)
.add(CZECH).add(" by Robert Louis Stevenson"));
document.add(new Paragraph().setFont(freeUnicode)
.add(RUSSIAN).add(" by Robert Louis Stevenson"));
PdfFont fontUnicode =
PdfFontFactory.createFont(HCRBATANG, PdfEncodings.IDENTITY_H, true);
document.add(new Paragraph().setFont(fontUnicode)
.add(KOREAN).add(" by Robert Louis Stevenson"));
Figure 1.6 shows the result. The page looks identical to what we saw in figure 1.5, but now the PDF only contains one FreeSans font with Identity-H as encoding.
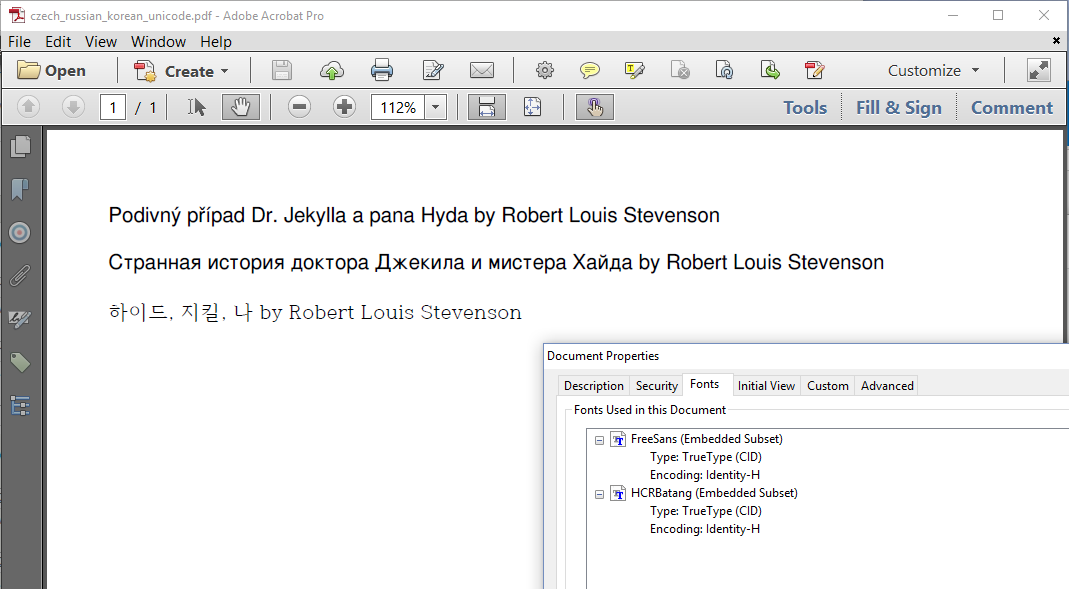
Using Unicode is one of the requirements of PDF/UA and of certain flavors of PDF/A for reasons of accessibility. With custom encodings, it isn't always possible to know which glyphs are represented by each character.
In the next series of font examples, we'll experiment with some font properties such as font size, font color, and rendering mode.
Font properties
Figure 1.7 shows a screen shot of yet another PDF with the Jekyll and Hyde title. This time, the default font Helvetica is used, but we've defined different font sizes.
