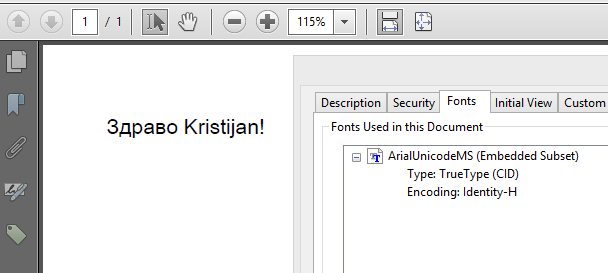
I have a problem with PDF fonts. I am generating PDF from HTML and that worked fine on my local machine, which has Windows as OS. But now I deploy my application on a Linux server and my Cyrillic text is displayed as question marks.
I have a problem with PDF fonts. I am generating PDF from HTML and that worked fine on my local machine, which has Windows as OS. But now I deploy my application on a Linux server and my Cyrillic text is displayed as question marks.
This is my code:
Document document = new Document(PageSize.A4); String myFontsDir = "C:\\"; String filePath = AppProperties.downloadLocation + "Order_" + orderID + ".pdf"; try { OutputStream file = new FileOutputStream(new File(filePath)); PdfWriter writer = PdfWriter.getInstance(document, file); int iResult = FontFactory.registerDirectory(myFontsDir); if (iResult == 0) { System.out.println("TestPDF(): Could not register font directory " + myFontsDir); } else { System.out.println("TestPDF(): Registered font directory " + myFontsDir); } document.open(); String htmlContent = "<html><head>" + "<meta http-equiv=\"content-type\" content=\"application/xhtml+xml; charset=UTF-8\"/>" + "</head><body>" + "<h4 style=\"font-family: arialuni, arial; font-size:16px; font-weight: normal; \" >" + "?????? Kristijan!" + "</h4></body></html>"; InputStream inf = new ByteArrayInputStream(htmlContent.getBytes("UTF-8")); XMLWorkerFontProvider fontImp = new XMLWorkerFontProvider(myFontsDir); FontFactory.setFontImp(fontImp); XMLWorkerHelper.getInstance().parseXHtml(writer, document, inf, null, null, fontImp); document.close(); System.out.println("Done."); } catch (Exception e) { e.printStackTrace(); }
with this piece of code, I am able to generate proper PDF documents in Latin text, but Cyrillic is displayed with weird characters. This happens on Windows, I haven't yet test it on Linux. Any advice for encoding or font?
Posted on StackOverflow on Jun 17, 2015 by chris
First this: it is very hard to believe that your font directory is C:\\. You are assuming that you have a file with path C:\\arialuni.ttf whereas I assume that the path to MS Arial Unicode is C:\\windows\fonts\arialuni.ttf. Also: make sure that the path is correct when you deploy on Linux.
Secondly: I don't think arialuni is the correct name. I'm pretty sure it's arial unicode ms. You can check this by running this code:
XMLWorkerFontProvider fontProvider = new XMLWorkerFontProvider(XMLWorkerFontProvider.DONTLOOKFORFONTS); fontProvider.register("c:/windows/fonts/arialuni.ttf"); for (String s : fontProvider.getRegisteredFamilies()) { System.out.println(s); }
The output should be:
courier arial unicode ms zapfdingbats symbol helvetica times times-roman
These are the values you can use; arialuni isn't one of them.
Also: aren't you defining the character set in the wrong place?
I have slightly adapted your source code in the sense that I stored the HTML in an HTML file:
<html> <head> <meta http-equiv="content-type" content="application/xhtml+xml; charset=UTF-8"/> </head> <body> <h4 style="font-family: Arial Unicode MS, FreeSans; font-size:16px; font-weight: normal; " >?????? Kristijan!</h4> </body> </html>
Note that I replaced arialuni with Arial Unicode MS and that I used FreeSans as an alternative font. In my code, I used FreeSans.ttf instead of arialttf.
See
public static final String DEST = "results/xmlworker/cyrillic.pdf"; public static final String HTML = "resources/xml/cyrillic.html"; public static final String FONT = "resources/fonts/FreeSans.ttf"; public void createPdf(String file) throws IOException, DocumentException { // step 1 Document document = new Document(); // step 2 PdfWriter writer = PdfWriter.getInstance(document, new FileOutputStream(file)); // step 3 document.open(); // step 4 XMLWorkerFontProvider fontImp = new XMLWorkerFontProvider(XMLWorkerFontProvider.DONTLOOKFORFONTS); fontImp.register(FONT); FontFactory.setFontImp(fontImp); XMLWorkerHelper.getInstance().parseXHtml(writer, document, new FileInputStream(HTML), null, Charset.forName("UTF-8"), fontImp); // step 5 document.close(); }
As you can see, I use the Charset when parsing the HTML. The result looks like this:
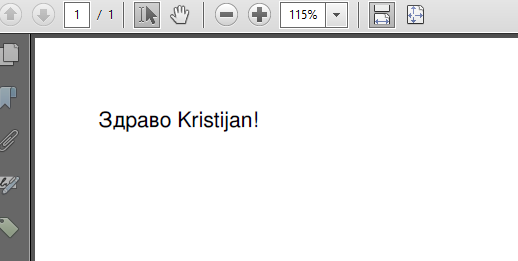
If you insist on using Arial Unicode, just replace this line:
public static final String FONT = "resources/fonts/FreeSans.ttf";
With this one:
public static final String FONT = "c:/windows/fonts/arialuni.ttf";
I have tested this on a Windows machine and it works too: