The innovative iText pdf2Data 4.0 release brings a lot of important improvements and features empowering data extraction (please see the release notes to get to know more). At the same time, to make it real we had to introduce some breaking changes, of which the new template format and the pdf2Data Manager are the most impactful for your workflows.
In this article we'll discuss these changes and how you can migrate from version 3.x to version 4.x
Template Creation with pdf2Data Manager and pdf2Data Editor
From now you can choose one of two components to create Extraction templates, either the pdf2Data Editor or pdf2Data Manager.
To install pdf2Data Manager, which already includes pdf2Data Editor we recommend using our new deployment script. See more details on it's usage here.
iText pdf2Data 4.0 doesn't support templates created in the previous versions of pdf2Data (1.*-3.*), however, those can be easily converted:
-
For pdf2Data Manager you can use the import button:
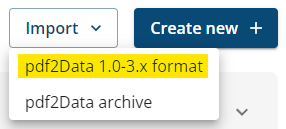
-
In pdf2Data Editor it is even easier, you can upload templates in the old format via the upload form on the start page and it will be automatically converted into the new format.
Templates can be downloaded from the pdf2Data Editor in the new format only.
PDF parsing with pdf2Data SDK
After upgrading to iText pdf2Data SDK v4.x you can continue to use the API for processing PDF with templates in the old format, but this API is deprecated and will be deleted in the next release.
Therefore, we recommend you to already start using the new template format:
Templates conversion
First of all, you need to migrate your templates.
You can also convert your template through importing into the pdf2Data Manager (as mentioned above).
Note that the template could be in two forms: unprocessed which was PDF-based in v3 and processed - XML-based in v3.
This concept is preserved in iText pdf2Data 4.0, but to make it easier to distinguish between those formats we introduced two different file types:
pd2ta - for unprocessed templates , and p2d for processed ones, The second format is used by the SDK while parsing.
Convert unprocessed templates
try (FileInputStream source = new FileInputStream(PDF_TEMPLATE_PATH)) {
Pdf2DataTemplateConverter.convertPdfV3ToP2dta(source, new File(P2DTA_TEMPLATE_PATH));
}
try (Stream source = new FileStream(PDF_TEMPLATE_PATH, FileMode.Open)) {
Pdf2DataTemplateConverter.ConvertPdfV3ToP2dta(source, new FileInfo(P2DTA_TEMPLATE_PATH));
}
Convert processed templates (XML)
try (FileInputStream source = new FileInputStream(XML_TEMPLATE_PATH)) {
Pdf2DataTemplateConverter.convertXmlV3ToP2d(source, new File(P2D_TEMPLATE_PATH));
}
try (Stream source = new FileStream(XML_TEMPLATE_PATH, FileMode.Open)) {
Pdf2DataTemplateConverter.ConvertXmlV3ToP2d(source, new FileInfo(P2D_TEMPLATE_PATH));
}
Also note that the new SDK API which is doing the actual extraction now works with processed templates only. So, in case you have source templates in the unprocessed PDF format, you will need to actually process them first. For that we have one more utility:
Process unprocessed templates
Pdf2DataTemplateConverter.convertP2dtaToP2d(new File(P2DTA_TEMPLATE_PATH), new File(P2D_TEMPLATE_PATH));
Pdf2DataTemplateConverter.ConvertP2dtaToP2d(new FileInfo(P2DTA_TEMPLATE_PATH), new FileInfo(P2D_TEMPLATE_PATH));
For performance reasons, we recommend that all the conversions are made once separately from your main production flow.
Extraction
The initialization of the Pdf2DataExtractor instance from a processed template should now be done with one function call:
Pdf2DataExtractor extractor = Pdf2DataExtractor.create(new File(P2D_TEMPLATE_PATH));
Pdf2DataExtractor extractor = Pdf2DataExtractor.Create(new FileInfo(P2D_TEMPLATE_PATH));
The rest of the API remains more or less the same, with the only note that we now recommend using File or stream objects instead of String paths as an input:
Perform extraction:
ParsingResult result = extractor.recognize(new File(P2D_TEMPLATE_PATH));
ParsingResult result = extractor.Recognize(new FileInfo(P2D_TEMPLATE_PATH));
Save to XML:
result.saveToXml(new File(RESULT_XML_PATH));
result.SaveToXml(new FileInfo(RESULT_XML_PATH));
Save to JSON:
result.saveToJson(new File(RESULT_JSON_PATH));
result.SaveToJson(new FileInfo(RESULT_JSON_PATH));
If for some reason you need a Template object (e.g. for processing grouped results programmatically) you can reach it from extractor via getter:
Template template = extractor.getTemplate();
Template template = extractor.GetTemplate();
pdf2Data CLI
Help section
help option is removed. Only the -h, and --help flags remain:
java -jar cli.jar -h
java -jar cli.jar --help
java -jar cli.jar preprocess -h
java -jar cli.jar preprocess --help
java -jar cli.jar parse -h
java -jar cli.jar parse --help
Preprocess
-
License is not needed for preprocess.
-
-t,--templateoptions replaced with-s,--sourcerespectively. The input file shall be in.p2dtaformat (unprocessed template archive). -
-x,--xmloptions replaced with-d,--destinationrespectively. The output file would be in.p2dformat (processed template archive).
java -jar cli.jar preprocess -s template.p2dta
java -jar cli.jar preprocess --source template.p2dta
java -jar cli.jar preprocess -s template.p2dta -d template.p2d
java -jar cli.jar preprocess --source template.p2dta --destination template.p2d
Parse
Template file to be passed as -t, --template argument shall be of .p2d type (processed template archive).
java -jar cli.jar parse -t template.p2d -s file_for_parsing.pdf -p recognized.pdf -x recognized.xml -j recognized.json -l license.json