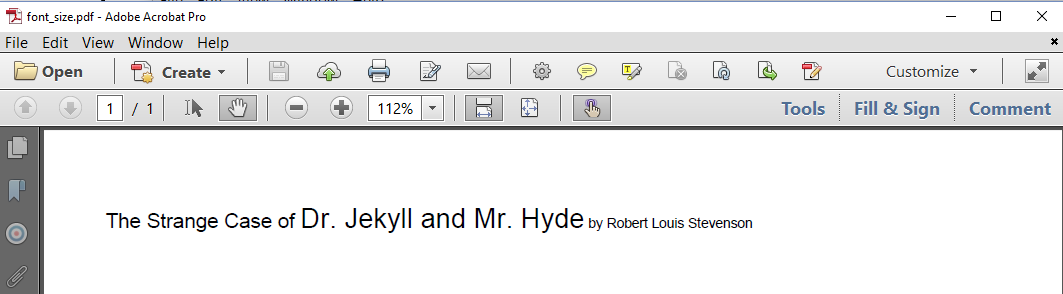
The font size is set with the setFontSize() method. This method is defined in the abstract class ElementPropertyContainer, which means that we can use it on many different objects. In the FontSize example, we use the method on Text and Paragraph objects:
Text title1 = new Text("The Strange Case of ").setFontSize(12);
Text title2 = new Text("Dr. Jekyll and Mr. Hyde").setFontSize(16);
Text author = new Text("Robert Louis Stevenson");
Paragraph p = new Paragraph().setFontSize(8)
.add(title1).add(title2).add(" by ").add(author);
document.add(p);
We set the font size of the newly created Paragraph to 8 pt. This font size will be inherited by all the objects that are added to the Paragraph, unless the objects override that default size. This is the case for title1 for which we defined a font size of 12 pt and for title2 for which we defined a font size of 16 pt. The content added as a String (" by ") and the content added as a Text object for which no font size was defined inherit the font size 8 pt from the Paragraph to which they are added.
In iText 5, it was necessary to create a different Font object if you wanted a font with a different size or color. We changed this in iText 7: you only need a single PdfFont object. The font size and color is defined at the level of the building blocks. We also made it possible for elements to inherit the font, font size, font color and other properties from the parent object.
In previous examples, we've worked with different fonts from the same family. For instance, we've created a document with three different fonts from the Cardo family: Cardo-Regular, Cardo-Bold, and Cardo-Italic. For most of the Western fonts, you'll find at least a regular font, a bold font, an italic font, and a bold-italic font. It will be more difficult to find bold, italic and bold-italic fonts for Eastern and Semitic languages. In that case, you'll have to mimic those styles as is done in figure 1.8. If you look closely, you see that different styles are used, yet we've only defined a single font in the PDF.
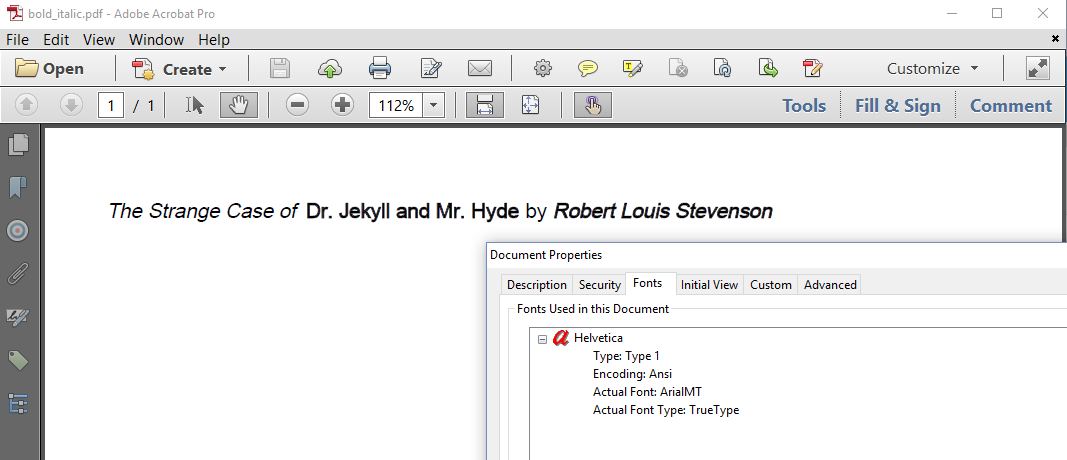
Let's take a look at the BoldItalic example to find out how this was done.
