This release brings improvements for table recognition and extraction, specifically in the case of borderless tables.
To explain, by choosing automatic mode for the table selector when defining a template in the data field editor, pdf2Data can recognize and extract data from tables even if there are no border between columns to clearly delineate them. This method of automatic table detection is not perfect, however, in pdf2Data 2.1.8 we've further improved the heuristic algorithms used for this purpose to produce even better results.
Let's consider the following example, which in previous versions of pdf2Data would fail to be recognized:
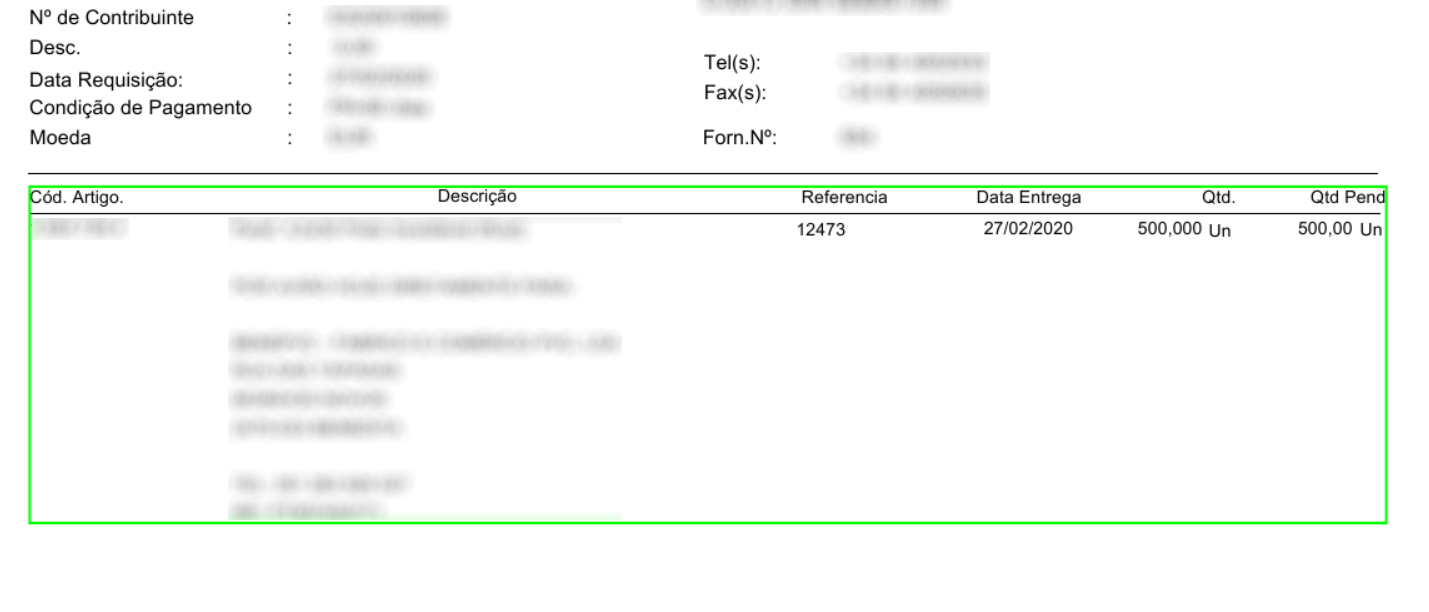
In the image above, we have an invoice using a table without any borders. Some details have been blurred for confidentiality reasons, however it still serves to illustrate our point.