Text title1 = new Text("The Strange Case of ").setItalic();
Text title2 = new Text("Dr. Jekyll and Mr. Hyde").setBold();
Text author = new Text("Robert Louis Stevenson").setItalic().setBold();
Paragraph p = new Paragraph()
.add(title1).add(title2).add(" by ").add(author);
document.add(p);
In lines 1 to 3, we use the methods setItalic() and setBold(). The setItalic() method won't switch from a regular to an italic font. Instead, it will skew the glyphs of the italic font in such a way that it looks as if they are italic. The setBold() font will change the render mode of the text and increase the stroke width. Let's introduce some color to show what this means.
Figure 1.9 shows the text using different colors and different rendering modes.
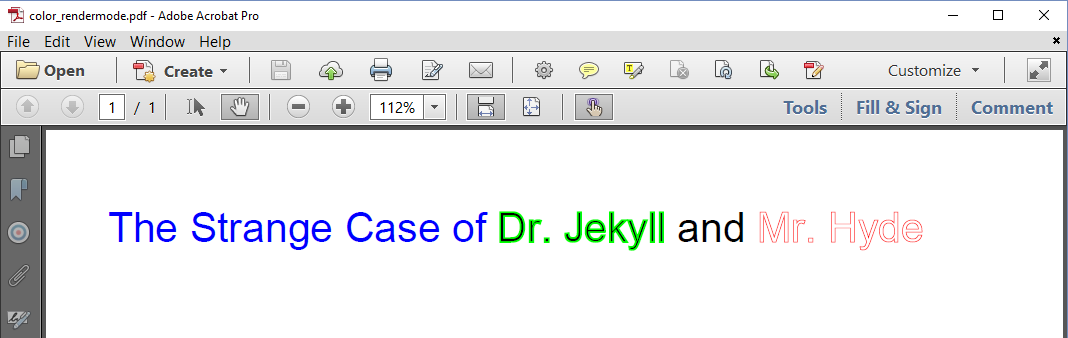
The ColorRendering example explains what happens.
Text title1 = new Text("The Strange Case of ").setFontColor(Color.BLUE);
Text title2 = new Text("Dr. Jekyll")
.setStrokeColor(Color.GREEN)
.setTextRenderingMode(PdfCanvasConstants.TextRenderingMode.FILL_STROKE);
Text title3 = new Text(" and ");
Text title4 = new Text("Mr. Hyde")
.setStrokeColor(Color.RED).setStrokeWidth(0.5f)
.setTextRenderingMode(PdfCanvasConstants.TextRenderingMode.STROKE);
Paragraph p = new Paragraph().setFontSize(24)
.add(title1).add(title2).add(title3).add(title4);
document.add(p);
A font program contains the syntax to construct the path of each glyph. By default the path is painted using a fill operator, not drawn with a stroke operation, but we can change this default.
-
In line 1, we change the font color to blue using the
setFontColor()method. This changes the fill color for the paint operation that fills the paths of all the text. -
In line 2-4, we don't define a font color, which means the text will be painted in black. Instead we define a stroke color using the
setStrokeColor()method, and we change the text rendering mode toFILL_STROKEwith thesetTextRenderingMode()method. As a result the contours of each glyph will be drawn in green. Inside those contours, we'll see the default fill color black. -
We don't change any of the defaults in line 5. This
Textobject will simply inherit the font size of theParagraph, just like all of the otherTextobjects. -
In line 6-8, we change the stroke color to red and we use the
setStrokeWidth()to 0.5 user units. By default, the stroke width is 1 user unit, which by default corresponds with 1 point. There are 72 user units in one inch by default. We also change the text rendering mode toSTROKEwhich means the text won't be filled using the default fill color. Instead, we'll only see the contours of the text.
Mimicking bold is done by setting the text rendering mode to FILL_STROKE and by increasing the stroke width; mimicking italic is done by using the setSkew() method that will be discussed in chapter 3. Although this approach works relatively well, the setBold() and setItalic() method should only be used as a last resort when it's really impossible to find the appropriate fonts for the desired styles. Mimicking styles makes it very hard - if not impossible - for parsers extracting text from PDF to detect which part of the text is rendered in a different style.
Reusing styles
If you have many different building blocks, it can become quite cumbersome to define the same style over and over again for each separate object. See for instance figure 1.10 where parts of the text - the title of a story - are written in 14 pt Times-Roman, but other parts - the names of the main characters - are written in 12 pt Courier with red text on a light gray background.
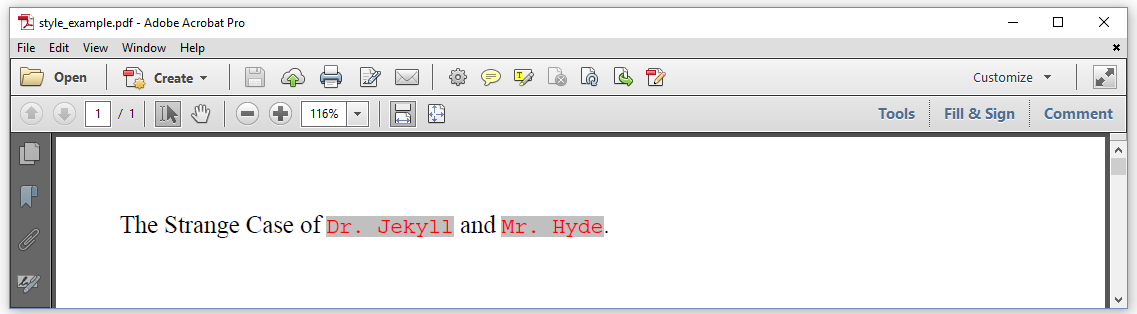
We could define the font family, font size, font color and background for each separate Text object that is added to the title Paragraph, but in the ReusingStyles example, we use the Style object to define all the different styles at once.
Style normal = new Style();
PdfFont font = PdfFontFactory.createFont(FontConstants.TIMES_ROMAN);
normal.setFont(font).setFontSize(14);
Style code = new Style();
PdfFont monospace = PdfFontFactory.createFont(FontConstants.COURIER);
code.setFont(monospace).setFontColor(Color.RED)
.setBackgroundColor(Color.LIGHT_GRAY);
Paragraph p = new Paragraph();
p.add(new Text("The Strange Case of ").addStyle(normal));
p.add(new Text("Dr. Jekyll").addStyle(code));
p.add(new Text(" and ").addStyle(normal));
p.add(new Text("Mr. Hyde").addStyle(code));
p.add(new Text(".").addStyle(normal));
document.add(p);
In line 1-3, we define a normal style; in line 4-7, we define a code style - Courier is often used when introducing code snippets in text. In line 8-13, we compose a Paragraph using different Text objects. We set the style of each of these Text objects to either normal, or code.
The Style object is a subclass of the abstract ElementPropertyContainer class, which is the superclass of all the building blocks we are going to discuss in the next handful of chapters. It contains a number of setters and getters for numerous properties such as fonts, colors, borders, dimensions, and positions. You can use the addStyle() method on every AbstractElement subclass to set these properties in one go.
Being able to combine different properties in one class, is one of the many new features in iText 7 that can save you many lines of code when compared to iText 5.
The Style class is about much more than fonts. You can even use it to define padding and margin values for BlockElement building blocks. But let's not get ahead of ourselves, the BlockElement class will be discussed in chapters 4 and 5.
Summary
In this chapter, we've introduced the PdfFont class and we talked about font programs, embedding fonts and using different encodings. This allowed us to show the title of a short story by Robert Louis Stevenson in different languages: English, Czech, Russian, and Korean. We also looked at font properties such as font size, font color, and rendering mode. We even discovered how to mimic styles in case we can't find the font program to render text in italic or bold.
There's much more that could be said about fonts, but we'll leave that for a separate tutorial. In the next chapter, we'll create a PDF with the full story while we discuss the RootElement implementations Document and Canvas.