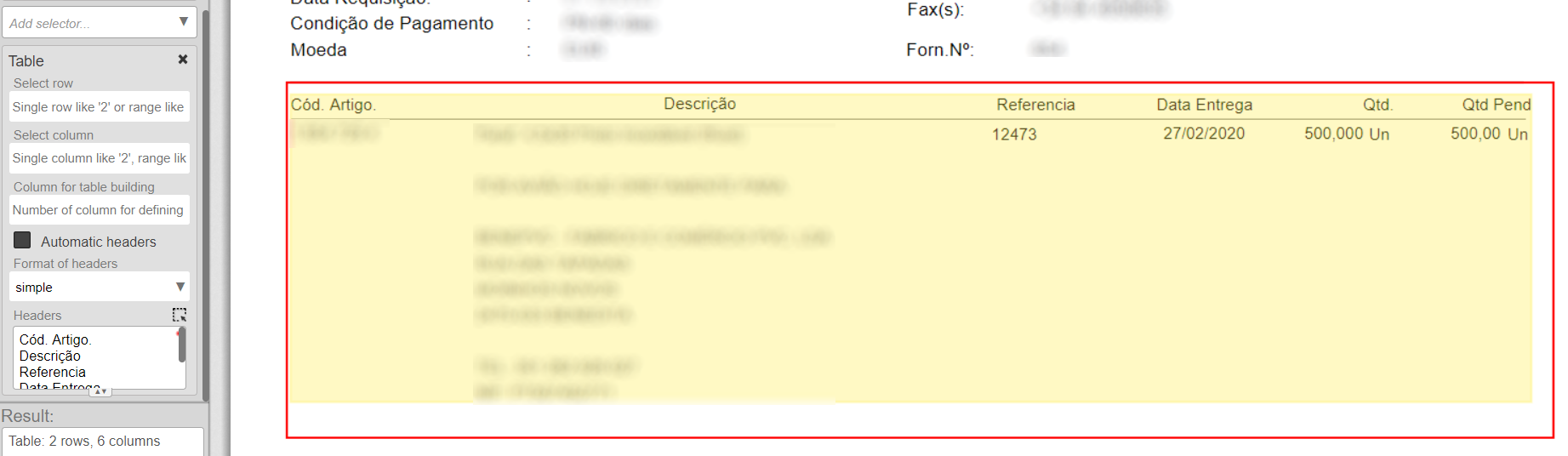
Above is the table defined in the data field editor, you can see the recognized headers displayed under "Headers". However, notice that some values are not aligned with its column header (e.g. Qtd), which could cause problems.
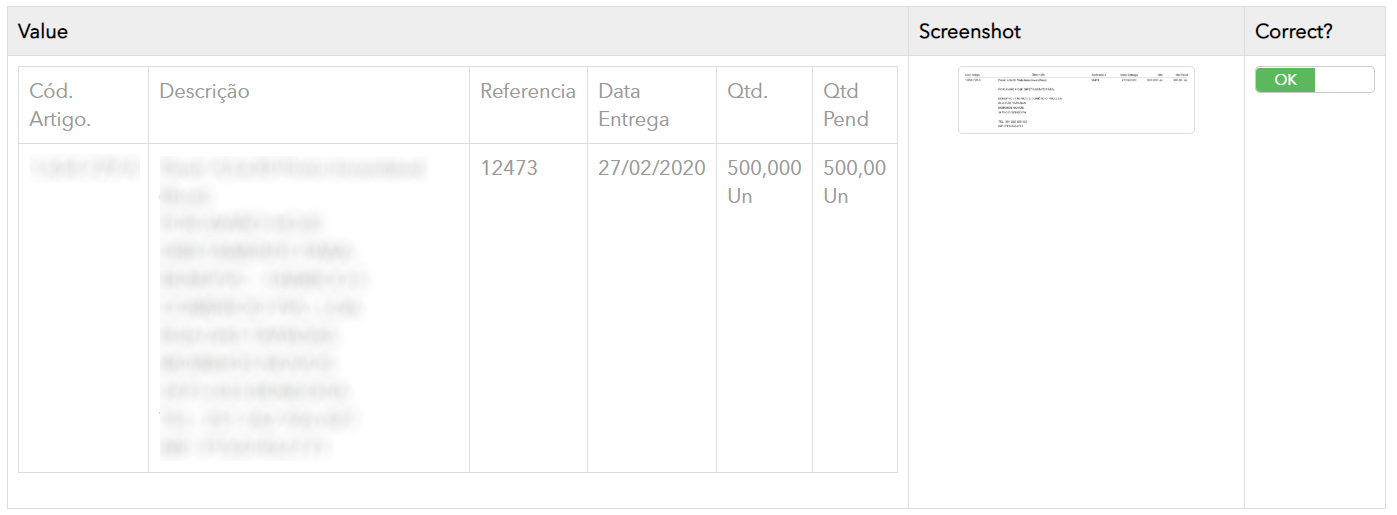
Not to worry though! Here you can see the table has been correctly recognized, with each column clearly delineated and containing the correct values for that column, even Qtd!
If you find pdf2Data useful for document data extraction, be sure to also check out pdfOCR. We think it is a great tool to use in combination with pdf2Data.
Downloads
|
|
GitHub |
Maven |
NuGet |
Artifactory |
|---|---|---|---|---|
|
iText pdf2Data – 2.1.8 ( Java API ) |
N/A |
N/A |
N/A |
link |
|
iText pdf2Data – 2.1.8 (.NET API) |
N/A |
N/A |
link |
link |
Improvements
-
Table recognition improvement
Installation Instructions